 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tone of Awareness: Topic, Sentiment, and Toxicity Maps During Mental Health Month on TikTok
Jun 11, 2026Despite raising concerns about the mental health effects associated with the usage of TikTok, little is known about how related content is framed by creators and received by audiences. We collect the content of 28,341 TikTok videos and 80,130 comments from Mental Health Awareness Month (May) in 2023 and 2024 via the TikTok Research API, and study how the tone of awareness varies across topics and years. We characterize "tone" as the emotional and interpersonal framing of mental health discourse, operationalized through sentiment and toxicity measures. We extract topics from video text using BERTopic and log-odds keywords, then quantify topic-conditioned sentiment (XLM-T) and toxicity (Detoxify) separately for video transcriptions and comments. Sentiment captures the affective valence of content, while toxicity reflects the presence of harmful or abusive language. We find a stable set of recurring themes across years, spanning clinical conditions, emotional disclosure, self-care, and campaign-oriented content, with engagement highly skewed toward a small subset of topics. All sentiment and toxicity analyses are computed separately for video content and comments, allowing us to distinguish between content production and audience reception. Sentiment in videos is often negative for emotionally charged topics, while comments tend to shift toward more mixed or positive polarity, especially for suicide prevention. Toxicity is low in median overall, but exhibits longer-tailed outliers in comments than in videos that are more pronounced in comments and concentrated in specific topics (e.g., "Duet", "Suicide Prevention", and "Psychisch"). Overall, our results provide a topic-level decomposition of mental health discourse on TikTok during awareness-month campaigns.
OmniCount: Multi-label Object Counting with Semantic-Geometric Priors
Mar 14, 2024Object counting is pivotal for understanding the composition of scenes. Previously, this task was dominated by class-specific methods, which have gradually evolved into more adaptable class-agnostic strategies. However, these strategies come with their own set of limitations, such as the need for manual exemplar input and multiple passes for multiple categories, resulting in significant inefficiencies. This paper introduces a new, more practical approach enabling simultaneous counting of multiple object categories using an open vocabulary framework. Our solution, OmniCount, stands out by using semantic and geometric insights from pre-trained models to count multiple categories of objects as specified by users, all without additional training. OmniCount distinguishes itself by generating precise object masks and leveraging point prompts via the Segment Anything Model for efficient counting. To evaluate OmniCount, we created the OmniCount-191 benchmark, a first-of-its-kind dataset with multi-label object counts, including points, bounding boxes, and VQA annotations. Our comprehensive evaluation in OmniCount-191, alongside other leading benchmarks, demonstrates OmniCount's exceptional performance, significantly outpacing existing solutions and heralding a new era in object counting technology.
Actor-agnostic Multi-label Action Recognition with Multi-modal Query
Aug 08, 2023



Existing action recognition methods are typically actor-specific due to the intrinsic topological and apparent differences among the actors. This requires actor-specific pose estimation (e.g., humans vs. animals), leading to cumbersome model design complexity and high maintenance costs. Moreover, they often focus on learning the visual modality alone and single-label classification whilst neglecting other available information sources (e.g., class name text) and the concurrent occurrence of multiple actions. To overcome these limitations, we propose a new approach called 'actor-agnostic multi-modal multi-label action recognition,' which offers a unified solution for various types of actors, including humans and animals. We further formulate a novel Multi-modal Semantic Query Network (MSQNet) model in a transformer-based object detection framework (e.g., DETR), characterized by leveraging visual and textual modalities to represent the action classes better. The elimination of actor-specific model designs is a key advantage, as it removes the need for actor pose estimation altogether. Extensive experiments on five publicly available benchmarks show that our MSQNet consistently outperforms the prior arts of actor-specific alternatives on human and animal single- and multi-label action recognition tasks by up to 50%. Code will be released at https://github.com/mondalanindya/MSQNet.
