 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Do I Really Know? Learning Factual Self-Verification for Hallucination Reduction
Feb 02, 2026Factual hallucination remains a central challenge for large language models (LLMs). Existing mitigation approaches primarily rely on either external post-hoc verification or mapping uncertainty directly to abstention during fine-tuning, often resulting in overly conservative behavior. We propose VeriFY, a training-time framework that teaches LLMs to reason about factual uncertainty through consistency-based self-verification. VeriFY augments training with structured verification traces that guide the model to produce an initial answer, generate and answer a probing verification query, issue a consistency judgment, and then decide whether to answer or abstain. To address the risk of reinforcing hallucinated content when training on augmented traces, we introduce a stage-level loss masking approach that excludes hallucinated answer stages from the training objective while preserving supervision over verification behavior. Across multiple model families and scales, VeriFY reduces factual hallucination rates by 9.7 to 53.3 percent, with only modest reductions in recall (0.4 to 5.7 percent), and generalizes across datasets when trained on a single source. The source code, training data, and trained model checkpoints will be released upon acceptance.
There Is More to Refusal in Large Language Models than a Single Direction
Feb 02, 2026Prior work argues that refusal in large language models is mediated by a single activation-space direction, enabling effective steering and ablation. We show that this account is incomplete. Across eleven categories of refusal and non-compliance, including safety, incomplete or unsupported requests, anthropomorphization, and over-refusal, we find that these refusal behaviors correspond to geometrically distinct directions in activation space. Yet despite this diversity, linear steering along any refusal-related direction produces nearly identical refusal to over-refusal trade-offs, acting as a shared one-dimensional control knob. The primary effect of different directions is not whether the model refuses, but how it refuses.
SGM: A Framework for Building Specification-Guided Moderation Filters
May 26, 2025Aligning large language models (LLMs) with deployment-specific requirements is critical but inherently imperfect. Despite extensive training, models remain susceptible to misalignment and adversarial inputs such as jailbreaks. Content moderation filters are commonly used as external safeguards, though they typically focus narrowly on safety. We introduce SGM (Specification-Guided Moderation), a flexible framework for training moderation filters grounded in user-defined specifications that go beyond standard safety concerns. SGM automates training data generation without relying on human-written examples, enabling scalable support for diverse, application-specific alignment goals. SGM-trained filters perform on par with state-of-the-art safety filters built on curated datasets, while supporting fine-grained and user-defined alignment control.
Exploiting the Layered Intrinsic Dimensionality of Deep Models for Practical Adversarial Training
May 27, 2024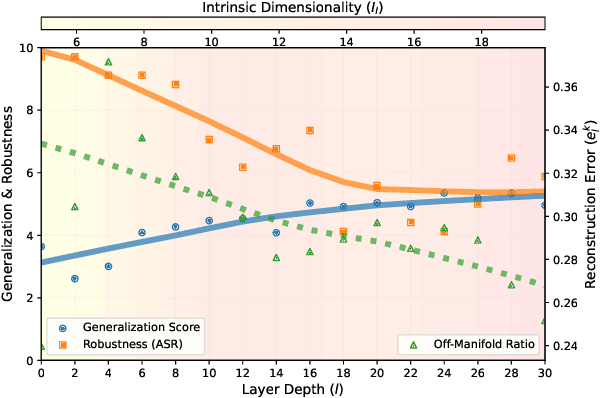



Despite being a heavily researched topic, Adversarial Training (AT) is rarely, if ever, deployed in practical AI systems for two primary reasons: (i) the gained robustness is frequently accompanied by a drop in generalization and (ii) generating adversarial examples (AEs) is computationally prohibitively expensive. To address these limitations, we propose SMAAT, a new AT algorithm that leverages the manifold conjecture, stating that off-manifold AEs lead to better robustness while on-manifold AEs result in better generalization. Specifically, SMAAT aims at generating a higher proportion of off-manifold AEs by perturbing the intermediate deepnet layer with the lowest intrinsic dimension. This systematically results in better scalability compared to classical AT as it reduces the PGD chains length required for generating the AEs. Additionally, our study provides, to the best of our knowledge, the first explanation for the difference in the generalization and robustness trends between vision and language models, ie., AT results in a drop in generalization in vision models whereas, in encoder-based language models, generalization either improves or remains unchanged. We show that vision transformers and decoder-based models tend to have low intrinsic dimensionality in the earlier layers of the network (more off-manifold AEs), while encoder-based models have low intrinsic dimensionality in the later layers. We demonstrate the efficacy of SMAAT; on several tasks, including robustifying (i) sentiment classifiers, (ii) safety filters in decoder-based models, and (iii) retrievers in RAG setups. SMAAT requires only 25-33% of the GPU time compared to standard AT, while significantly improving robustness across all applications and maintaining comparable generalization.
