 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo I Really Know? Learning Factual Self-Verification for Hallucination Reduction
Feb 02, 2026Factual hallucination remains a central challenge for large language models (LLMs). Existing mitigation approaches primarily rely on either external post-hoc verification or mapping uncertainty directly to abstention during fine-tuning, often resulting in overly conservative behavior. We propose VeriFY, a training-time framework that teaches LLMs to reason about factual uncertainty through consistency-based self-verification. VeriFY augments training with structured verification traces that guide the model to produce an initial answer, generate and answer a probing verification query, issue a consistency judgment, and then decide whether to answer or abstain. To address the risk of reinforcing hallucinated content when training on augmented traces, we introduce a stage-level loss masking approach that excludes hallucinated answer stages from the training objective while preserving supervision over verification behavior. Across multiple model families and scales, VeriFY reduces factual hallucination rates by 9.7 to 53.3 percent, with only modest reductions in recall (0.4 to 5.7 percent), and generalizes across datasets when trained on a single source. The source code, training data, and trained model checkpoints will be released upon acceptance.
SGM: A Framework for Building Specification-Guided Moderation Filters
May 26, 2025Aligning large language models (LLMs) with deployment-specific requirements is critical but inherently imperfect. Despite extensive training, models remain susceptible to misalignment and adversarial inputs such as jailbreaks. Content moderation filters are commonly used as external safeguards, though they typically focus narrowly on safety. We introduce SGM (Specification-Guided Moderation), a flexible framework for training moderation filters grounded in user-defined specifications that go beyond standard safety concerns. SGM automates training data generation without relying on human-written examples, enabling scalable support for diverse, application-specific alignment goals. SGM-trained filters perform on par with state-of-the-art safety filters built on curated datasets, while supporting fine-grained and user-defined alignment control.
Exploiting the Layered Intrinsic Dimensionality of Deep Models for Practical Adversarial Training
May 27, 2024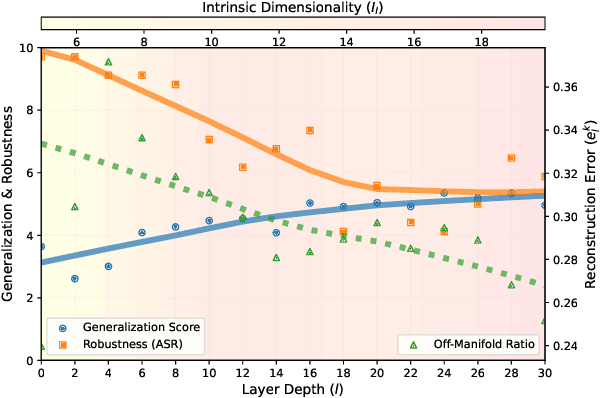



Despite being a heavily researched topic, Adversarial Training (AT) is rarely, if ever, deployed in practical AI systems for two primary reasons: (i) the gained robustness is frequently accompanied by a drop in generalization and (ii) generating adversarial examples (AEs) is computationally prohibitively expensive. To address these limitations, we propose SMAAT, a new AT algorithm that leverages the manifold conjecture, stating that off-manifold AEs lead to better robustness while on-manifold AEs result in better generalization. Specifically, SMAAT aims at generating a higher proportion of off-manifold AEs by perturbing the intermediate deepnet layer with the lowest intrinsic dimension. This systematically results in better scalability compared to classical AT as it reduces the PGD chains length required for generating the AEs. Additionally, our study provides, to the best of our knowledge, the first explanation for the difference in the generalization and robustness trends between vision and language models, ie., AT results in a drop in generalization in vision models whereas, in encoder-based language models, generalization either improves or remains unchanged. We show that vision transformers and decoder-based models tend to have low intrinsic dimensionality in the earlier layers of the network (more off-manifold AEs), while encoder-based models have low intrinsic dimensionality in the later layers. We demonstrate the efficacy of SMAAT; on several tasks, including robustifying (i) sentiment classifiers, (ii) safety filters in decoder-based models, and (iii) retrievers in RAG setups. SMAAT requires only 25-33% of the GPU time compared to standard AT, while significantly improving robustness across all applications and maintaining comparable generalization.
A3T: Accuracy Aware Adversarial Training
Nov 29, 2022Adversarial training has been empirically shown to be more prone to overfitting than standard training. The exact underlying reasons still need to be fully understood. In this paper, we identify one cause of overfitting related to current practices of generating adversarial samples from misclassified samples. To address this, we propose an alternative approach that leverages the misclassified samples to mitigate the overfitting problem. We show that our approach achieves better generalization while having comparable robustness to state-of-the-art adversarial training methods on a wide range of computer vision, natural language processing, and tabular tasks.
