 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial training for tabular data with attack propagation
Jul 28, 2023Adversarial attacks are a major concern in security-centered applications, where malicious actors continuously try to mislead Machine Learning (ML) models into wrongly classifying fraudulent activity as legitimate, whereas system maintainers try to stop them. Adversarially training ML models that are robust against such attacks can prevent business losses and reduce the work load of system maintainers. In such applications data is often tabular and the space available for attackers to manipulate undergoes complex feature engineering transformations, to provide useful signals for model training, to a space attackers cannot access. Thus, we propose a new form of adversarial training where attacks are propagated between the two spaces in the training loop. We then test this method empirically on a real world dataset in the domain of credit card fraud detection. We show that our method can prevent about 30% performance drops under moderate attacks and is essential under very aggressive attacks, with a trade-off loss in performance under no attacks smaller than 7%.
The GANfather: Controllable generation of malicious activity to improve defence systems
Jul 25, 2023
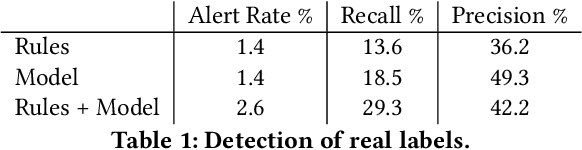
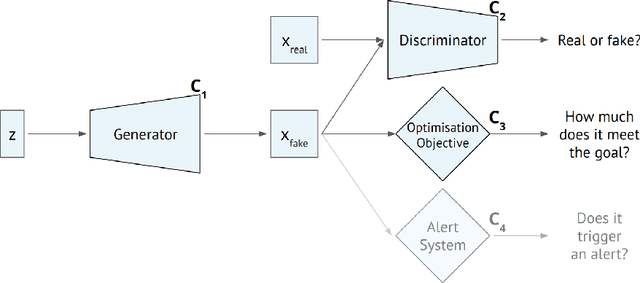
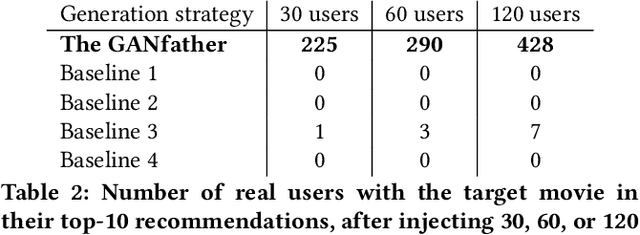
Machine learning methods to aid defence systems in detecting malicious activity typically rely on labelled data. In some domains, such labelled data is unavailable or incomplete. In practice this can lead to low detection rates and high false positive rates, which characterise for example anti-money laundering systems. In fact, it is estimated that 1.7--4 trillion euros are laundered annually and go undetected. We propose The GANfather, a method to generate samples with properties of malicious activity, without label requirements. We propose to reward the generation of malicious samples by introducing an extra objective to the typical Generative Adversarial Networks (GANs) loss. Ultimately, our goal is to enhance the detection of illicit activity using the discriminator network as a novel and robust defence system. Optionally, we may encourage the generator to bypass pre-existing detection systems. This setup then reveals defensive weaknesses for the discriminator to correct. We evaluate our method in two real-world use cases, money laundering and recommendation systems. In the former, our method moves cumulative amounts close to 350 thousand dollars through a network of accounts without being detected by an existing system. In the latter, we recommend the target item to a broad user base with as few as 30 synthetic attackers. In both cases, we train a new defence system to capture the synthetic attacks.
