 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving OCR using internal document redundancy
Aug 20, 2025Current OCR systems are based on deep learning models trained on large amounts of data. Although they have shown some ability to generalize to unseen data, especially in detection tasks, they can struggle with recognizing low-quality data. This is particularly evident for printed documents, where intra-domain data variability is typically low, but inter-domain data variability is high. In that context, current OCR methods do not fully exploit each document's redundancy. We propose an unsupervised method by leveraging the redundancy of character shapes within a document to correct imperfect outputs of a given OCR system and suggest better clustering. To this aim, we introduce an extended Gaussian Mixture Model (GMM) by alternating an Expectation-Maximization (EM) algorithm with an intra-cluster realignment process and normality statistical testing. We demonstrate improvements in documents with various levels of degradation, including recovered Uruguayan military archives and 17th to mid-20th century European newspapers.
From line segments to more organized Gestalts
Mar 18, 2016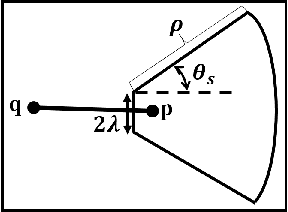

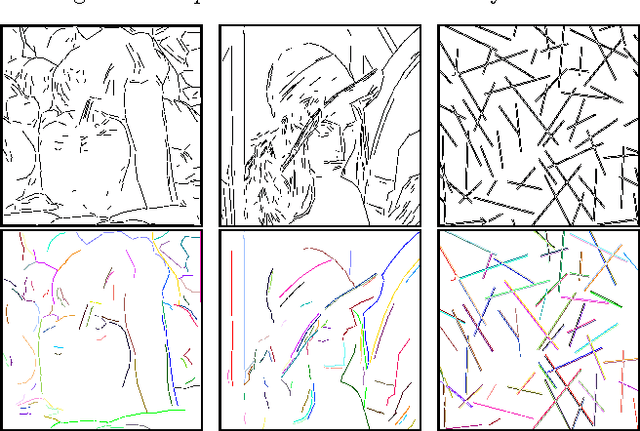
In this paper, we reconsider the early computer vision bottom-up program, according to which higher level features (geometric structures) in an image could be built up recursively from elementary features by simple grouping principles coming from Gestalt theory. Taking advantage of the (recent) advances in reliable line segment detectors, we propose three feature detectors that constitute one step up in this bottom up pyramid. For any digital image, our unsupervised algorithm computes three classic Gestalts from the set of predetected line segments: good continuations, nonlocal alignments, and bars. The methodology is based on a common stochastic {\it a contrario model} yielding three simple detection formulas, characterized by their number of false alarms. This detection algorithm is illustrated on several digital images.
Intensity-only optical compressive imaging using a multiply scattering material and a double phase retrieval approach
Jan 25, 2016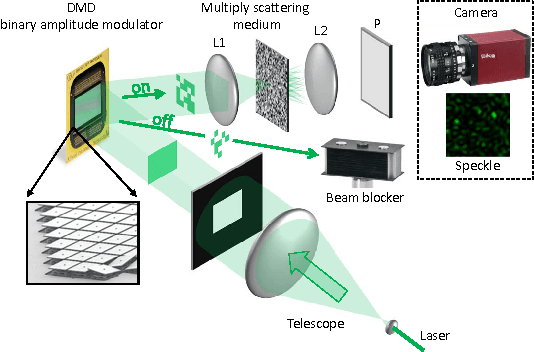

