 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive learning for online training in imbalanced data streams under cold start
Paper and Code
Jul 16, 2021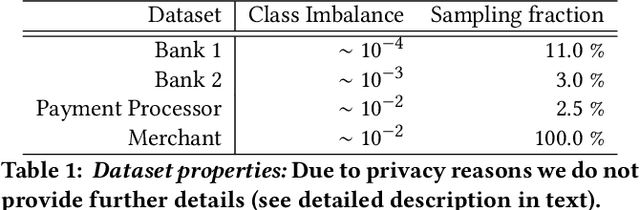
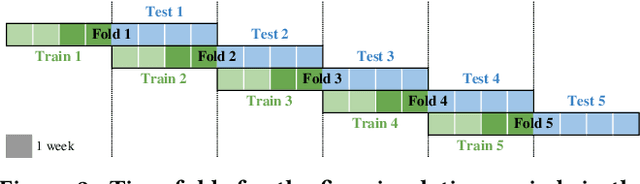
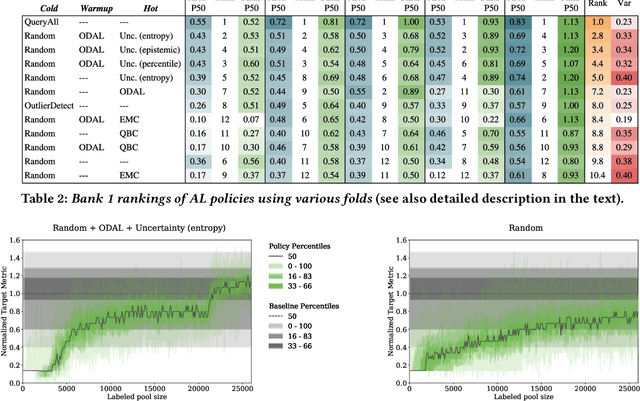
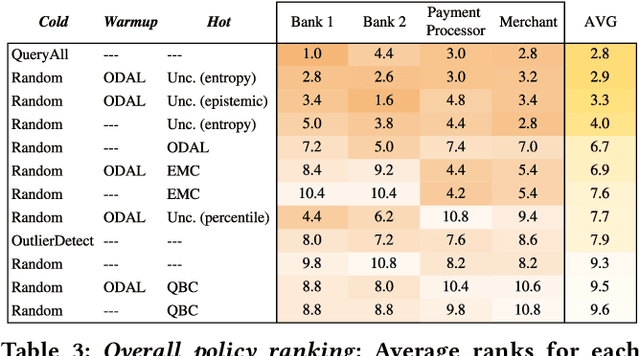
Labeled data is essential in modern systems that rely on Machine Learning (ML) for predictive modelling. Such systems may suffer from the cold-start problem: supervised models work well but, initially, there are no labels, which are costly or slow to obtain. This problem is even worse in imbalanced data scenarios. Online financial fraud detection is an example where labeling is: i) expensive, or ii) it suffers from long delays, if relying on victims filing complaints. The latter may not be viable if a model has to be in place immediately, so an option is to ask analysts to label events while minimizing the number of annotations to control costs. We propose an Active Learning (AL) annotation system for datasets with orders of magnitude of class imbalance, in a cold start streaming scenario. We present a computationally efficient Outlier-based Discriminative AL approach (ODAL) and design a novel 3-stage sequence of AL labeling policies where it is used as warm-up. Then, we perform empirical studies in four real world datasets, with various magnitudes of class imbalance. The results show that our method can more quickly reach a high performance model than standard AL policies. Its observed gains over random sampling can reach 80% and be competitive with policies with an unlimited annotation budget or additional historical data (with 1/10 to 1/50 of the labels).