Lightweight Automated Feature Monitoring for Data Streams
Jul 19, 2022
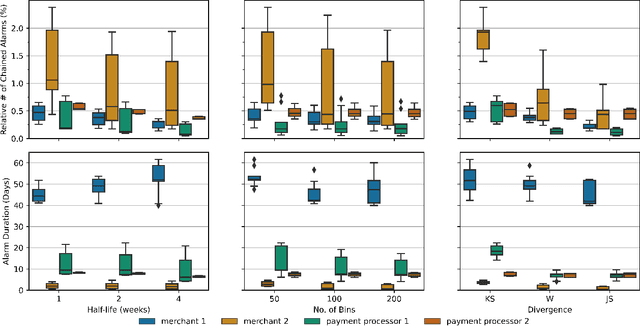
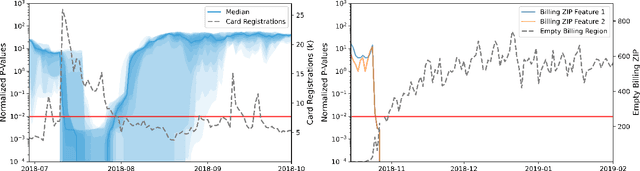
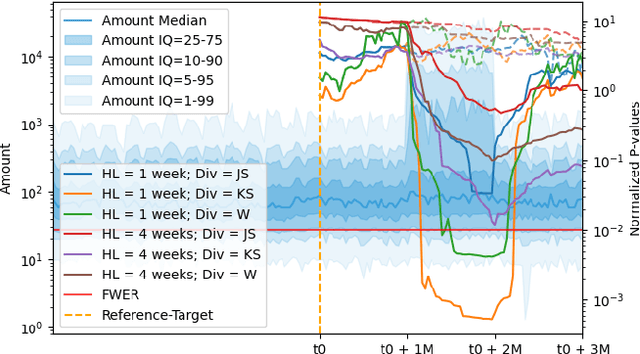
Monitoring the behavior of automated real-time stream processing systems has become one of the most relevant problems in real world applications. Such systems have grown in complexity relying heavily on high dimensional input data, and data hungry Machine Learning (ML) algorithms. We propose a flexible system, Feature Monitoring (FM), that detects data drifts in such data sets, with a small and constant memory footprint and a small computational cost in streaming applications. The method is based on a multi-variate statistical test and is data driven by design (full reference distributions are estimated from the data). It monitors all features that are used by the system, while providing an interpretable features ranking whenever an alarm occurs (to aid in root cause analysis). The computational and memory lightness of the system results from the use of Exponential Moving Histograms. In our experimental study, we analyze the system's behavior with its parameters and, more importantly, show examples where it detects problems that are not directly related to a single feature. This illustrates how FM eliminates the need to add custom signals to detect specific types of problems and that monitoring the available space of features is often enough.
Anti-Money Laundering Alert Optimization Using Machine Learning with Graphs
Dec 14, 2021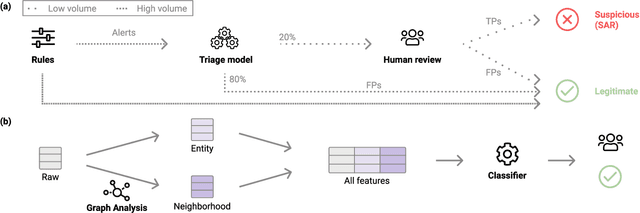
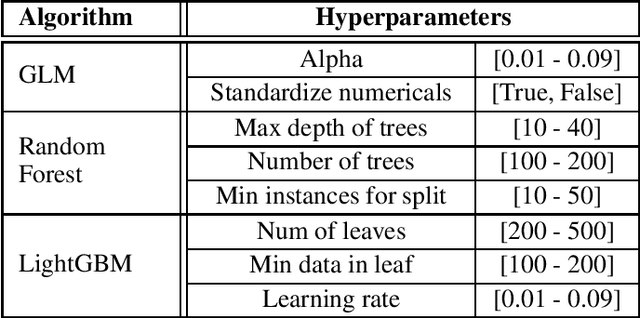

Money laundering is a global problem that concerns legitimizing proceeds from serious felonies (1.7-4 trillion euros annually) such as drug dealing, human trafficking, or corruption. The anti-money laundering systems deployed by financial institutions typically comprise rules aligned with regulatory frameworks. Human investigators review the alerts and report suspicious cases. Such systems suffer from high false-positive rates, undermining their effectiveness and resulting in high operational costs. We propose a machine learning triage model, which complements the rule-based system and learns to predict the risk of an alert accurately. Our model uses both entity-centric engineered features and attributes characterizing inter-entity relations in the form of graph-based features. We leverage time windows to construct the dynamic graph, optimizing for time and space efficiency. We validate our model on a real-world banking dataset and show how the triage model can reduce the number of false positives by 80% while detecting over 90% of true positives. In this way, our model can significantly improve anti-money laundering operations.
