 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Autoencoder Kernel Interpretation and Selection for Classification
Paper and Code
Sep 10, 2022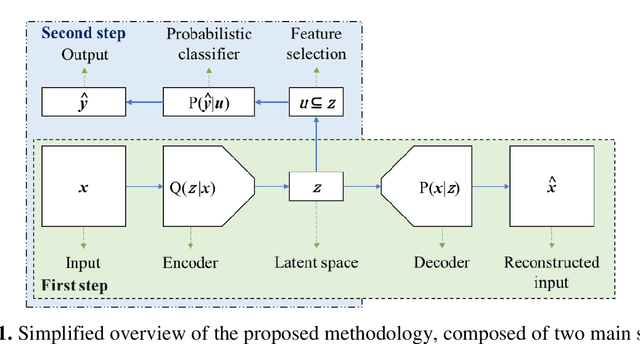
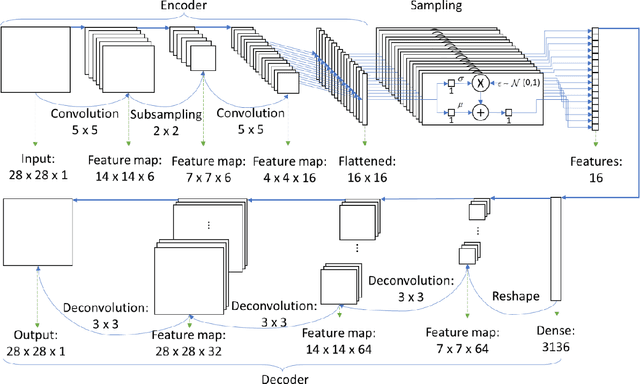
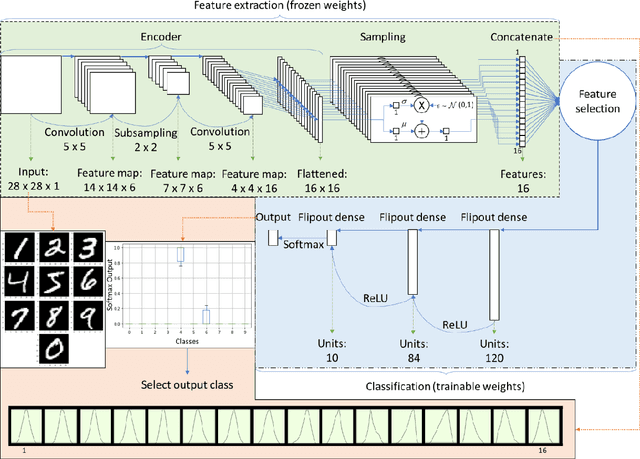
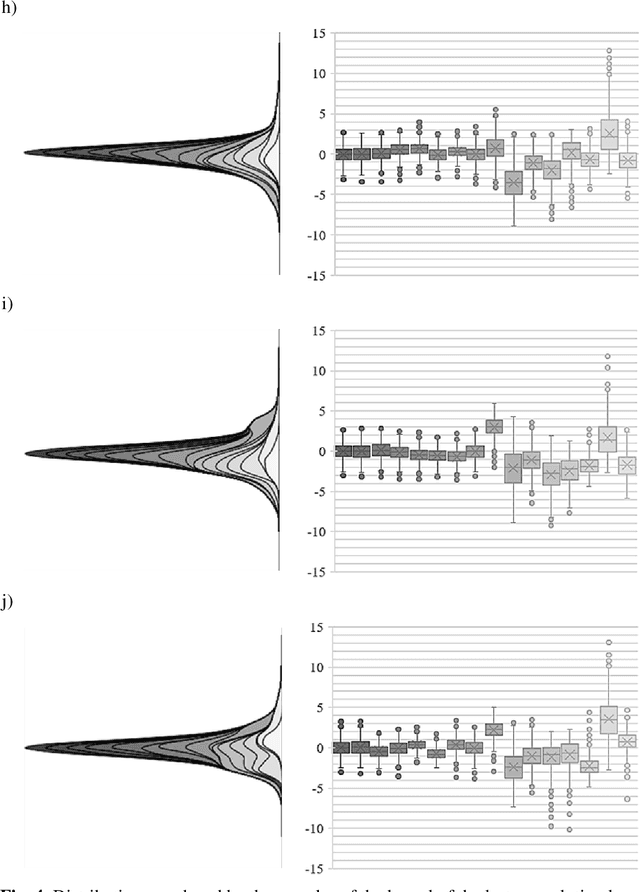
This work proposed kernel selection approaches for probabilistic classifiers based on features produced by the convolutional encoder of a variational autoencoder. Particularly, the developed methodologies allow the selection of the most relevant subset of latent variables. In the proposed implementation, each latent variable was sampled from the distribution associated with a single kernel of the last encoder's convolution layer, as an individual distribution was created for each kernel. Therefore, choosing relevant features on the sampled latent variables makes it possible to perform kernel selection, filtering the uninformative features and kernels. Such leads to a reduction in the number of the model's parameters. Both wrapper and filter methods were evaluated for feature selection. The second was of particular relevance as it is based only on the distributions of the kernels. It was assessed by measuring the Kullback-Leibler divergence between all distributions, hypothesizing that the kernels whose distributions are more similar can be discarded. This hypothesis was confirmed since it was observed that the most similar kernels do not convey relevant information and can be removed. As a result, the proposed methodology is suitable for developing applications for resource-constrained devices.