 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Sensitive Learning to Defer to Multiple Experts with Workload Constraints
Mar 21, 2024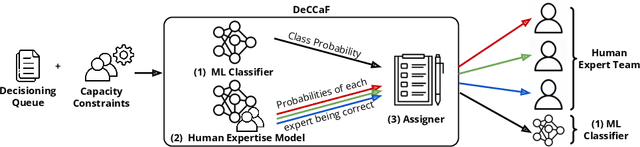
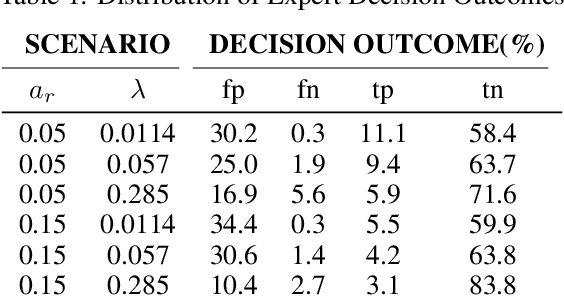
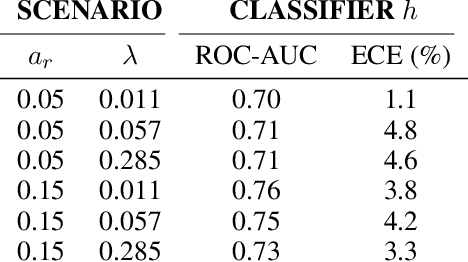
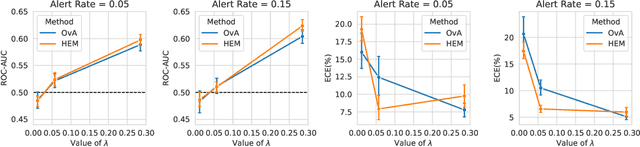
Learning to defer (L2D) aims to improve human-AI collaboration systems by learning how to defer decisions to humans when they are more likely to be correct than an ML classifier. Existing research in L2D overlooks key aspects of real-world systems that impede its practical adoption, namely: i) neglecting cost-sensitive scenarios, where type 1 and type 2 errors have different costs; ii) requiring concurrent human predictions for every instance of the training dataset and iii) not dealing with human work capacity constraints. To address these issues, we propose the deferral under cost and capacity constraints framework (DeCCaF). DeCCaF is a novel L2D approach, employing supervised learning to model the probability of human error under less restrictive data requirements (only one expert prediction per instance) and using constraint programming to globally minimize the error cost subject to workload limitations. We test DeCCaF in a series of cost-sensitive fraud detection scenarios with different teams of 9 synthetic fraud analysts, with individual work capacity constraints. The results demonstrate that our approach performs significantly better than the baselines in a wide array of scenarios, achieving an average 8.4% reduction in the misclassification cost.
FiFAR: A Fraud Detection Dataset for Learning to Defer
Dec 20, 2023Public dataset limitations have significantly hindered the development and benchmarking of learning to defer (L2D) algorithms, which aim to optimally combine human and AI capabilities in hybrid decision-making systems. In such systems, human availability and domain-specific concerns introduce difficulties, while obtaining human predictions for training and evaluation is costly. Financial fraud detection is a high-stakes setting where algorithms and human experts often work in tandem; however, there are no publicly available datasets for L2D concerning this important application of human-AI teaming. To fill this gap in L2D research, we introduce the Financial Fraud Alert Review Dataset (FiFAR), a synthetic bank account fraud detection dataset, containing the predictions of a team of 50 highly complex and varied synthetic fraud analysts, with varied bias and feature dependence. We also provide a realistic definition of human work capacity constraints, an aspect of L2D systems that is often overlooked, allowing for extensive testing of assignment systems under real-world conditions. We use our dataset to develop a capacity-aware L2D method and rejection learning approach under realistic data availability conditions, and benchmark these baselines under an array of 300 distinct testing scenarios. We believe that this dataset will serve as a pivotal instrument in facilitating a systematic, rigorous, reproducible, and transparent evaluation and comparison of L2D methods, thereby fostering the development of more synergistic human-AI collaboration in decision-making systems. The public dataset and detailed synthetic expert information are available at: https://github.com/feedzai/fifar-dataset
Adversarial training for tabular data with attack propagation
Jul 28, 2023Adversarial attacks are a major concern in security-centered applications, where malicious actors continuously try to mislead Machine Learning (ML) models into wrongly classifying fraudulent activity as legitimate, whereas system maintainers try to stop them. Adversarially training ML models that are robust against such attacks can prevent business losses and reduce the work load of system maintainers. In such applications data is often tabular and the space available for attackers to manipulate undergoes complex feature engineering transformations, to provide useful signals for model training, to a space attackers cannot access. Thus, we propose a new form of adversarial training where attacks are propagated between the two spaces in the training loop. We then test this method empirically on a real world dataset in the domain of credit card fraud detection. We show that our method can prevent about 30% performance drops under moderate attacks and is essential under very aggressive attacks, with a trade-off loss in performance under no attacks smaller than 7%.
