 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Autoencoder Kernel Interpretation and Selection for Classification
Sep 10, 2022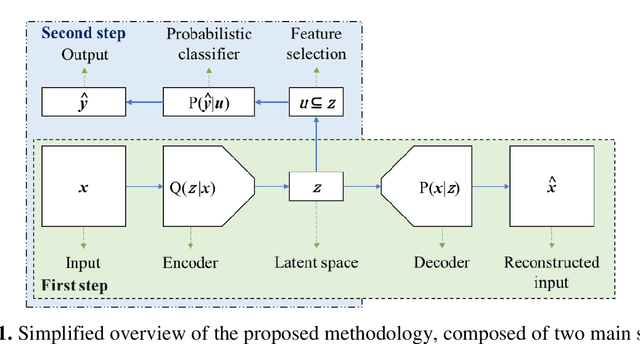
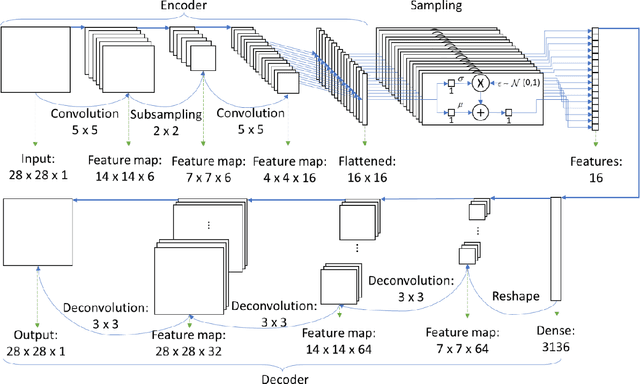
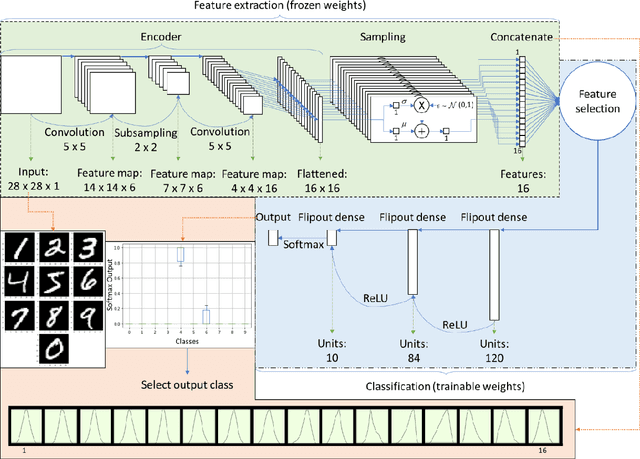
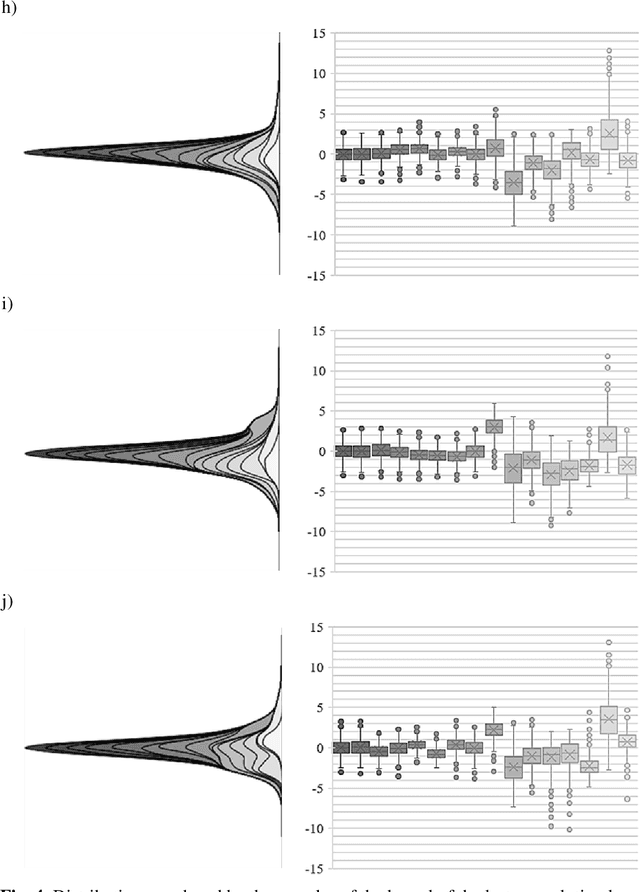
This work proposed kernel selection approaches for probabilistic classifiers based on features produced by the convolutional encoder of a variational autoencoder. Particularly, the developed methodologies allow the selection of the most relevant subset of latent variables. In the proposed implementation, each latent variable was sampled from the distribution associated with a single kernel of the last encoder's convolution layer, as an individual distribution was created for each kernel. Therefore, choosing relevant features on the sampled latent variables makes it possible to perform kernel selection, filtering the uninformative features and kernels. Such leads to a reduction in the number of the model's parameters. Both wrapper and filter methods were evaluated for feature selection. The second was of particular relevance as it is based only on the distributions of the kernels. It was assessed by measuring the Kullback-Leibler divergence between all distributions, hypothesizing that the kernels whose distributions are more similar can be discarded. This hypothesis was confirmed since it was observed that the most similar kernels do not convey relevant information and can be removed. As a result, the proposed methodology is suitable for developing applications for resource-constrained devices.