Active learning for online training in imbalanced data streams under cold start
Jul 16, 2021
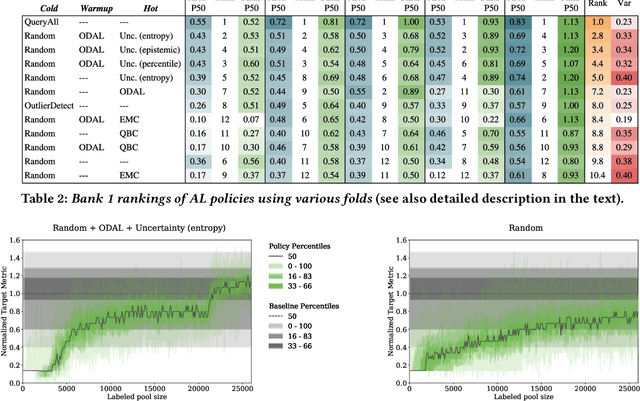
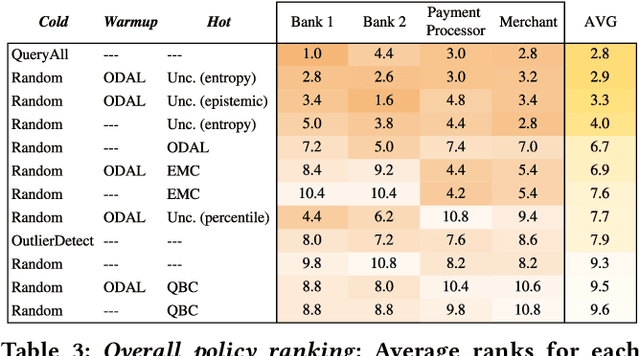
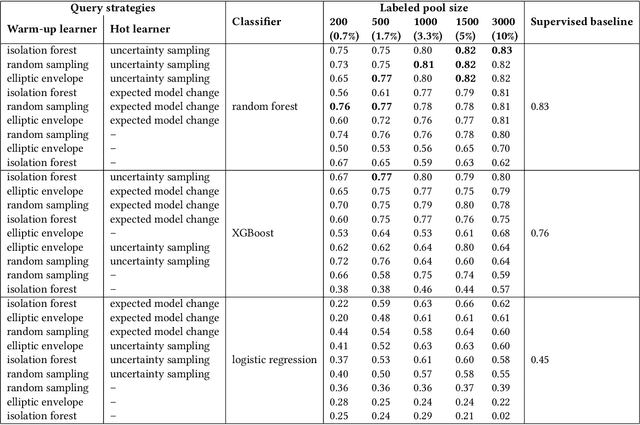
Labeled data is essential in modern systems that rely on Machine Learning (ML) for predictive modelling. Such systems may suffer from the cold-start problem: supervised models work well but, initially, there are no labels, which are costly or slow to obtain. This problem is even worse in imbalanced data scenarios. Online financial fraud detection is an example where labeling is: i) expensive, or ii) it suffers from long delays, if relying on victims filing complaints. The latter may not be viable if a model has to be in place immediately, so an option is to ask analysts to label events while minimizing the number of annotations to control costs. We propose an Active Learning (AL) annotation system for datasets with orders of magnitude of class imbalance, in a cold start streaming scenario. We present a computationally efficient Outlier-based Discriminative AL approach (ODAL) and design a novel 3-stage sequence of AL labeling policies where it is used as warm-up. Then, we perform empirical studies in four real world datasets, with various magnitudes of class imbalance. The results show that our method can more quickly reach a high performance model than standard AL policies. Its observed gains over random sampling can reach 80% and be competitive with policies with an unlimited annotation budget or additional historical data (with 1/10 to 1/50 of the labels).