A3T: Accuracy Aware Adversarial Training
Nov 29, 2022Adversarial training has been empirically shown to be more prone to overfitting than standard training. The exact underlying reasons still need to be fully understood. In this paper, we identify one cause of overfitting related to current practices of generating adversarial samples from misclassified samples. To address this, we propose an alternative approach that leverages the misclassified samples to mitigate the overfitting problem. We show that our approach achieves better generalization while having comparable robustness to state-of-the-art adversarial training methods on a wide range of computer vision, natural language processing, and tabular tasks.
Impact of Adversarial Training on Robustness and Generalizability of Language Models
Nov 10, 2022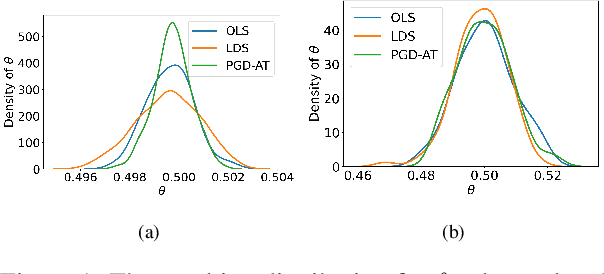

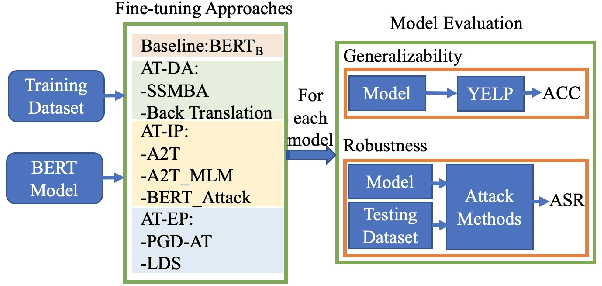
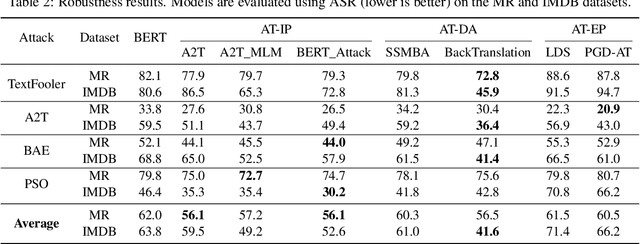
Adversarial training is widely acknowledged as the most effective defense against adversarial attacks. However, it is also well established that achieving both robustness and generalization in adversarially trained models involves a trade-off. The goal of this work is to provide an in depth comparison of different approaches for adversarial training in language models. Specifically, we study the effect of pre-training data augmentation as well as training time input perturbations vs. embedding space perturbations on the robustness and generalization of BERT-like language models. Our findings suggest that better robustness can be achieved by pre-training data augmentation or by training with input space perturbation. However, training with embedding space perturbation significantly improves generalization. A linguistic correlation analysis of neurons of the learned models reveal that the improved generalization is due to `more specialized' neurons. To the best of our knowledge, this is the first work to carry out a deep qualitative analysis of different methods of generating adversarial examples in adversarial training of language models.
GREENER: Graph Neural Networks for News Media Profiling
Nov 10, 2022We study the problem of profiling news media on the Web with respect to their factuality of reporting and bias. This is an important but under-studied problem related to disinformation and "fake news" detection, but it addresses the issue at a coarser granularity compared to looking at an individual article or an individual claim. This is useful as it allows to profile entire media outlets in advance. Unlike previous work, which has focused primarily on text (e.g.,~on the text of the articles published by the target website, or on the textual description in their social media profiles or in Wikipedia), here our main focus is on modeling the similarity between media outlets based on the overlap of their audience. This is motivated by homophily considerations, i.e.,~the tendency of people to have connections to people with similar interests, which we extend to media, hypothesizing that similar types of media would be read by similar kinds of users. In particular, we propose GREENER (GRaph nEural nEtwork for News mEdia pRofiling), a model that builds a graph of inter-media connections based on their audience overlap, and then uses graph neural networks to represent each medium. We find that such representations are quite useful for predicting the factuality and the bias of news media outlets, yielding improvements over state-of-the-art results reported on two datasets. When augmented with conventionally used representations obtained from news articles, Twitter, YouTube, Facebook, and Wikipedia, prediction accuracy is found to improve by 2.5-27 macro-F1 points for the two tasks.
