 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal multi-class Parkinson disease classification using CNN and decision level fusion
Jul 06, 2023Parkinson disease is the second most common neurodegenerative disorder, as reported by the World Health Organization. In this paper, we propose a direct three-Class PD classification using two different modalities, namely, MRI and DTI. The three classes used for classification are PD, Scans Without Evidence of Dopamine Deficit and Healthy Control. We use white matter and gray matter from the MRI and fractional anisotropy and mean diffusivity from the DTI to achieve our goal. We train four separate CNNs on the above four types of data. At the decision level, the outputs of the four CNN models are fused with an optimal weighted average fusion technique. We achieve an accuracy of 95.53 percentage for the direct three class classification of PD, HC and SWEDD on the publicly available PPMI database. Extensive comparisons including a series of ablation studies clearly demonstrate the effectiveness of our proposed solution.
Moving Object Detection for Event-based vision using Graph Spectral Clustering
Sep 30, 2021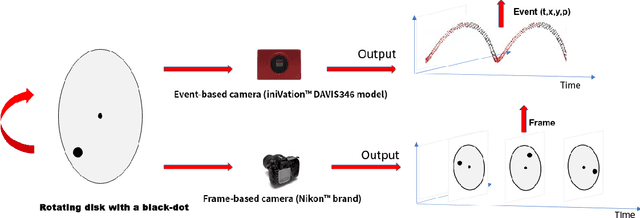
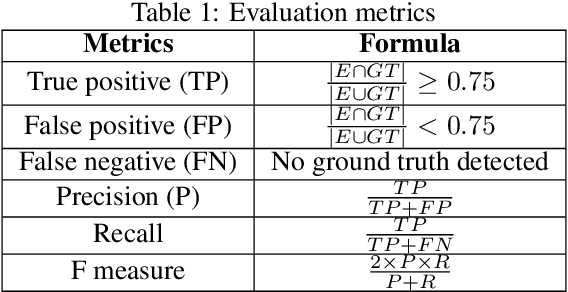
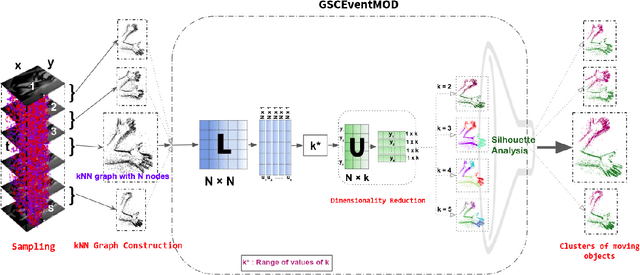

Moving object detection has been a central topic of discussion in computer vision for its wide range of applications like in self-driving cars, video surveillance, security, and enforcement. Neuromorphic Vision Sensors (NVS) are bio-inspired sensors that mimic the working of the human eye. Unlike conventional frame-based cameras, these sensors capture a stream of asynchronous 'events' that pose multiple advantages over the former, like high dynamic range, low latency, low power consumption, and reduced motion blur. However, these advantages come at a high cost, as the event camera data typically contains more noise and has low resolution. Moreover, as event-based cameras can only capture the relative changes in brightness of a scene, event data do not contain usual visual information (like texture and color) as available in video data from normal cameras. So, moving object detection in event-based cameras becomes an extremely challenging task. In this paper, we present an unsupervised Graph Spectral Clustering technique for Moving Object Detection in Event-based data (GSCEventMOD). We additionally show how the optimum number of moving objects can be automatically determined. Experimental comparisons on publicly available datasets show that the proposed GSCEventMOD algorithm outperforms a number of state-of-the-art techniques by a maximum margin of 30%.