Time-varying Signals Recovery via Graph Neural Networks
Feb 22, 2023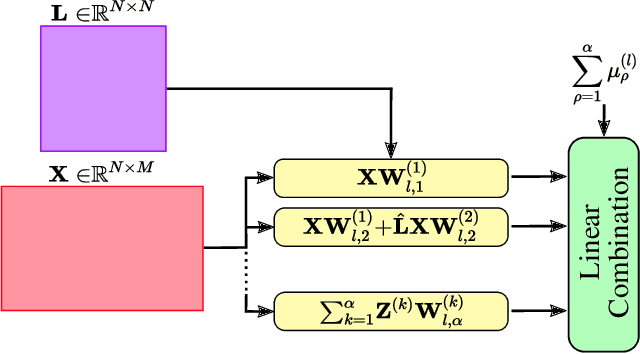
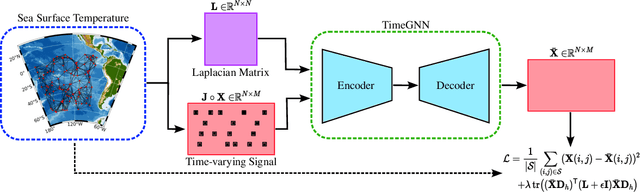
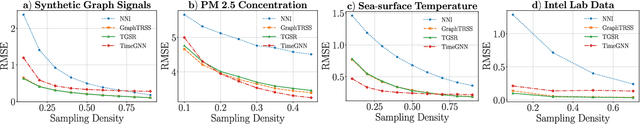

The recovery of time-varying graph signals is a fundamental problem with numerous applications in sensor networks and forecasting in time series. Effectively capturing the spatio-temporal information in these signals is essential for the downstream tasks. Previous studies have used the smoothness of the temporal differences of such graph signals as an initial assumption. Nevertheless, this smoothness assumption could result in a degradation of performance in the corresponding application when the prior does not hold. In this work, we relax the requirement of this hypothesis by including a learning module. We propose a Time Graph Neural Network (TimeGNN) for the recovery of time-varying graph signals. Our algorithm uses an encoder-decoder architecture with a specialized loss composed of a mean squared error function and a Sobolev smoothness operator.TimeGNN shows competitive performance against previous methods in real datasets.
Recovery of Missing Sensor Data by Reconstructing Time-varying Graph Signals
Mar 01, 2022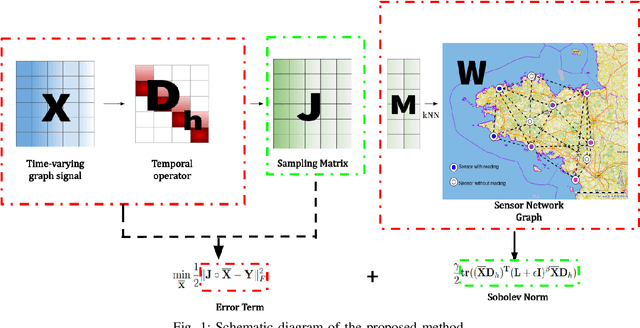
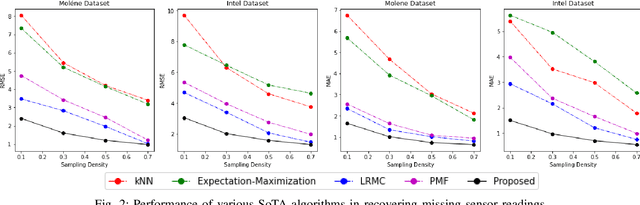
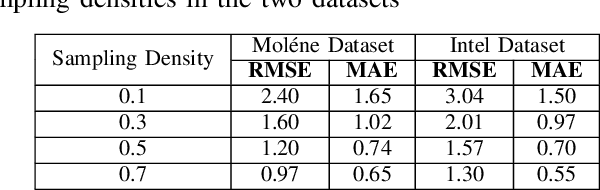
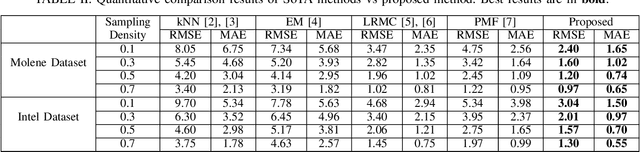
Wireless sensor networks are among the most promising technologies of the current era because of their small size, lower cost, and ease of deployment. With the increasing number of wireless sensors, the probability of generating missing data also rises. This incomplete data could lead to disastrous consequences if used for decision-making. There is rich literature dealing with this problem. However, most approaches show performance degradation when a sizable amount of data is lost. Inspired by the emerging field of graph signal processing, this paper performs a new study of a Sobolev reconstruction algorithm in wireless sensor networks. Experimental comparisons on several publicly available datasets demonstrate that the algorithm surpasses multiple state-of-the-art techniques by a maximum margin of 54%. We further show that this algorithm consistently retrieves the missing data even during massive data loss situations.