Ten Years after ImageNet: A 360° Perspective on AI
Oct 01, 2022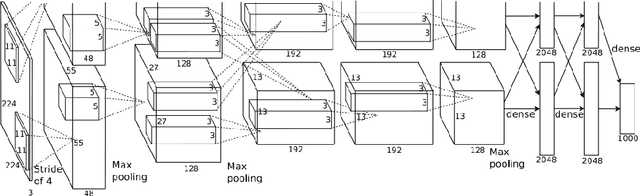
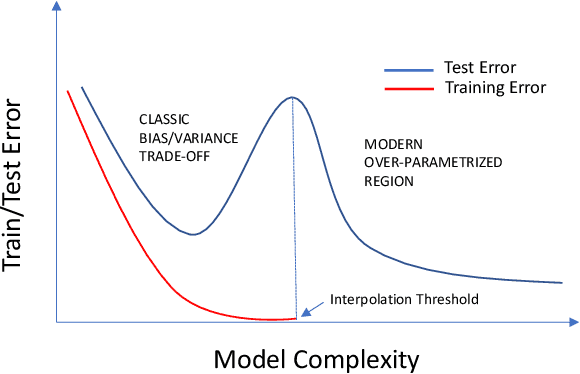
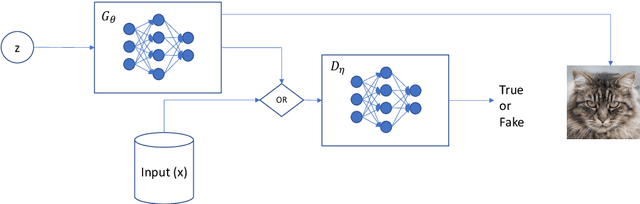
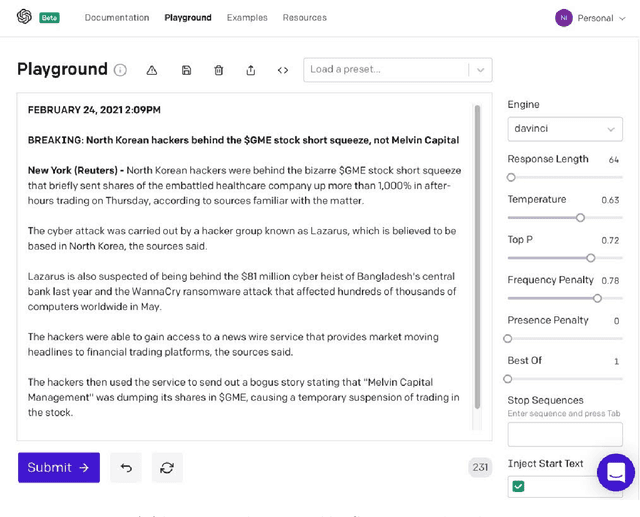
It is ten years since neural networks made their spectacular comeback. Prompted by this anniversary, we take a holistic perspective on Artificial Intelligence (AI). Supervised Learning for cognitive tasks is effectively solved - provided we have enough high-quality labeled data. However, deep neural network models are not easily interpretable, and thus the debate between blackbox and whitebox modeling has come to the fore. The rise of attention networks, self-supervised learning, generative modeling, and graph neural networks has widened the application space of AI. Deep Learning has also propelled the return of reinforcement learning as a core building block of autonomous decision making systems. The possible harms made possible by new AI technologies have raised socio-technical issues such as transparency, fairness, and accountability. The dominance of AI by Big-Tech who control talent, computing resources, and most importantly, data may lead to an extreme AI divide. Failure to meet high expectations in high profile, and much heralded flagship projects like self-driving vehicles could trigger another AI winter.
A Survey on Predicting the Factuality and the Bias of News Media
Mar 16, 2021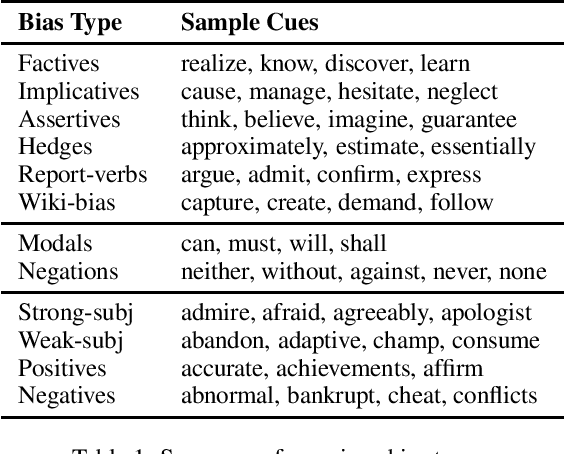
The present level of proliferation of fake, biased, and propagandistic content online has made it impossible to fact-check every single suspicious claim or article, either manually or automatically. Thus, many researchers are shifting their attention to higher granularity, aiming to profile entire news outlets, which makes it possible to detect likely "fake news" the moment it is published, by simply checking the reliability of its source. Source factuality is also an important element of systems for automatic fact-checking and "fake news" detection, as they need to assess the reliability of the evidence they retrieve online. Political bias detection, which in the Western political landscape is about predicting left-center-right bias, is an equally important topic, which has experienced a similar shift towards profiling entire news outlets. Moreover, there is a clear connection between the two, as highly biased media are less likely to be factual; yet, the two problems have been addressed separately. In this survey, we review the state of the art on media profiling for factuality and bias, arguing for the need to model them jointly. We further discuss interesting recent advances in using different information sources and modalities, which go beyond the text of the articles the target news outlet has published. Finally, we discuss current challenges and outline future research directions.