 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive learning for online training in imbalanced data streams under cold start
Jul 16, 2021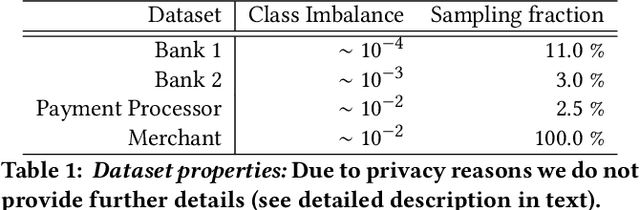
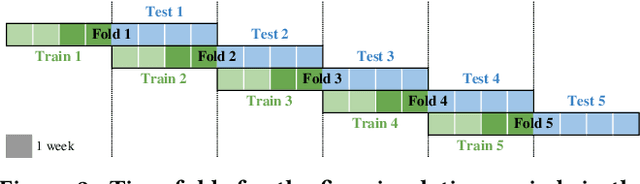
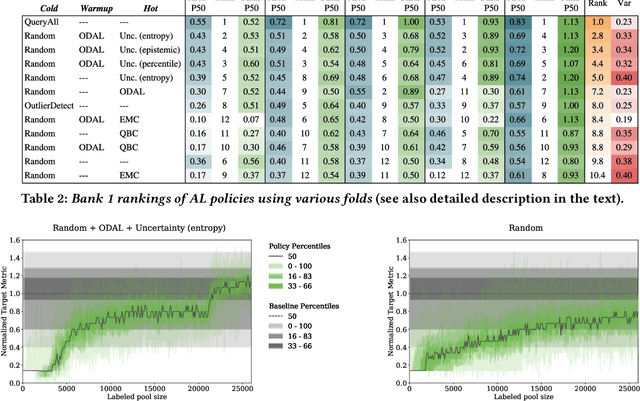
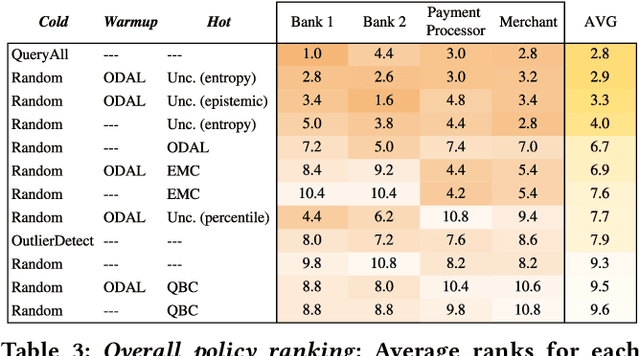
Labeled data is essential in modern systems that rely on Machine Learning (ML) for predictive modelling. Such systems may suffer from the cold-start problem: supervised models work well but, initially, there are no labels, which are costly or slow to obtain. This problem is even worse in imbalanced data scenarios. Online financial fraud detection is an example where labeling is: i) expensive, or ii) it suffers from long delays, if relying on victims filing complaints. The latter may not be viable if a model has to be in place immediately, so an option is to ask analysts to label events while minimizing the number of annotations to control costs. We propose an Active Learning (AL) annotation system for datasets with orders of magnitude of class imbalance, in a cold start streaming scenario. We present a computationally efficient Outlier-based Discriminative AL approach (ODAL) and design a novel 3-stage sequence of AL labeling policies where it is used as warm-up. Then, we perform empirical studies in four real world datasets, with various magnitudes of class imbalance. The results show that our method can more quickly reach a high performance model than standard AL policies. Its observed gains over random sampling can reach 80% and be competitive with policies with an unlimited annotation budget or additional historical data (with 1/10 to 1/50 of the labels).
ARMS: Automated rules management system for fraud detection
Feb 14, 2020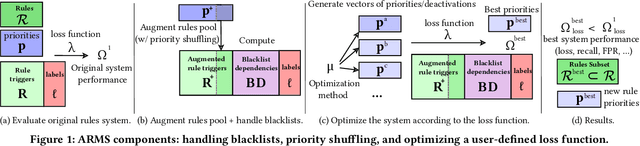
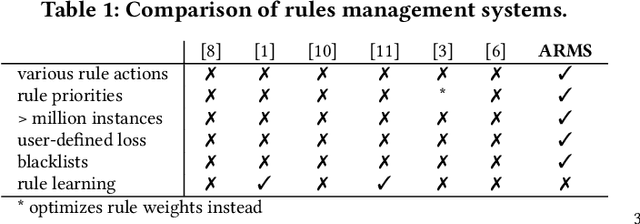
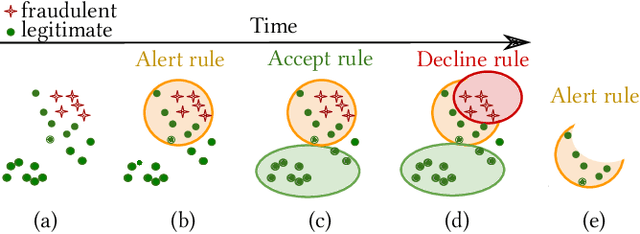
Fraud detection is essential in financial services, with the potential of greatly reducing criminal activities and saving considerable resources for businesses and customers. We address online fraud detection, which consists of classifying incoming transactions as either legitimate or fraudulent in real-time. Modern fraud detection systems consist of a machine learning model and rules defined by human experts. Often, the rules performance degrades over time due to concept drift, especially of adversarial nature. Furthermore, they can be costly to maintain, either because they are computationally expensive or because they send transactions for manual review. We propose ARMS, an automated rules management system that evaluates the contribution of individual rules and optimizes the set of active rules using heuristic search and a user-defined loss-function. It complies with critical domain-specific requirements, such as handling different actions (e.g., accept, alert, and decline), priorities, blacklists, and large datasets (i.e., hundreds of rules and millions of transactions). We use ARMS to optimize the rule-based systems of two real-world clients. Results show that it can maintain the original systems' performance (e.g., recall, or false-positive rate) using only a fraction of the original rules (~ 50% in one case, and ~ 20% in the other).