 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGREENER: Graph Neural Networks for News Media Profiling
Nov 10, 2022We study the problem of profiling news media on the Web with respect to their factuality of reporting and bias. This is an important but under-studied problem related to disinformation and "fake news" detection, but it addresses the issue at a coarser granularity compared to looking at an individual article or an individual claim. This is useful as it allows to profile entire media outlets in advance. Unlike previous work, which has focused primarily on text (e.g.,~on the text of the articles published by the target website, or on the textual description in their social media profiles or in Wikipedia), here our main focus is on modeling the similarity between media outlets based on the overlap of their audience. This is motivated by homophily considerations, i.e.,~the tendency of people to have connections to people with similar interests, which we extend to media, hypothesizing that similar types of media would be read by similar kinds of users. In particular, we propose GREENER (GRaph nEural nEtwork for News mEdia pRofiling), a model that builds a graph of inter-media connections based on their audience overlap, and then uses graph neural networks to represent each medium. We find that such representations are quite useful for predicting the factuality and the bias of news media outlets, yielding improvements over state-of-the-art results reported on two datasets. When augmented with conventionally used representations obtained from news articles, Twitter, YouTube, Facebook, and Wikipedia, prediction accuracy is found to improve by 2.5-27 macro-F1 points for the two tasks.
PDNS-Net: A Large Heterogeneous Graph Benchmark Dataset of Network Resolutions for Graph Learning
Mar 15, 2022



In order to advance the state of the art in graph learning algorithms, it is necessary to construct large real-world datasets. While there are many benchmark datasets for homogeneous graphs, only a few of them are available for heterogeneous graphs. Furthermore, the latter graphs are small in size rendering them insufficient to understand how graph learning algorithms perform in terms of classification metrics and computational resource utilization. We introduce, PDNS-Net, the largest public heterogeneous graph dataset containing 447K nodes and 897K edges for the malicious domain classification task. Compared to the popular heterogeneous datasets IMDB and DBLP, PDNS-Net is 38 and 17 times bigger respectively. We provide a detailed analysis of PDNS-Net including the data collection methodology, heterogeneous graph construction, descriptive statistics and preliminary graph classification performance. The dataset is publicly available at https://github.com/qcri/PDNS-Net. Our preliminary evaluation of both popular homogeneous and heterogeneous graph neural networks on PDNS-Net reveals that further research is required to improve the performance of these models on large heterogeneous graphs.
Uncovering IP Address Hosting Types Behind Malicious Websites
Oct 30, 2021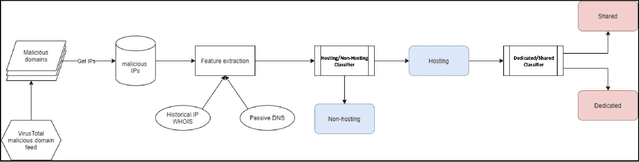


Hundreds of thousands of malicious domains are created everyday. These malicious domains are hosted on a wide variety of network infrastructures. Traditionally, attackers utilize bullet proof hosting services (e.g. MaxiDed, Cyber Bunker) to take advantage of relatively lenient policies on what content they can host. However, these IP ranges are increasingly being blocked or the services are taken down by law enforcement. Hence, attackers are moving towards utilizing IPs from regular hosting providers while staying under the radar of these hosting providers. There are several practical advantages of accurately knowing the type of IP used to host malicious domains. If the IP is a dedicated IP (i.e. it is leased to a single entity), one may blacklist the IP to block domains hosted on those IPs as welll as use as a way to identify other malicious domains hosted the same IP. If the IP is a shared hosting IP, hosting providers may take measures to clean up such domains and maintain a high reputation for their users.