 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViM-Disparity: Bridging the Gap of Speed, Accuracy and Memory for Disparity Map Generation
Dec 21, 2024



In this work we propose a Visual Mamba (ViM) based architecture, to dissolve the existing trade-off for real-time and accurate model with low computation overhead for disparity map generation (DMG). Moreover, we proposed a performance measure that can jointly evaluate the inference speed, computation overhead and the accurateness of a DMG model.
KDC-MAE: Knowledge Distilled Contrastive Mask Auto-Encoder
Nov 19, 2024



In this work, we attempted to extend the thought and showcase a way forward for the Self-supervised Learning (SSL) learning paradigm by combining contrastive learning, self-distillation (knowledge distillation) and masked data modelling, the three major SSL frameworks, to learn a joint and coordinated representation. The proposed technique of SSL learns by the collaborative power of different learning objectives of SSL. Hence to jointly learn the different SSL objectives we proposed a new SSL architecture KDC-MAE, a complementary masking strategy to learn the modular correspondence, and a weighted way to combine them coordinately. Experimental results conclude that the contrastive masking correspondence along with the KD learning objective has lent a hand to performing better learning for multiple modalities over multiple tasks.
Recent Advancement in 3D Biometrics using Monocular Camera
Jan 05, 2024Recent literature has witnessed significant interest towards 3D biometrics employing monocular vision for robust authentication methods. Motivated by this, in this work we seek to provide insight on recent development in the area of 3D biometrics employing monocular vision. We present the similarity and dissimilarity of 3D monocular biometrics and classical biometrics, listing the strengths and challenges. Further, we provide an overview of recent techniques in 3D biometrics with monocular vision, as well as application systems adopted by the industry. Finally, we discuss open research problems in this area of research
Enhancing 3D-Air Signature by Pen Tip Tail Trajectory Awareness: Dataset and Featuring by Novel Spatio-temporal CNN
Jan 05, 2024This work proposes a novel process of using pen tip and tail 3D trajectory for air signature. To acquire the trajectories we developed a new pen tool and a stereo camera was used. We proposed SliT-CNN, a novel 2D spatial-temporal convolutional neural network (CNN) for better featuring of the air signature. In addition, we also collected an air signature dataset from $45$ signers. Skilled forgery signatures per user are also collected. A detailed benchmarking of the proposed dataset using existing techniques and proposed CNN on existing and proposed dataset exhibit the effectiveness of our methodology.
Semantic Segmentation of Surface from Lidar Point Cloud
Sep 13, 2020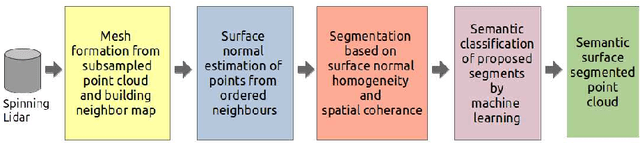
