 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Me What's Wrong!: Combining Charts and Text to Guide Data Analysis
Oct 02, 2024Analyzing and finding anomalies in multi-dimensional datasets is a cumbersome but vital task across different domains. In the context of financial fraud detection, analysts must quickly identify suspicious activity among transactional data. This is an iterative process made of complex exploratory tasks such as recognizing patterns, grouping, and comparing. To mitigate the information overload inherent to these steps, we present a tool combining automated information highlights, Large Language Model generated textual insights, and visual analytics, facilitating exploration at different levels of detail. We perform a segmentation of the data per analysis area and visually represent each one, making use of automated visual cues to signal which require more attention. Upon user selection of an area, our system provides textual and graphical summaries. The text, acting as a link between the high-level and detailed views of the chosen segment, allows for a quick understanding of relevant details. A thorough exploration of the data comprising the selection can be done through graphical representations. The feedback gathered in a study performed with seven domain experts suggests our tool effectively supports and guides exploratory analysis, easing the identification of suspicious information.
Towards a Fully Unsupervised Framework for Intent Induction in Customer Support Dialogues
Jul 28, 2023State of the art models in intent induction require annotated datasets. However, annotating dialogues is time-consuming, laborious and expensive. In this work, we propose a completely unsupervised framework for intent induction within a dialogue. In addition, we show how pre-processing the dialogue corpora can improve results. Finally, we show how to extract the dialogue flows of intentions by investigating the most common sequences. Although we test our work in the MultiWOZ dataset, the fact that this framework requires no prior knowledge make it applicable to any possible use case, making it very relevant to real world customer support applications across industry.
Data+Shift: Supporting visual investigation of data distribution shifts by data scientists
Apr 29, 2022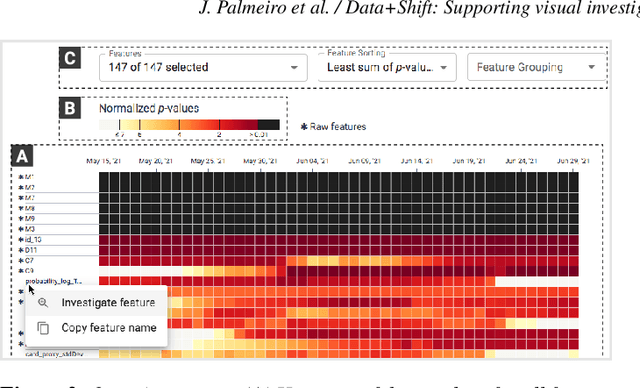
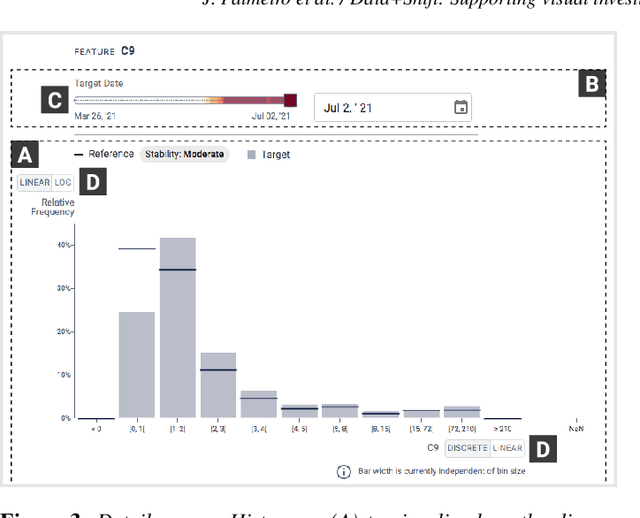
Machine learning on data streams is increasingly more present in multiple domains. However, there is often data distribution shift that can lead machine learning models to make incorrect decisions. While there are automatic methods to detect when drift is happening, human analysis, often by data scientists, is essential to diagnose the causes of the problem and adjust the system. We propose Data+Shift, a visual analytics tool to support data scientists in the task of investigating the underlying factors of shift in data features in the context of fraud detection. Design requirements were derived from interviews with data scientists. Data+Shift is integrated with JupyterLab and can be used alongside other data science tools. We validated our approach with a think-aloud experiment where a data scientist used the tool for a fraud detection use case.