ProBoost: a Boosting Method for Probabilistic Classifiers
Sep 04, 2022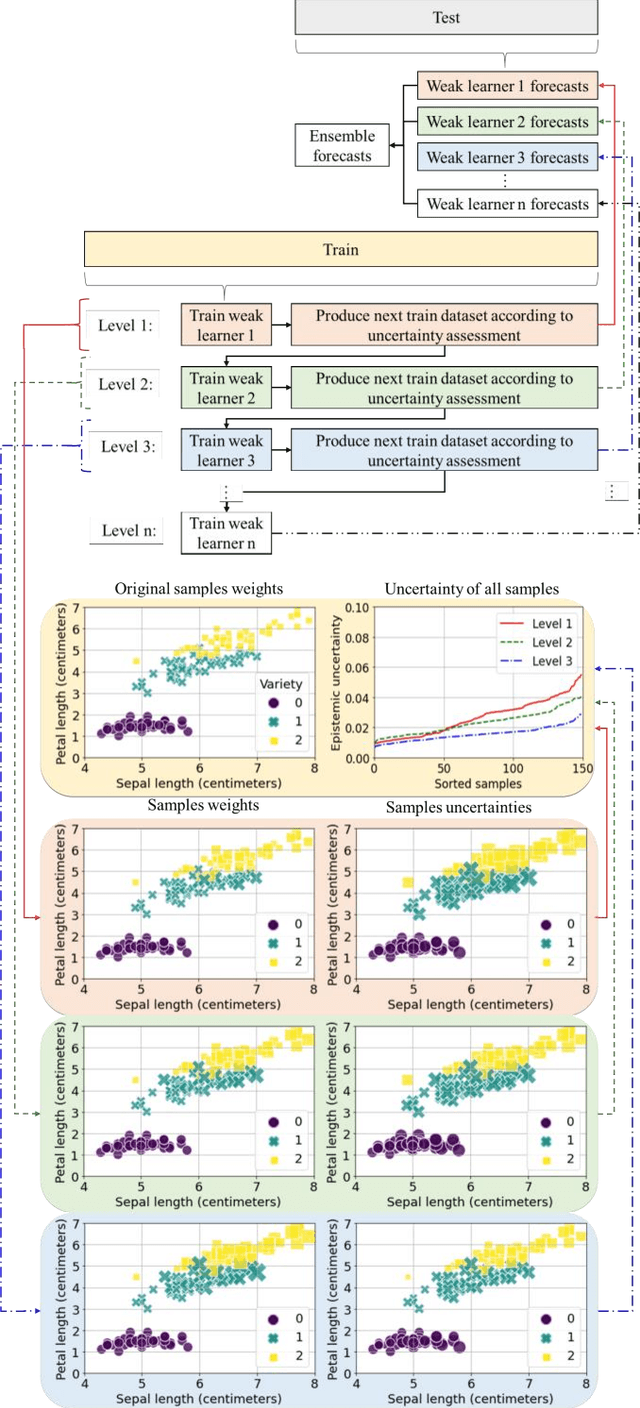
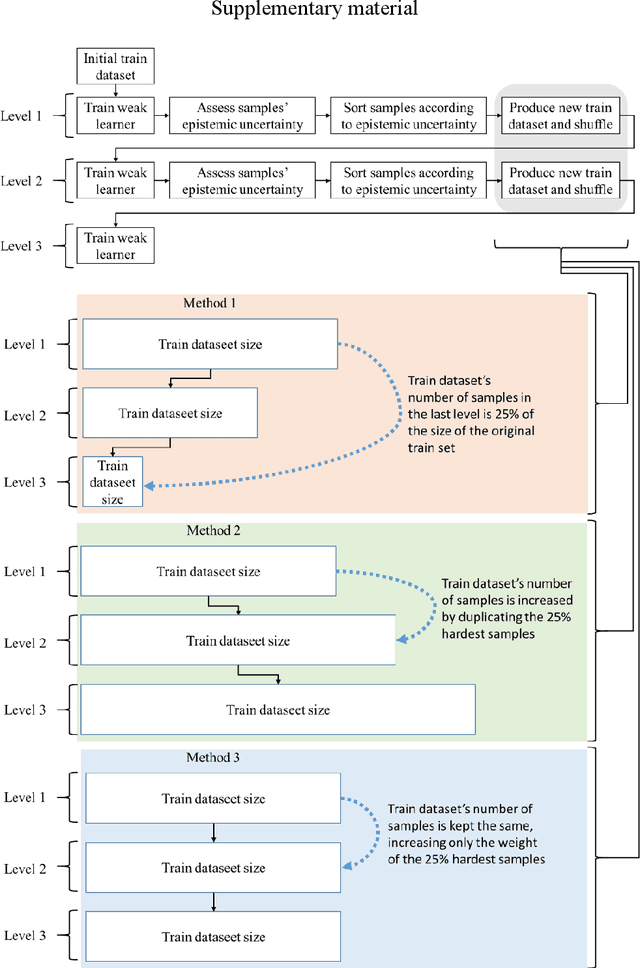
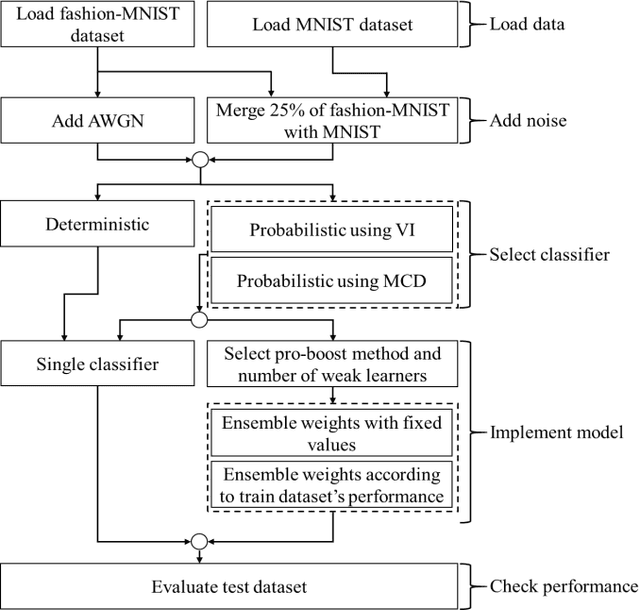
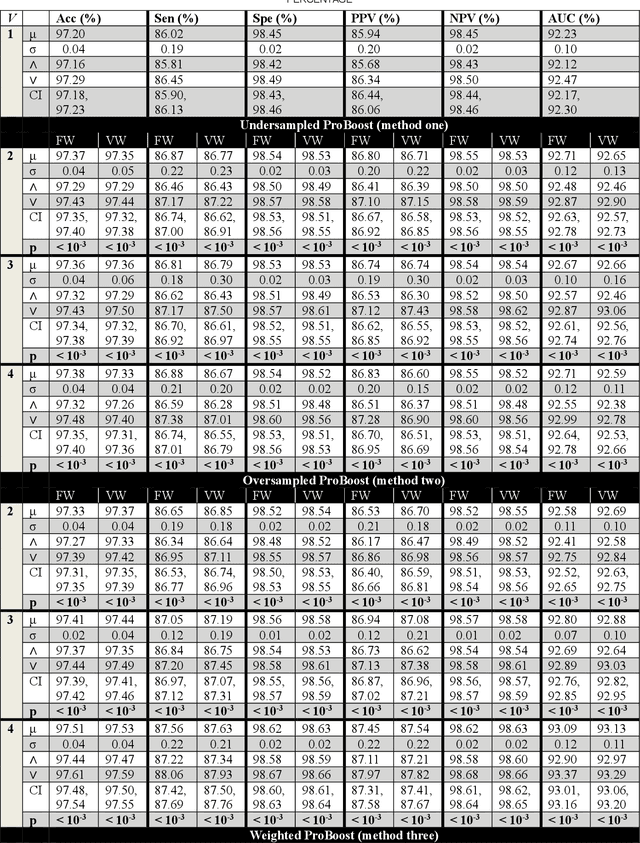
ProBoost, a new boosting algorithm for probabilistic classifiers, is proposed in this work. This algorithm uses the epistemic uncertainty of each training sample to determine the most challenging/uncertain ones; the relevance of these samples is then increased for the next weak learner, producing a sequence that progressively focuses on the samples found to have the highest uncertainty. In the end, the weak learners' outputs are combined into a weighted ensemble of classifiers. Three methods are proposed to manipulate the training set: undersampling, oversampling, and weighting the training samples according to the uncertainty estimated by the weak learners. Furthermore, two approaches are studied regarding the ensemble combination. The weak learner herein considered is a standard convolutional neural network, and the probabilistic models underlying the uncertainty estimation use either variational inference or Monte Carlo dropout. The experimental evaluation carried out on MNIST benchmark datasets shows that ProBoost yields a significant performance improvement. The results are further highlighted by assessing the relative achievable improvement, a metric proposed in this work, which shows that a model with only four weak learners leads to an improvement exceeding 12% in this metric (for either accuracy, sensitivity, or specificity), in comparison to the model learned without ProBoost.