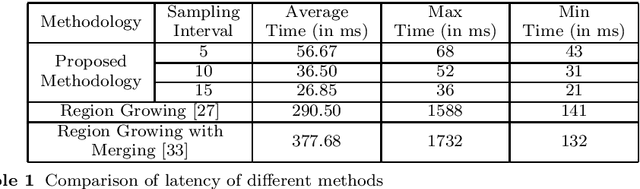
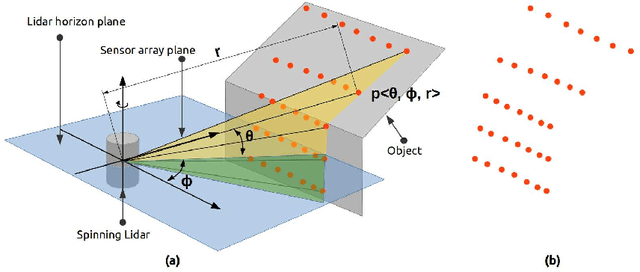
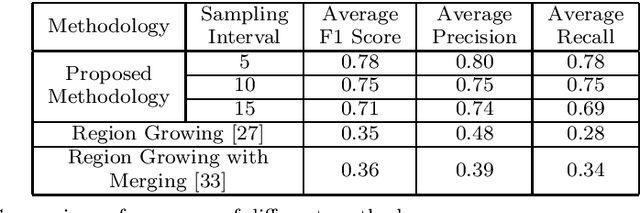
In the field of SLAM (Simultaneous Localization And Mapping) for robot navigation, mapping the environment is an important task. In this regard the Lidar sensor can produce near accurate 3D map of the environment in the format of point cloud, in real time. Though the data is adequate for extracting information related to SLAM, processing millions of points in the point cloud is computationally quite expensive. The methodology presented proposes a fast algorithm that can be used to extract semantically labelled surface segments from the cloud, in real time, for direct navigational use or higher level contextual scene reconstruction. First, a single scan from a spinning Lidar is used to generate a mesh of subsampled cloud points online. The generated mesh is further used for surface normal computation of those points on the basis of which surface segments are estimated. A novel descriptor to represent the surface segments is proposed and utilized to determine the surface class of the segments (semantic label) with the help of classifier. These semantic surface segments can be further utilized for geometric reconstruction of objects in the scene, or can be used for optimized trajectory planning by a robot. The proposed methodology is compared with number of point cloud segmentation methods and state of the art semantic segmentation methods to emphasize its efficacy in terms of speed and accuracy.
Fast Geometric Surface based Segmentation of Point Cloud from Lidar Data
May 06, 2020
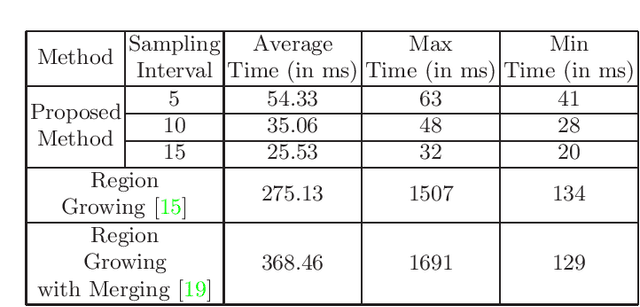
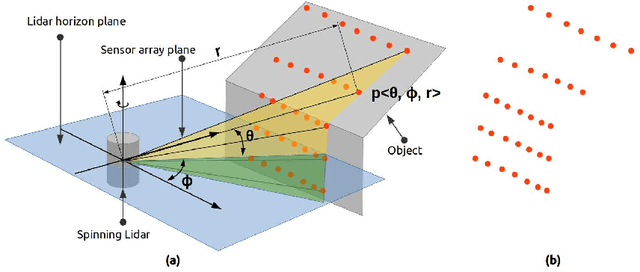
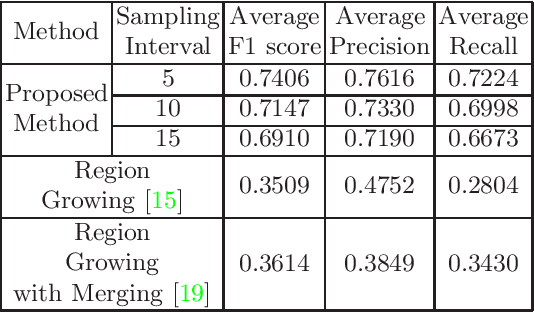
Mapping the environment has been an important task for robot navigation and Simultaneous Localization And Mapping (SLAM). LIDAR provides a fast and accurate 3D point cloud map of the environment which helps in map building. However, processing millions of points in the point cloud becomes a computationally expensive task. In this paper, a methodology is presented to generate the segmented surfaces in real time and these can be used in modeling the 3D objects. At first an algorithm is proposed for efficient map building from single shot data of spinning Lidar. It is based on fast meshing and sub-sampling. It exploits the physical design and the working principle of the spinning Lidar sensor. The generated mesh surfaces are then segmented by estimating the normal and considering their homogeneity. The segmented surfaces can be used as proposals for predicting geometrically accurate model of objects in the robots activity environment. The proposed methodology is compared with some popular point cloud segmentation methods to highlight the efficacy in terms of accuracy and speed.
* Accepted to PReMI 2019( Pattern Recognition and Machine Intelligence 2019 )