Semantic Segmentation of Surface from Lidar Point Cloud
Sep 13, 2020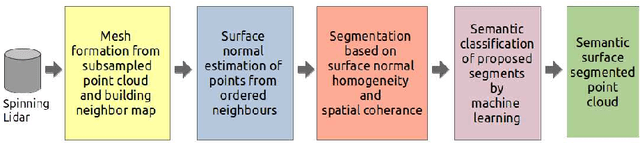
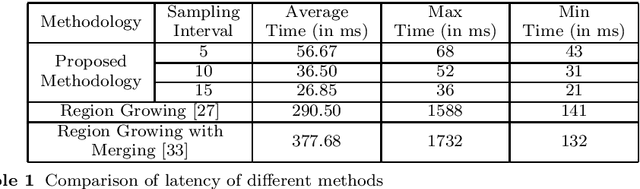
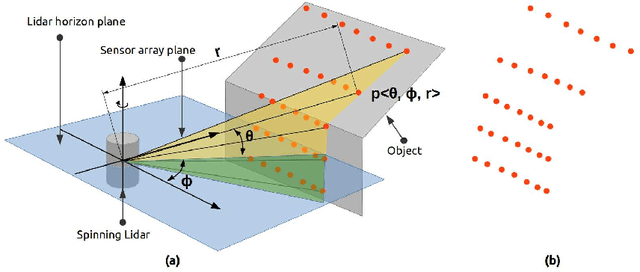
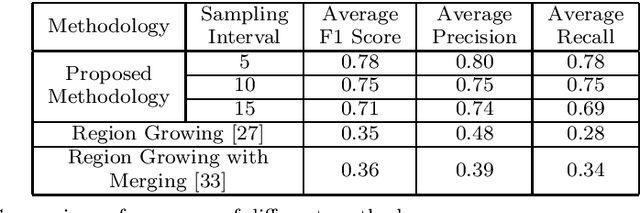
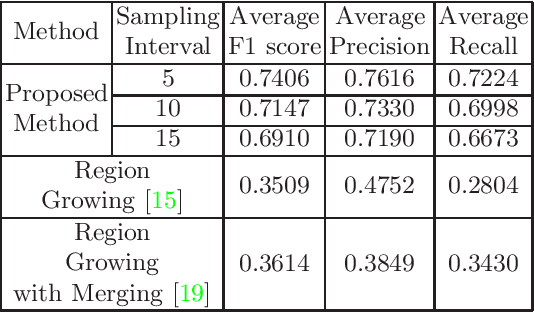
In the field of SLAM (Simultaneous Localization And Mapping) for robot navigation, mapping the environment is an important task. In this regard the Lidar sensor can produce near accurate 3D map of the environment in the format of point cloud, in real time. Though the data is adequate for extracting information related to SLAM, processing millions of points in the point cloud is computationally quite expensive. The methodology presented proposes a fast algorithm that can be used to extract semantically labelled surface segments from the cloud, in real time, for direct navigational use or higher level contextual scene reconstruction. First, a single scan from a spinning Lidar is used to generate a mesh of subsampled cloud points online. The generated mesh is further used for surface normal computation of those points on the basis of which surface segments are estimated. A novel descriptor to represent the surface segments is proposed and utilized to determine the surface class of the segments (semantic label) with the help of classifier. These semantic surface segments can be further utilized for geometric reconstruction of objects in the scene, or can be used for optimized trajectory planning by a robot. The proposed methodology is compared with number of point cloud segmentation methods and state of the art semantic segmentation methods to emphasize its efficacy in terms of speed and accuracy.
Fast Geometric Surface based Segmentation of Point Cloud from Lidar Data
May 06, 2020
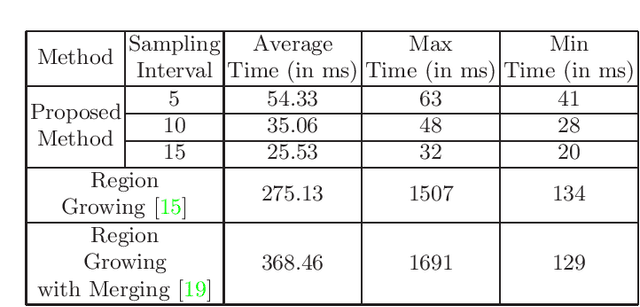
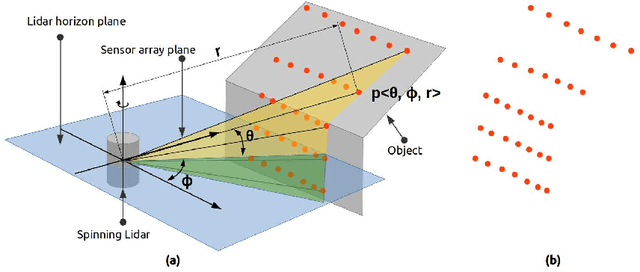
Mapping the environment has been an important task for robot navigation and Simultaneous Localization And Mapping (SLAM). LIDAR provides a fast and accurate 3D point cloud map of the environment which helps in map building. However, processing millions of points in the point cloud becomes a computationally expensive task. In this paper, a methodology is presented to generate the segmented surfaces in real time and these can be used in modeling the 3D objects. At first an algorithm is proposed for efficient map building from single shot data of spinning Lidar. It is based on fast meshing and sub-sampling. It exploits the physical design and the working principle of the spinning Lidar sensor. The generated mesh surfaces are then segmented by estimating the normal and considering their homogeneity. The segmented surfaces can be used as proposals for predicting geometrically accurate model of objects in the robots activity environment. The proposed methodology is compared with some popular point cloud segmentation methods to highlight the efficacy in terms of accuracy and speed.