Lightweight Automated Feature Monitoring for Data Streams
Jul 19, 2022
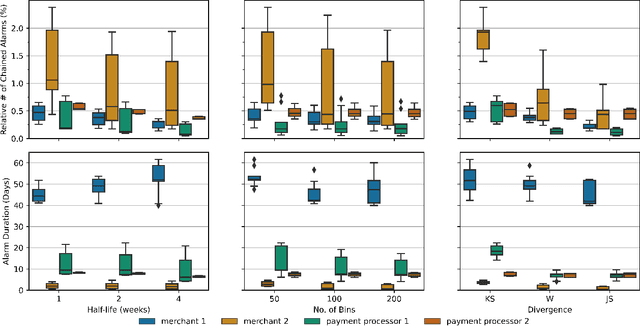
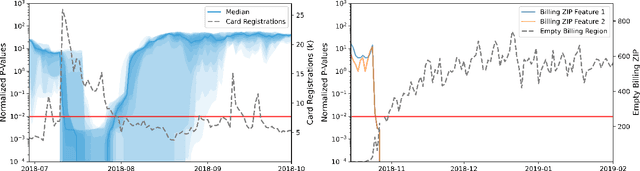
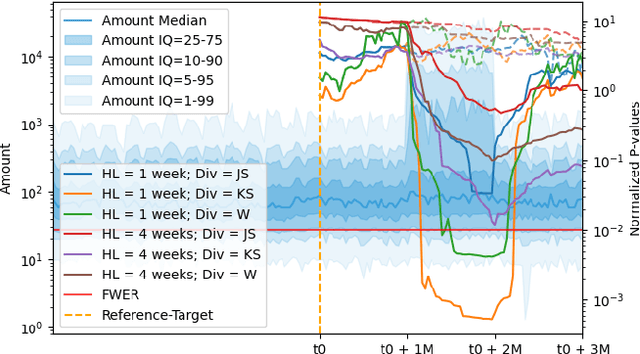
Monitoring the behavior of automated real-time stream processing systems has become one of the most relevant problems in real world applications. Such systems have grown in complexity relying heavily on high dimensional input data, and data hungry Machine Learning (ML) algorithms. We propose a flexible system, Feature Monitoring (FM), that detects data drifts in such data sets, with a small and constant memory footprint and a small computational cost in streaming applications. The method is based on a multi-variate statistical test and is data driven by design (full reference distributions are estimated from the data). It monitors all features that are used by the system, while providing an interpretable features ranking whenever an alarm occurs (to aid in root cause analysis). The computational and memory lightness of the system results from the use of Exponential Moving Histograms. In our experimental study, we analyze the system's behavior with its parameters and, more importantly, show examples where it detects problems that are not directly related to a single feature. This illustrates how FM eliminates the need to add custom signals to detect specific types of problems and that monitoring the available space of features is often enough.
Active learning for online training in imbalanced data streams under cold start
Jul 16, 2021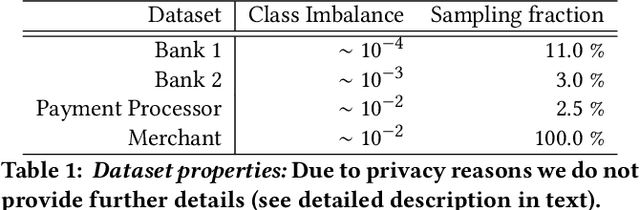
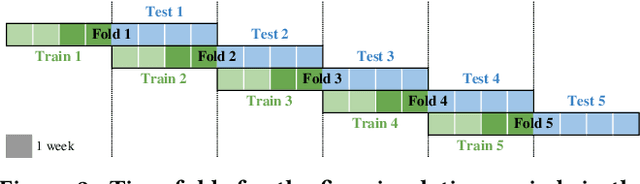
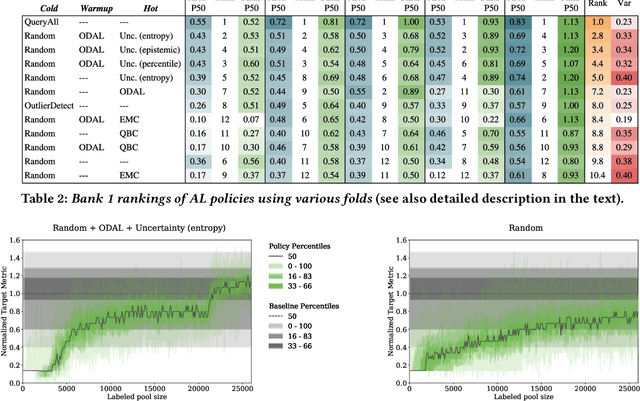
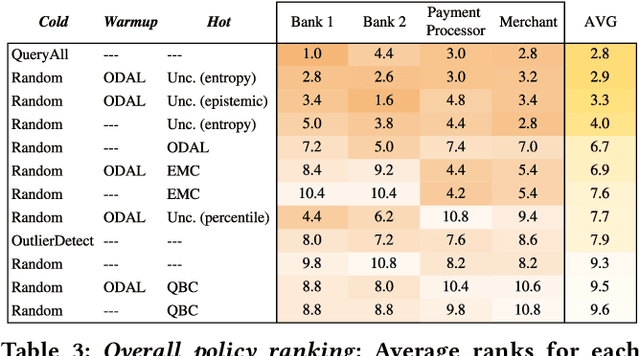
Labeled data is essential in modern systems that rely on Machine Learning (ML) for predictive modelling. Such systems may suffer from the cold-start problem: supervised models work well but, initially, there are no labels, which are costly or slow to obtain. This problem is even worse in imbalanced data scenarios. Online financial fraud detection is an example where labeling is: i) expensive, or ii) it suffers from long delays, if relying on victims filing complaints. The latter may not be viable if a model has to be in place immediately, so an option is to ask analysts to label events while minimizing the number