Multiple Time Series Fusion Based on LSTM An Application to CAP A Phase Classification Using EEG
Dec 18, 2021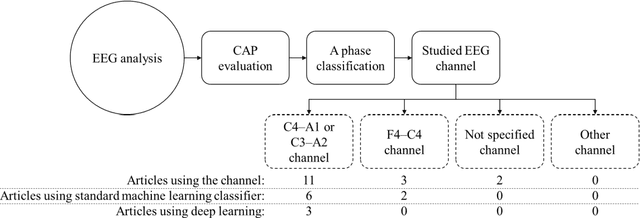

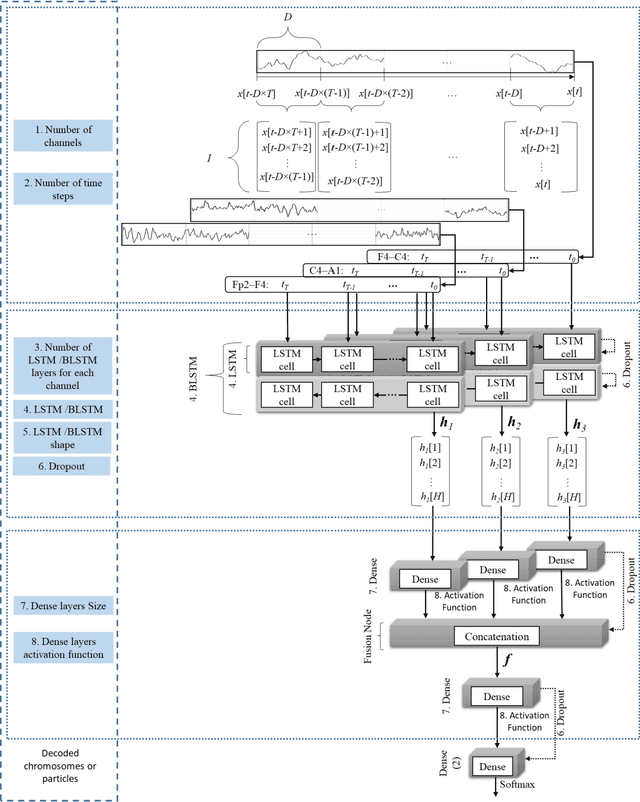

Biomedical decision making involves multiple signal processing, either from different sensors or from different channels. In both cases, information fusion plays a significant role. A deep learning based electroencephalogram channels' feature level fusion is carried out in this work for the electroencephalogram cyclic alternating pattern A phase classification. Channel selection, fusion, and classification procedures were optimized by two optimization algorithms, namely, Genetic Algorithm and Particle Swarm Optimization. The developed methodologies were evaluated by fusing the information from multiple electroencephalogram channels for patients with nocturnal frontal lobe epilepsy and patients without any neurological disorder, which was significantly more challenging when compared to other state of the art works. Results showed that both optimization algorithms selected a comparable structure with similar feature level fusion, consisting of three electroencephalogram channels, which is in line with the CAP protocol to ensure multiple channels' arousals for CAP detection. Moreover, the two optimized models reached an area under the receiver operating characteristic curve of 0.82, with average accuracy ranging from 77% to 79%, a result which is in the upper range of the specialist agreement. The proposed approach is still in the upper range of the best state of the art works despite a difficult dataset, and has the advantage of providing a fully automatic analysis without requiring any manual procedure. Ultimately, the models revealed to be noise resistant and resilient to multiple channel loss.