 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer Aided Detection for Pulmonary Embolism Challenge (CAD-PE)
Mar 30, 2020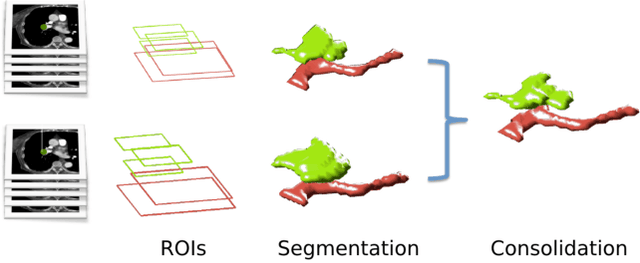
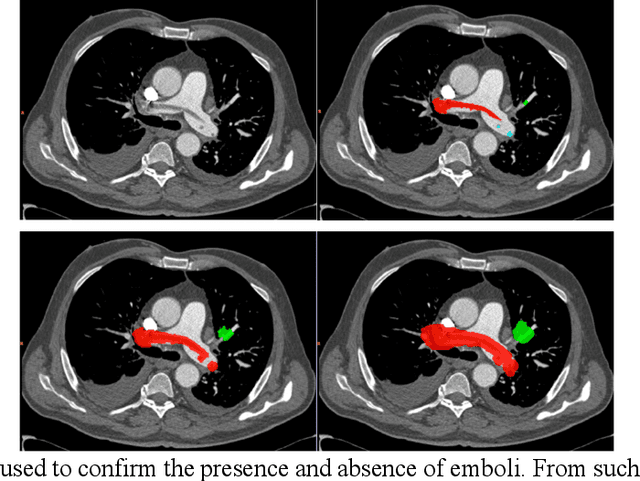
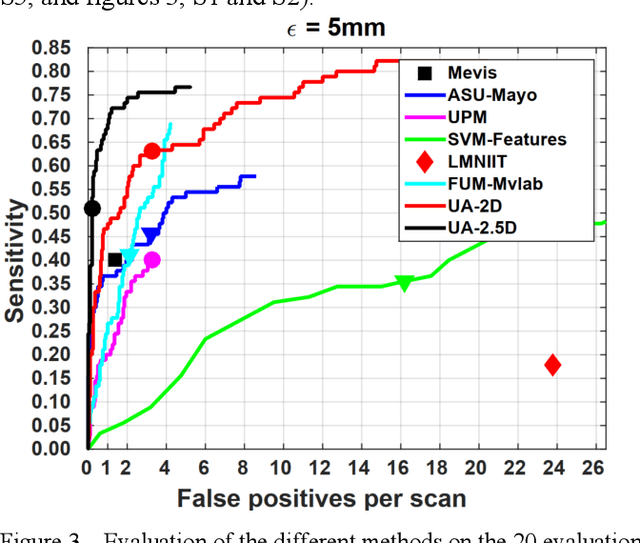
Rationale: Computer aided detection (CAD) algorithms for Pulmonary Embolism (PE) algorithms have been shown to increase radiologists' sensitivity with a small increase in specificity. However, CAD for PE has not been adopted into clinical practice, likely because of the high number of false positives current CAD software produces. Objective: To generate a database of annotated computed tomography pulmonary angiographies, use it to compare the sensitivity and false positive rate of current algorithms and to develop new methods that improve such metrics. Methods: 91 Computed tomography pulmonary angiography scans were annotated by at least one radiologist by segmenting all pulmonary emboli visible on the study. 20 annotated CTPAs were open to the public in the form of a medical image analysis challenge. 20 more were kept for evaluation purposes. 51 were made available post-challenge. 8 submissions, 6 of them novel, were evaluated on the 20 evaluation CTPAs. Performance was measured as per embolus sensitivity vs. false positives per scan curve. Results: The best algorithms achieved a per-embolus sensitivity of 75% at 2 false positives per scan (fps) or of 70% at 1 fps, outperforming the state of the art. Deep learning approaches outperformed traditional machine learning ones, and their performance improved with the number of training cases. Significance: Through this work and challenge we have improved the state-of-the art of computer aided detection algorithms for pulmonary embolism. An open database and an evaluation benchmark for such algorithms have been generated, easing the development of further improvements. Implications on clinical practice will need further research.