Moving Object Detection for Event-based Vision using k-means Clustering
Oct 01, 2021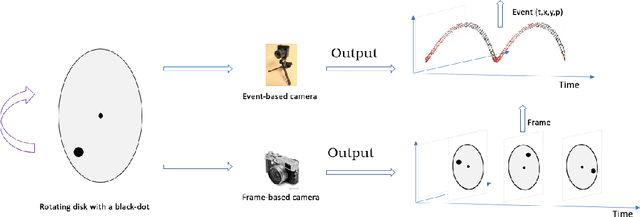
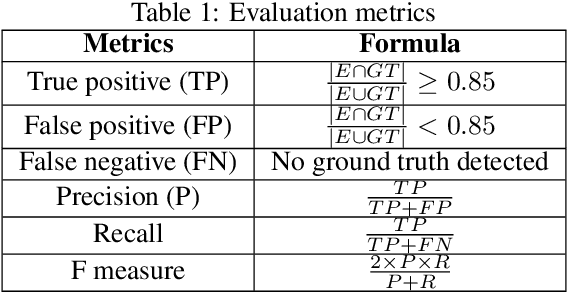

Moving object detection is important in computer vision. Event-based cameras are bio-inspired cameras that work by mimicking the working of the human eye. These cameras have multiple advantages over conventional frame-based cameras, like reduced latency, HDR, reduced motion blur during high motion, low power consumption, etc. In spite of these advantages, event-based cameras are noise-sensitive and have low resolution. Moreover, the task of moving object detection in these cameras is difficult, as event-based sensors lack useful visual features like texture and color. In this paper, we investigate the application of the k-means clustering technique in detecting moving objects in event-based data.
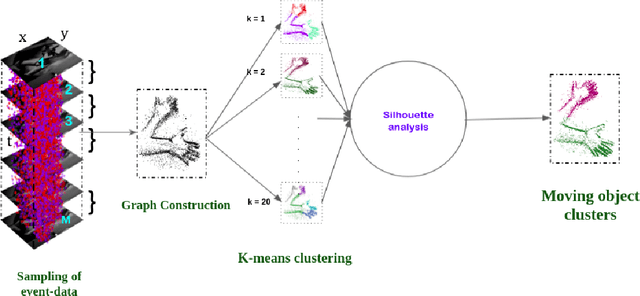
Moving Object Detection for Event-based vision using Graph Spectral Clustering
Sep 30, 2021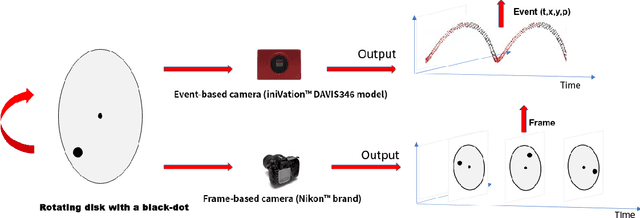
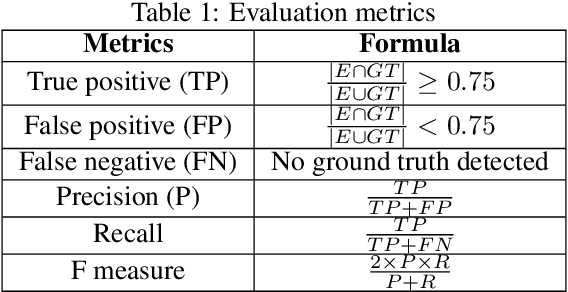
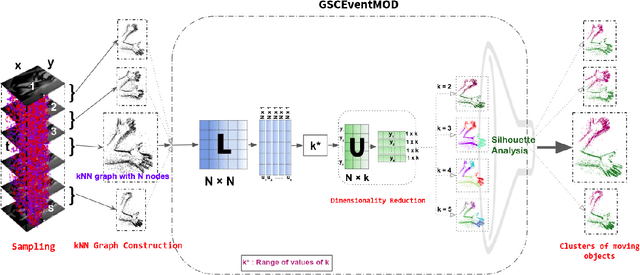

Moving object detection has been a central topic of discussion in computer vision for its wide range of applications like in self-driving cars, video surveillance, security, and enforcement. Neuromorphic Vision Sensors (NVS) are bio-inspired sensors that mimic the working of the human eye. Unlike conventional frame-based cameras, these sensors capture a stream of asynchronous 'events' that pose multiple advantages over the former, like high dynamic range, low latency, low power consumption, and reduced motion blur. However, these advantages come at a high cost, as the event camera data typically contains more noise and has low resolution. Moreover, as event-based cameras can only capture the relative changes in brightness of a scene, event data do not contain usual visual information (like texture and color) as available in video data from normal cameras. So, moving object detection in event-based cameras becomes an extremely challenging task. In this paper, we present an unsupervised Graph Spectral Clustering technique for Moving Object Detection in Event-based data (GSCEventMOD). We additionally show how the optimum number of moving objects can be automatically determined. Experimental comparisons on publicly available datasets show that the proposed GSCEventMOD algorithm outperforms a number of state-of-the-art techniques by a maximum margin of 30%.