of annotations to control costs. We propose an Active Learning (AL) annotation system for datasets with orders of magnitude of class imbalance, in a cold start streaming scenario. We present a computationally efficient Outlier-based Discriminative AL approach (ODAL) and design a novel 3-stage sequence of AL labeling policies where it is used as warm-up. Then, we perform empirical studies in four real world datasets, with various magnitudes of class imbalance. The results show that our method can more quickly reach a high performance model than standard AL policies. Its observed gains over random sampling can reach 80% and be competitive with policies with an unlimited annotation budget or additional historical data (with 1/10 to 1/50 of the labels).
Automatic Model Monitoring for Data Streams
Aug 12, 2019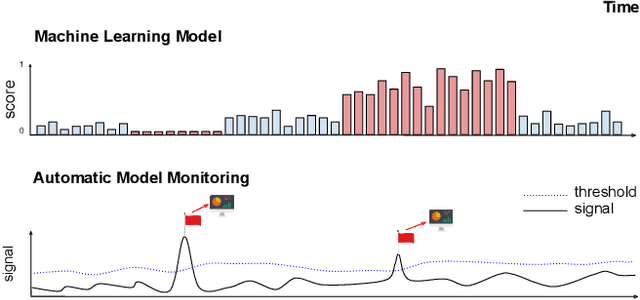

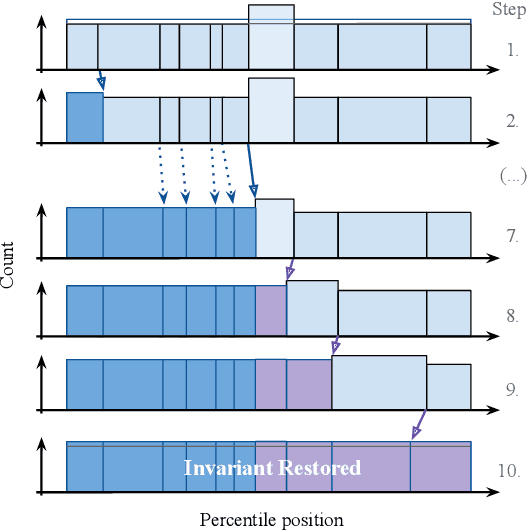
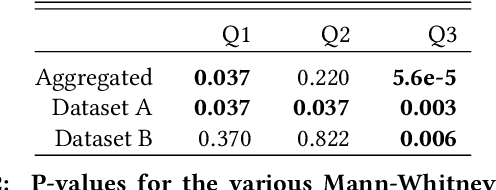
Detecting concept drift is a well known problem that affects production systems. However, two important issues that are frequently not addressed in the literature are 1) the detection of drift when the labels are not immediately available; and 2) the automatic generation of explanations to identify possible causes for the drift. For example, a fraud detection model in online payments could show a drift due to a hot sale item (with an increase in false positives) or due to a true fraud attack (with an increase in false negatives) before labels are available. In this paper we propose SAMM, an automatic model monitoring system for data streams. SAMM detects concept drift using a time and space efficient unsupervised streaming algorithm and it generates alarm reports with a summary of the events and features that are important to explain it. SAMM was evaluated in five real world fraud detection datasets, each spanning periods up to eight months and totaling more than 22 million online transactions. We evaluated SAMM using human feedback from domain experts, by sending them 100 reports generated by the system. Our results show that SAMM is able to detect anomalous events in a model life cycle that are considered useful by the domain experts. Given these results, SAMM will be rolled out in a next version of Feedzai's Fraud Detection solution.
* 9 pages, 9 figures, 2 tables