Parallel Stroked Multi Line: a model-based method for compressing large fingerprint databases
Jan 10, 2016
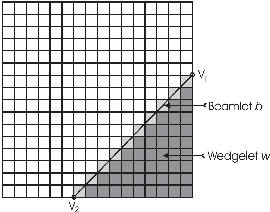

With increasing usage of fingerprints as an important biometric data, the need to compress the large fingerprint databases has become essential. The most recommended compression algorithm, even by standards, is JPEG2K. But at high compression rates, this algorithm is ineffective. In this paper, a model is proposed which is based on parallel lines with same orientations, arbitrary widths and same gray level values located on rectangle with constant gray level value as background. We refer to this algorithm as Parallel Stroked Multi Line (PSML). By using Adaptive Geometrical Wavelet and employing PSML, a compression algorithm is developed. This compression algorithm can preserve fingerprint structure and minutiae. The exact algorithm of computing the PSML model take exponential time. However, we have proposed an alternative approximation algorithm, which reduces the time complexity to $O(n^3)$. The proposed PSML alg. has significant advantage over Wedgelets Transform in PSNR value and visual quality in compressed images. The proposed method, despite the lower PSNR values than JPEG2K algorithm in common range of compression rates, in all compression rates have nearly equal or greater advantage over JPEG2K when used by Automatic Fingerprint Identification Systems (AFIS). At high compression rates, according to PSNR values, mean EER rate and visual quality, the encoded images with JPEG2K can not be identified from each other after compression. But, images encoded by the PSML alg. retained the sufficient information to maintain fingerprint identification performances similar to the ones obtained by raw images without compression. One the U.are.U 400 database, the mean EER rate for uncompressed images is 4.54%, while at 267:1 compression ratio, this value becomes 49.41% and 6.22% for JPEG2K and PSML, respectively. This result shows a significant improvement over the standard JPEG2K algorithm.
Rate-Distortion Analysis of Multiview Coding in a DIBR Framework
Nov 19, 2012
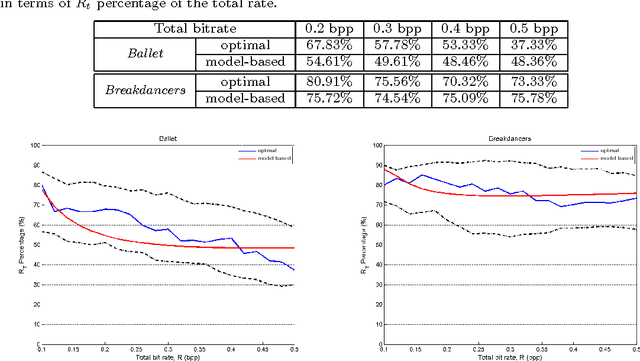

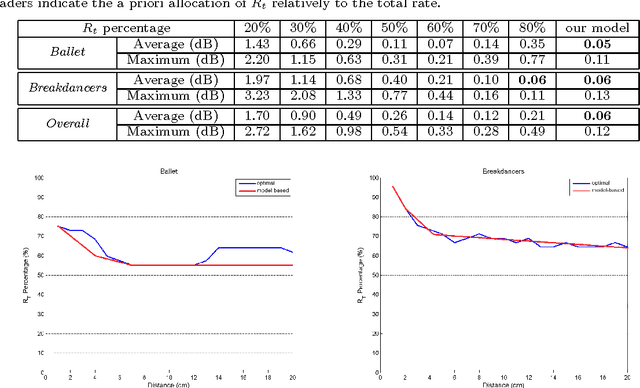
Depth image based rendering techniques for multiview applications have been recently introduced for efficient view generation at arbitrary camera positions. Encoding rate control has thus to consider both texture and depth data. Due to different structures of depth and texture images and their different roles on the rendered views, distributing the available bit budget between them however requires a careful analysis. Information loss due to texture coding affects the value of pixels in synthesized views while errors in depth information lead to shift in objects or unexpected patterns at their boundaries. In this paper, we address the problem of efficient bit allocation between textures and depth data of multiview video sequences. We adopt a rate-distortion framework based on a simplified model of depth and texture images. Our model preserves the main features of depth and texture images. Unlike most recent solutions, our method permits to avoid rendering at encoding time for distortion estimation so that the encoding complexity is not augmented. In addition to this, our model is independent of the underlying inpainting method that is used at decoder. Experiments confirm our theoretical results and the efficiency of our rate allocation strategy.