 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData+Shift: Supporting visual investigation of data distribution shifts by data scientists
Apr 29, 2022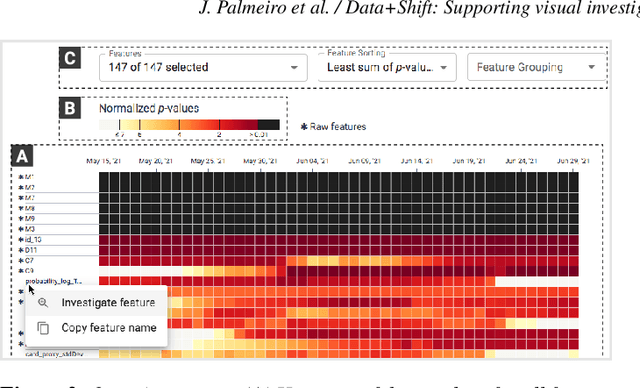
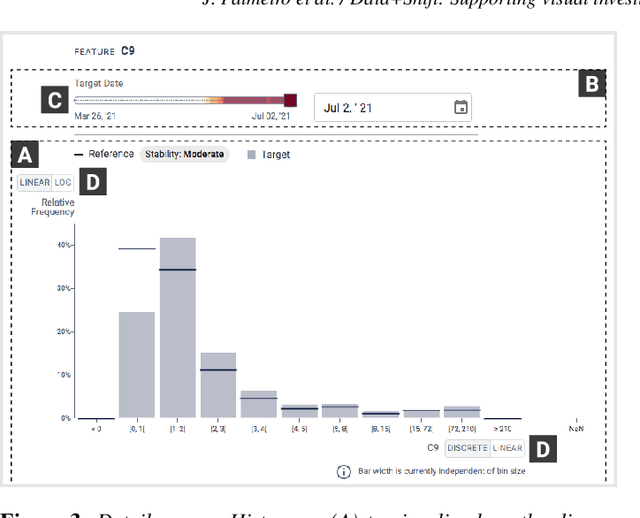
Machine learning on data streams is increasingly more present in multiple domains. However, there is often data distribution shift that can lead machine learning models to make incorrect decisions. While there are automatic methods to detect when drift is happening, human analysis, often by data scientists, is essential to diagnose the causes of the problem and adjust the system. We propose Data+Shift, a visual analytics tool to support data scientists in the task of investigating the underlying factors of shift in data features in the context of fraud detection. Design requirements were derived from interviews with data scientists. Data+Shift is integrated with JupyterLab and can be used alongside other data science tools. We validated our approach with a think-aloud experiment where a data scientist used the tool for a fraud detection use case.
Anti-Money Laundering Alert Optimization Using Machine Learning with Graphs
Dec 14, 2021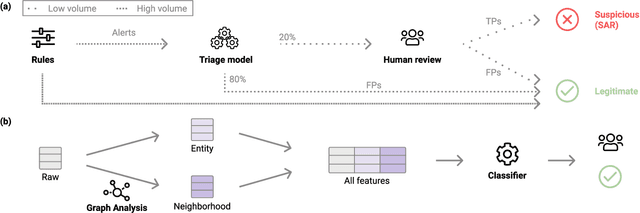
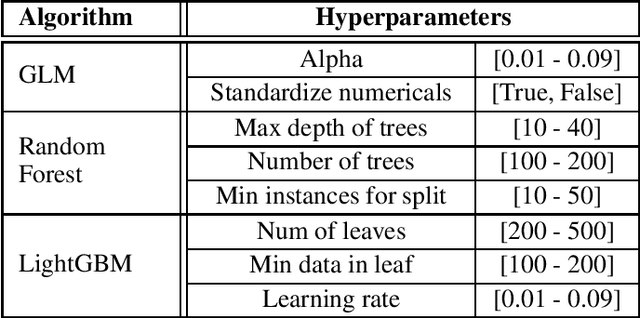

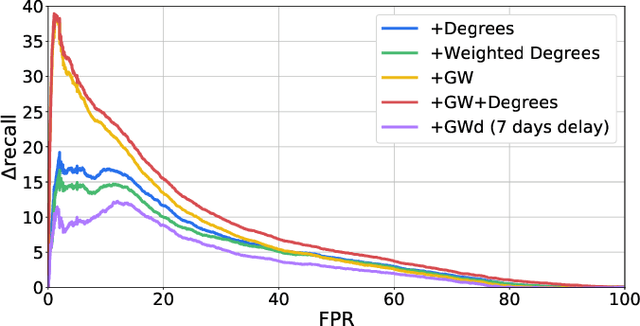
Money laundering is a global problem that concerns legitimizing proceeds from serious felonies (1.7-4 trillion euros annually) such as drug dealing, human trafficking, or corruption. The anti-money laundering systems deployed by financial institutions typically comprise rules aligned with regulatory frameworks. Human investigators review the alerts and report suspicious cases. Such systems suffer from high false-positive rates, undermining their effectiveness and resulting in high operational costs. We propose a machine learning triage model, which complements the rule-based system and learns to predict the risk of an alert accurately. Our model uses both entity-centric engineered features and attributes characterizing inter-entity relations in the form of graph-based features. We leverage time windows to construct the dynamic graph, optimizing for time and space efficiency. We validate our model on a real-world banking dataset and show how the triage model can reduce the number of false positives by 80% while detecting over 90% of true positives. In this way, our model can significantly improve anti-money laundering operations.