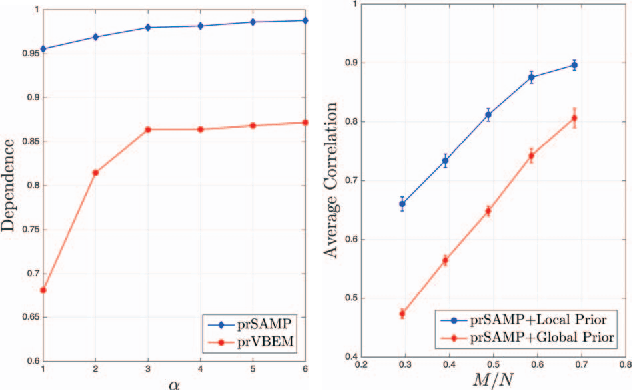

In this paper, the problem of compressive imaging is addressed using natural randomization by means of a multiply scattering medium. To utilize the medium in this way, its corresponding transmission matrix must be estimated. To calibrate the imager, we use a digital micromirror device (DMD) as a simple, cheap, and high-resolution binary intensity modulator. We propose a phase retrieval algorithm which is well adapted to intensity-only measurements on the camera, and to the input binary intensity patterns, both to estimate the complex transmission matrix as well as image reconstruction. We demonstrate promising experimental results for the proposed algorithm using the MNIST dataset of handwritten digits as example images.
Rate-Distortion Analysis of Multiview Coding in a DIBR Framework
Nov 19, 2012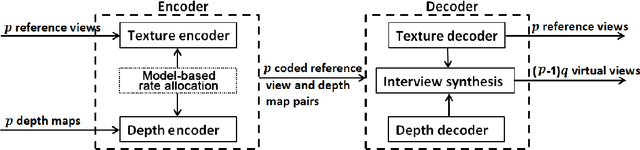
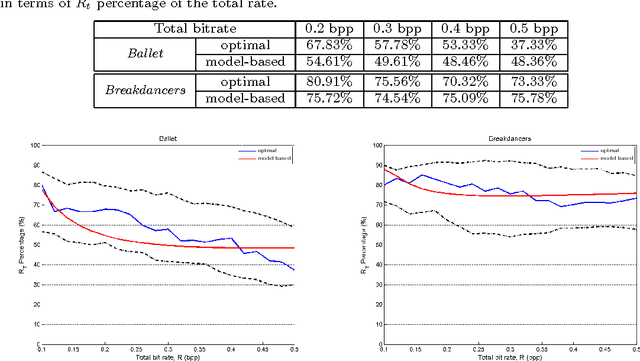

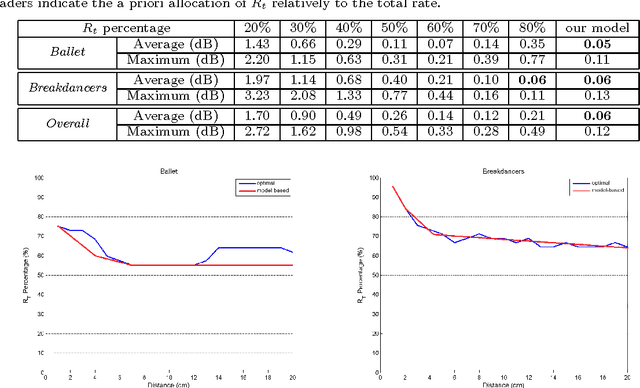
Depth image based rendering techniques for multiview applications have been recently introduced for efficient view generation at arbitrary camera positions. Encoding rate control has thus to consider both texture and depth data. Due to different structures of depth and texture images and their different roles on the rendered views, distributing the available bit budget between them however requires a careful analysis. Information loss due to texture coding affects the value of pixels in synthesized views while errors in depth information lead to shift in objects or unexpected patterns at their boundaries. In this paper, we address the problem of efficient bit allocation between textures and depth data of multiview video sequences. We adopt a rate-distortion framework based on a simplified model of depth and texture images. Our model preserves the main features of depth and texture images. Unlike most recent solutions, our method permits to avoid rendering at encoding time for distortion estimation so that the encoding complexity is not augmented. In addition to this, our model is independent of the underlying inpainting method that is used at decoder. Experiments confirm our theoretical results and the efficiency of our rate allocation strategy.