GuiltyWalker: Distance to illicit nodes in the Bitcoin network
Feb 10, 2021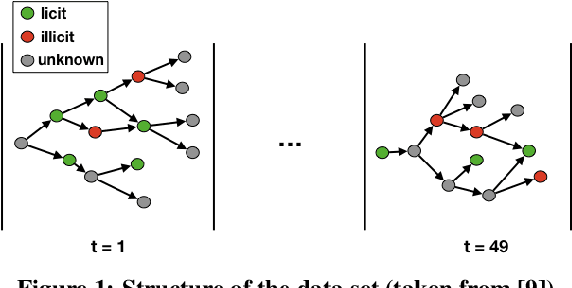
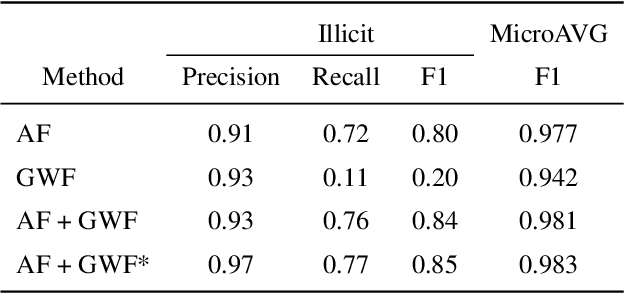
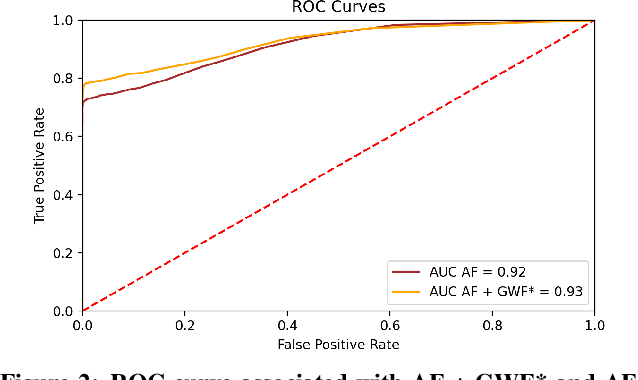
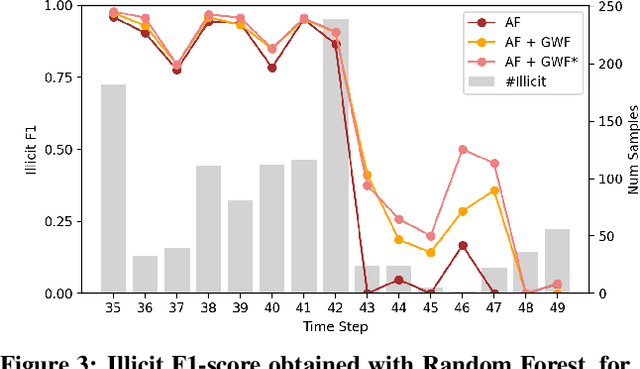
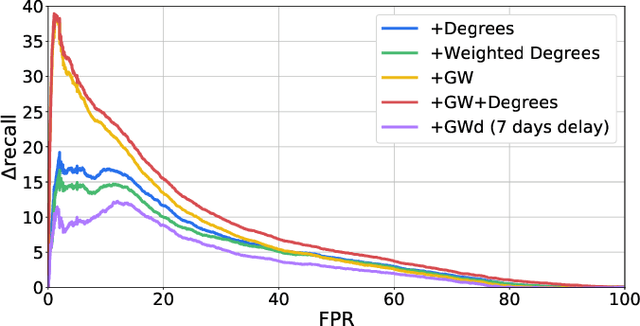
Money laundering is a global phenomenon with wide-reaching social and economic consequences. Cryptocurrencies are particularly susceptible due to the lack of control by authorities and their anonymity. Thus, it is important to develop new techniques to detect and prevent illicit cryptocurrency transactions. In our work, we propose new features based on the structure of the graph and past labels to boost the performance of machine learning methods to detect money laundering. Our method, GuiltyWalker, performs random walks on the bitcoin transaction graph and computes features based on the distance to illicit transactions. We combine these new features with features proposed by Weber et al. and observe an improvement of about 5pp regarding illicit classification. Namely, we observe that our proposed features are particularly helpful during a black market shutdown, where the algorithm by Weber et al. was low performing.
