 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting natural disasters, damage, and incidents in the wild
Aug 20, 2020

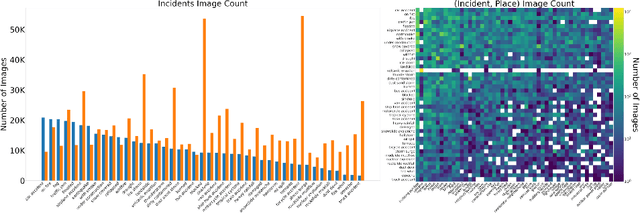
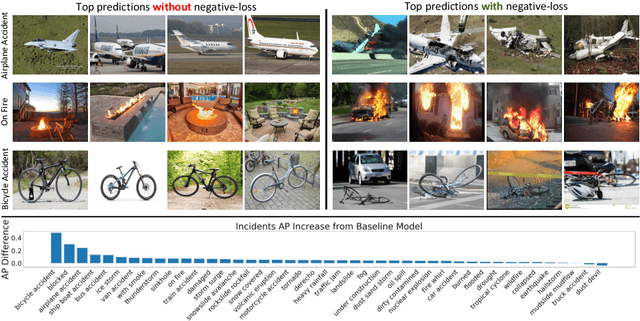
Responding to natural disasters, such as earthquakes, floods, and wildfires, is a laborious task performed by on-the-ground emergency responders and analysts. Social media has emerged as a low-latency data source to quickly understand disaster situations. While most studies on social media are limited to text, images offer more information for understanding disaster and incident scenes. However, no large-scale image datasets for incident detection exists. In this work, we present the Incidents Dataset, which contains 446,684 images annotated by humans that cover 43 incidents across a variety of scenes. We employ a baseline classification model that mitigates false-positive errors and we perform image filtering experiments on millions of social media images from Flickr and Twitter. Through these experiments, we show how the Incidents Dataset can be used to detect images with incidents in the wild. Code, data, and models are available online at http://incidentsdataset.csail.mit.edu.
Recipe1M: A Dataset for Learning Cross-Modal Embeddings for Cooking Recipes and Food Images
Oct 14, 2018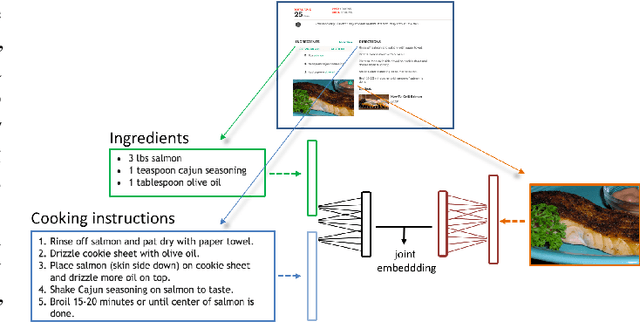
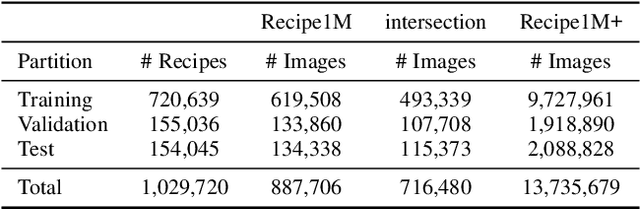

In this paper, we introduce Recipe1M, a new large-scale, structured corpus of over one million cooking recipes and 13 million food images. As the largest publicly available collection of recipe data, Recipe1M affords the ability to train high-capacity models on aligned, multi-modal data. Using these data, we train a neural network to learn a joint embedding of recipes and images that yields impressive results on an image-recipe retrieval task. Moreover, we demonstrate that regularization via the addition of a high-level classification objective both improves retrieval performance to rival that of humans and enables semantic vector arithmetic. We postulate that these embeddings will provide a basis for further exploration of the Recipe1M dataset and food and cooking in general. Code, data and models are publicly available.