* Accepted to PReMI 2019( Pattern Recognition and Machine Intelligence 2019 )
An Adaptive Training-less System for Anomaly Detection in Crowd Scenes
Jun 03, 2019

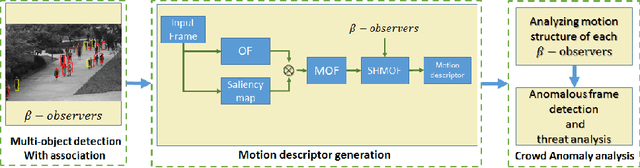
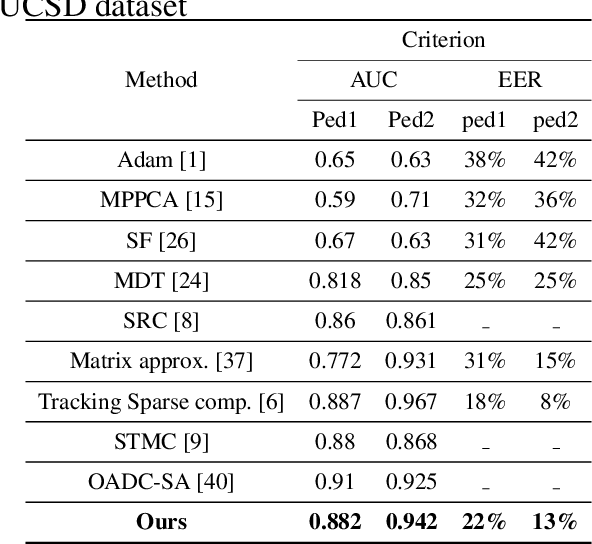
Anomaly detection in crowd videos has become a popular area of research for the computer vision community. Several existing methods generally perform a prior training about the scene with or without the use of labeled data. However, it is difficult to always guarantee the availability of prior data, especially, for scenarios like remote area surveillance. To address such challenge, we propose an adaptive training-less system capable of detecting anomaly on-the-fly while dynamically estimating and adjusting response based on certain parameters. This makes our system both training-less and adaptive in nature. Our pipeline consists of three main components, namely, adaptive 3D-DCT model for multi-object detection-based association, local motion structure description through saliency modulated optic flow, and anomaly detection based on earth movers distance (EMD). The proposed model, despite being training-free, is found to achieve comparable performance with several state-of-the-art methods on the publicly available UCSD, UMN, CHUK-Avenue and ShanghaiTech datasets.
An Iterative Spanning Forest Framework for Superpixel Segmentation
Jan 30, 2018
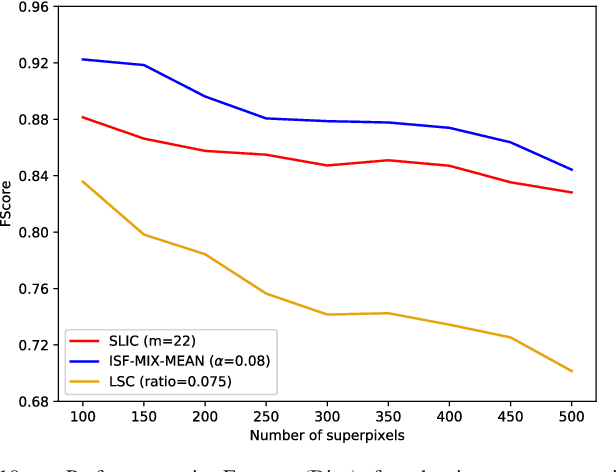
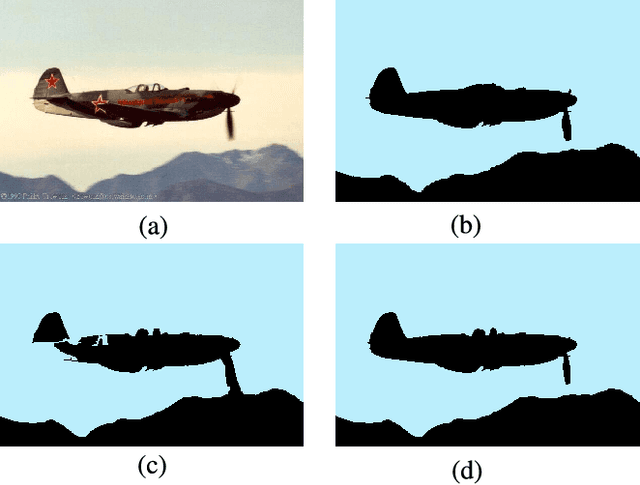

Superpixel segmentation has become an important research problem in image processing. In this paper, we propose an Iterative Spanning Forest (ISF) framework, based on sequences of Image Foresting Transforms, where one can choose i) a seed sampling strategy, ii) a connectivity function, iii) an adjacency relation, and iv) a seed pixel recomputation procedure to generate improved sets of connected superpixels (supervoxels in 3D) per iteration. The superpixels in ISF structurally correspond to spanning trees rooted at those seeds. We present five ISF methods to illustrate different choices of its components. These methods are compared with approaches from the state-of-the-art in effectiveness and efficiency. The experiments involve 2D and 3D datasets with distinct characteristics, and a high level application, named sky image segmentation. The theoretical properties of ISF are demonstrated in the supplementary material and the results show that some of its methods are competitive with or superior to the best baselines in effectiveness and efficiency.