Machine learning methods to detect money laundering in the Bitcoin blockchain in the presence of label scarcity
May 29, 2020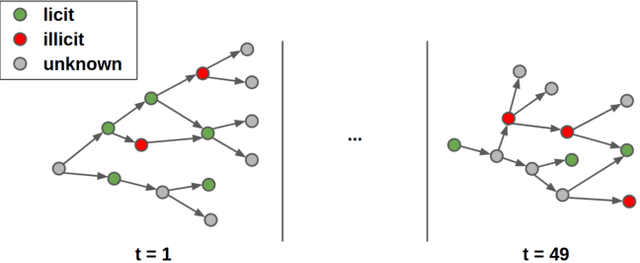
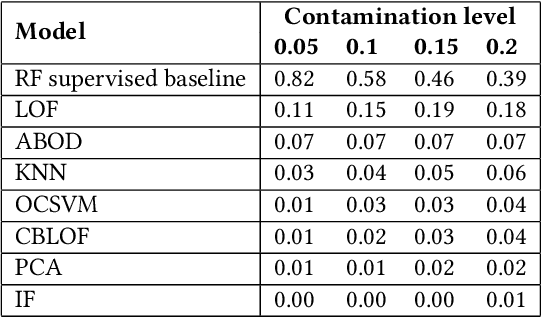
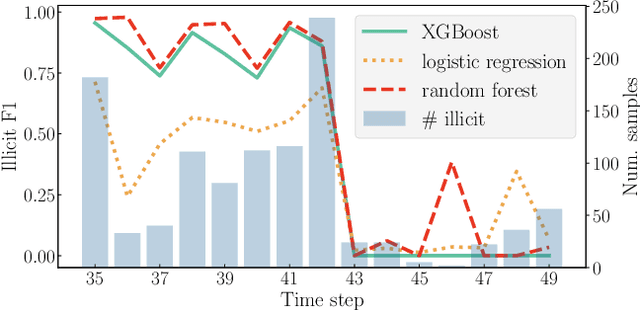
Every year, criminals launder billions of dollars acquired from serious felonies (e.g., terrorism, drug smuggling, or human trafficking) harming countless people and economies. Cryptocurrencies, in particular, have developed as a haven for money laundering activity. Machine Learning can be used to detect these illicit patterns. However, labels are so scarce that traditional supervised algorithms are inapplicable. Here, we address money laundering detection assuming minimal access to labels. First, we show that existing state-of-the-art solutions using unsupervised anomaly detection methods are inadequate to detect the illicit patterns in a real Bitcoin transaction dataset. Then, we show that our proposed active learning solution is capable of matching the performance of a fully supervised baseline by using just 5\% of the labels. This solution mimics a typical real-life situation in which a limited number of labels can be acquired through manual annotation by experts.
ARMS: Automated rules management system for fraud detection
Feb 14, 2020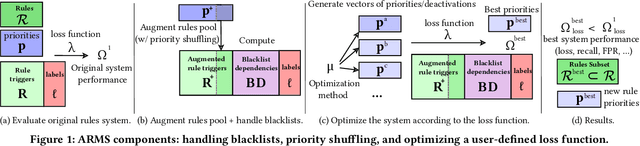
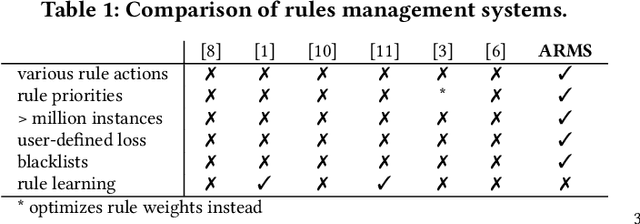
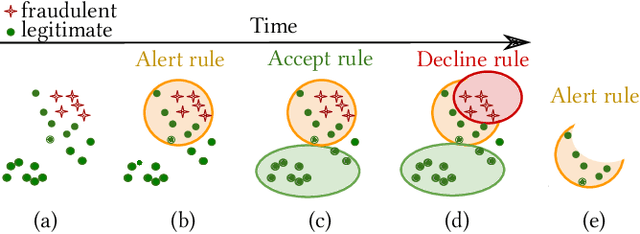
Fraud detection is essential in financial services, with the potential of greatly reducing criminal activities and saving considerable resources for businesses and customers. We address online fraud detection, which consists of classifying incoming transactions as either legitimate or fraudulent in real-time. Modern fraud detection systems consist of a machine learning model and rules defined by human experts. Often, the rules performance degrades over time due to concept drift, especially of adversarial nature. Furthermore, they can be costly to maintain, either because they are computationally expensive or because they send transactions for manual review. We propose ARMS, an automated rules management system that evaluates the contribution of individual rules and optimizes the set of active rules using heuristic search and a user-defined loss-function. It complies with critical domain-specific requirements, such as handling different actions (e.g., accept, alert, and decline), priorities, blacklists, and large datasets (i.e., hundreds of rules and millions of transactions). We use ARMS to optimize the rule-based systems of two real-world clients. Results show that it can maintain the original systems' performance (e.g., recall, or false-positive rate) using only a fraction of the original rules (~ 50% in one case, and ~ 20% in the other).