Impact of Adversarial Training on Robustness and Generalizability of Language Models
Nov 10, 2022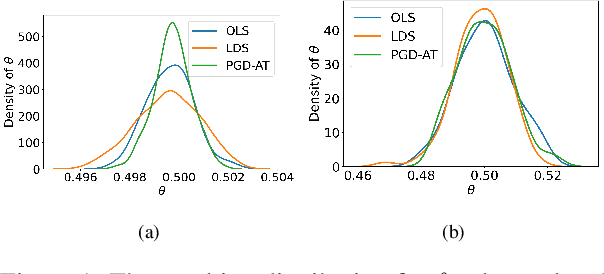

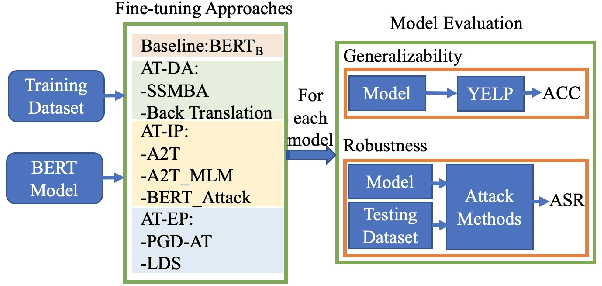
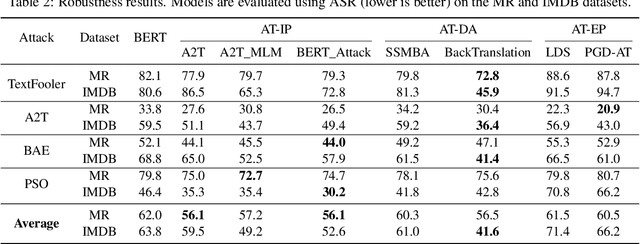
Adversarial training is widely acknowledged as the most effective defense against adversarial attacks. However, it is also well established that achieving both robustness and generalization in adversarially trained models involves a trade-off. The goal of this work is to provide an in depth comparison of different approaches for adversarial training in language models. Specifically, we study the effect of pre-training data augmentation as well as training time input perturbations vs. embedding space perturbations on the robustness and generalization of BERT-like language models. Our findings suggest that better robustness can be achieved by pre-training data augmentation or by training with input space perturbation. However, training with embedding space perturbation significantly improves generalization. A linguistic correlation analysis of neurons of the learned models reveal that the improved generalization is due to `more specialized' neurons. To the best of our knowledge, this is the first work to carry out a deep qualitative analysis of different methods of generating adversarial examples in adversarial training of language models.
Source Camera Attribution from Strongly Stabilized Videos
Nov 26, 2019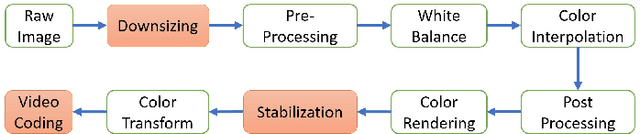
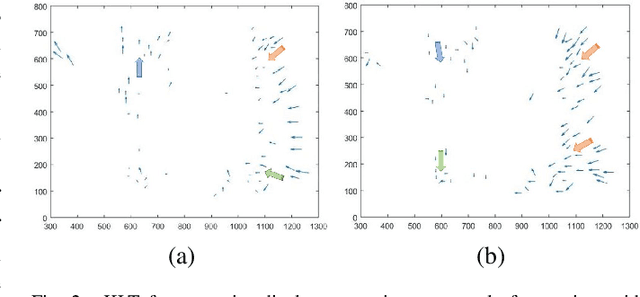
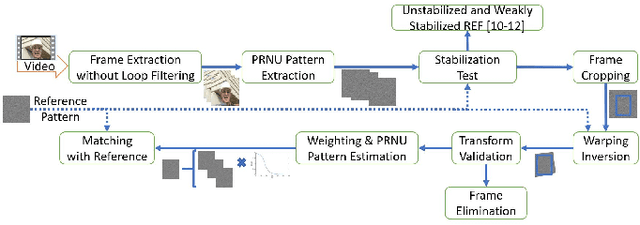
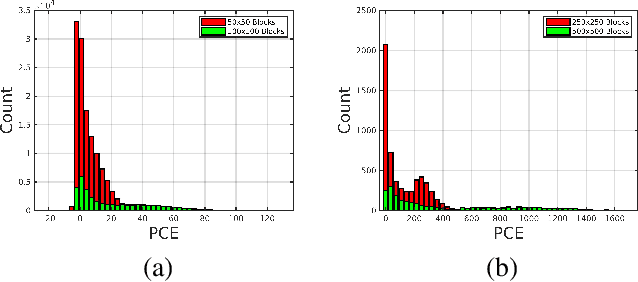
The in-camera image stabilization technology deployed by most cameras today poses one of the most significant challenges to photo-response non-uniformity based source camera attribution from videos. When performed digitally, stabilization involves cropping, warping, and inpainting of video frames to eliminate unwanted camera motion. Hence, successful attribution requires the inversion of these transformations in a blind manner. To address this challenge, we introduce a source camera verification method for videos that takes into account the spatially variant nature of stabilization transformations. Our method identifies transformations at a sub-frame level and incorporates a number of constraints to validate their correctness. The method also adopts a holistic approach in countering disruptive effects of other video generation steps, such as video coding and downsizing, for more reliable attribution. Tests performed on a public dataset of stabilized videos show that the proposed method improves attribution rate over existing methods by 17-19\% without a significant impact on false attribution rate.