 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing beyond accuracy: estimating homophily in social networks using predictions
Jan 30, 2020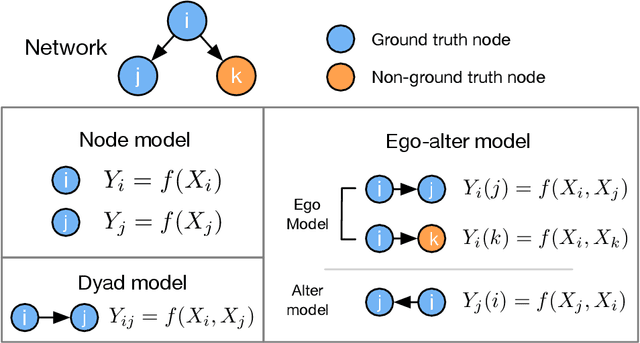
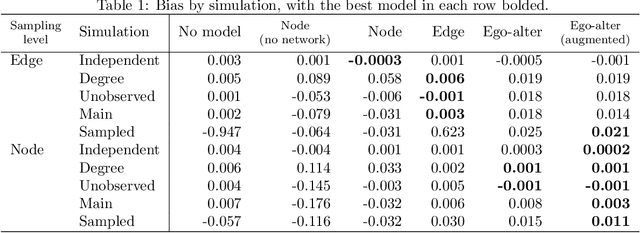
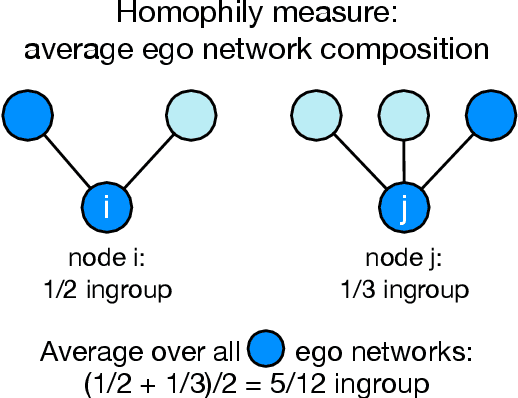
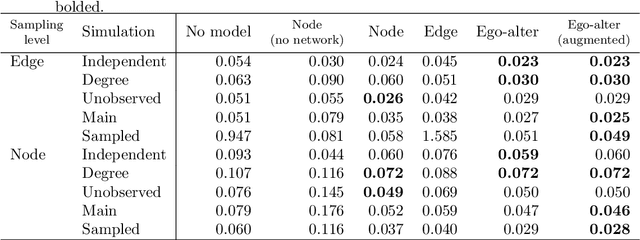
In online social networks, it is common to use predictions of node categories to estimate measures of homophily and other relational properties. However, online social network data often lacks basic demographic information about the nodes. Researchers must rely on predicted node attributes to estimate measures of homophily, but little is known about the validity of these measures. We show that estimating homophily in a network can be viewed as a dyadic prediction problem, and that homophily estimates are unbiased when dyad-level residuals sum to zero in the network. Node-level prediction models, such as the use of names to classify ethnicity or gender, do not generally have this property and can introduce large biases into homophily estimates. Bias occurs due to error autocorrelation along dyads. Importantly, node-level classification performance is not a reliable indicator of estimation accuracy for homophily. We compare estimation strategies that make predictions at the node and dyad levels, evaluating performance in different settings. We propose a novel "ego-alter" modeling approach that outperforms standard node and dyad classification strategies. While this paper focuses on homophily, results generalize to other relational measures which aggregate predictions along the dyads in a network. We conclude with suggestions for research designs to study homophily in online networks. Code for this paper is available at https://github.com/georgeberry/autocorr.
Role action embeddings: scalable representation of network positions
Dec 03, 2018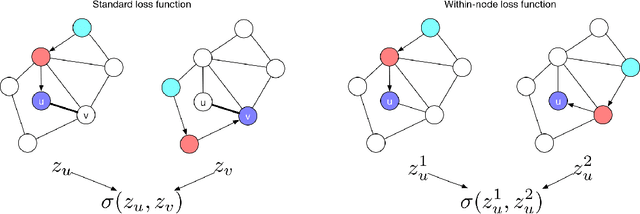

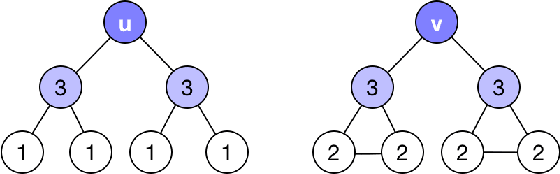
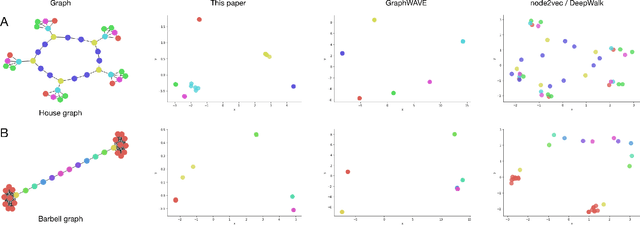
We consider the question of embedding nodes with similar local neighborhoods together in embedding space, commonly referred to as "role embeddings." We propose RAE, an unsupervised framework that learns role embeddings. It combines a within-node loss function and a graph neural network (GNN) architecture to place nodes with similar local neighborhoods close in embedding space. We also propose a faster way of generating negative examples called neighbor shuffling, which quickly creates negative examples directly within batches. These techniques can be easily combined with existing GNN methods to create unsupervised role embeddings at scale. We then explore role action embeddings, which summarize the non-structural features in a node's neighborhood, leading to better performance on node classification tasks. We find that the model architecture proposed here provides strong performance on both graph and node classification tasks, in some cases competitive with semi-supervised methods.
Discussion quality diffuses in the digital public square
Feb 22, 2017
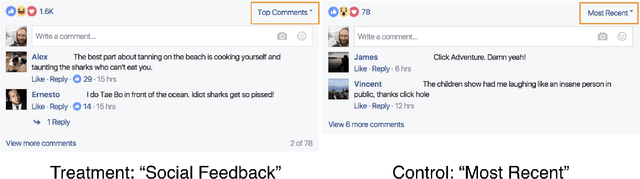


Studies of online social influence have demonstrated that friends have important effects on many types of behavior in a wide variety of settings. However, we know much less about how influence works among relative strangers in digital public squares, despite important conversations happening in such spaces. We present the results of a study on large public Facebook pages where we randomly used two different methods--most recent and social feedback--to order comments on posts. We find that the social feedback condition results in higher quality viewed comments and response comments. After measuring the average quality of comments written by users before the study, we find that social feedback has a positive effect on response quality for both low and high quality commenters. We draw on a theoretical framework of social norms to explain this empirical result. In order to examine the influence mechanism further, we measure the similarity between comments viewed and written during the study, finding that similarity increases for the highest quality contributors under the social feedback condition. This suggests that, in addition to norms, some individuals may respond with increased relevance to high-quality comments.