Interleaved Sequence RNNs for Fraud Detection
Feb 14, 2020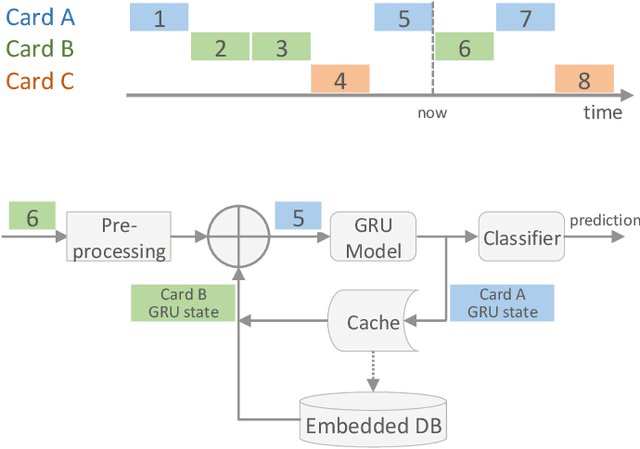

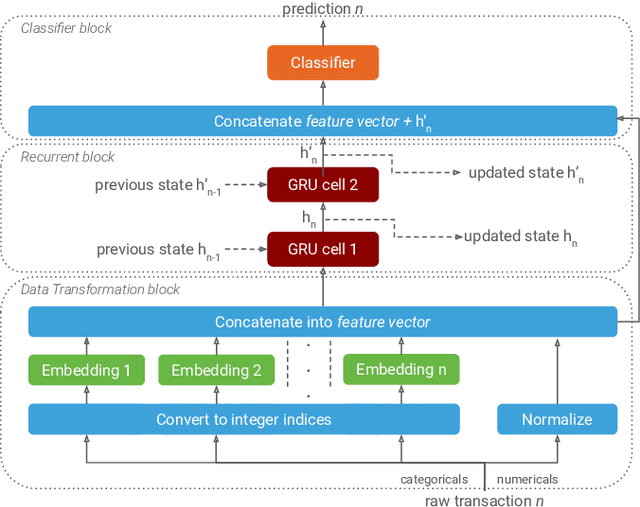
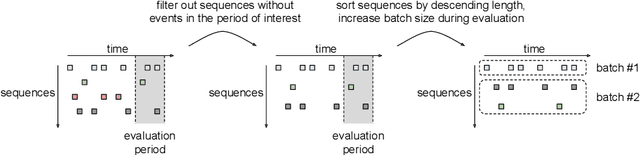
Payment card fraud causes multibillion dollar losses for banks and merchants worldwide, often fueling complex criminal activities. To address this, many real-time fraud detection systems use tree-based models, demanding complex feature engineering systems to efficiently enrich transactions with historical data while complying with millisecond-level latencies. In this work, we do not require those expensive features by using recurrent neural networks and treating payments as an interleaved sequence, where the history of each card is an unbounded, irregular sub-sequence. We present a complete RNN framework to detect fraud in real-time, proposing an efficient ML pipeline from preprocessing to deployment. We show that these feature-free, multi-sequence RNNs outperform state-of-the-art models saving millions of dollars in fraud detection and using fewer computational resources.