 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Bird Species Recognition by Learning from Field Guides
Jun 03, 2022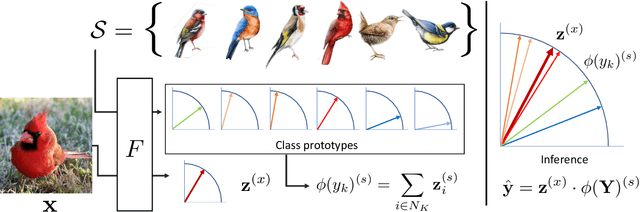
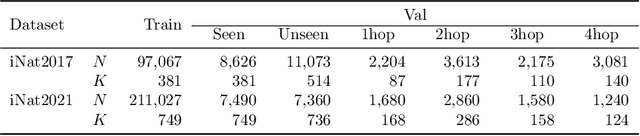
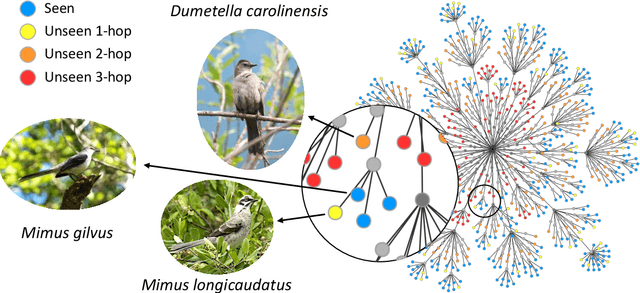

We exploit field guides to learn bird species recognition, in particular zero-shot recognition of unseen species. The illustrations contained in field guides deliberately focus on discriminative properties of a species, and can serve as side information to transfer knowledge from seen to unseen classes. We study two approaches: (1) a contrastive encoding of illustrations that can be fed into zero-shot learning schemes; and (2) a novel method that leverages the fact that illustrations are also images and as such structurally more similar to photographs than other kinds of side information. Our results show that illustrations from field guides, which are readily available for a wide range of species, are indeed a competitive source of side information. On the iNaturalist2021 subset, we obtain a harmonic mean from 749 seen and 739 unseen classes greater than $45\%$ (@top-10) and $15\%$ (@top-1). Which shows that field guides are a valuable option for challenging real-world scenarios with many species.
Mapping oil palm density at country scale: An active learning approach
May 24, 2021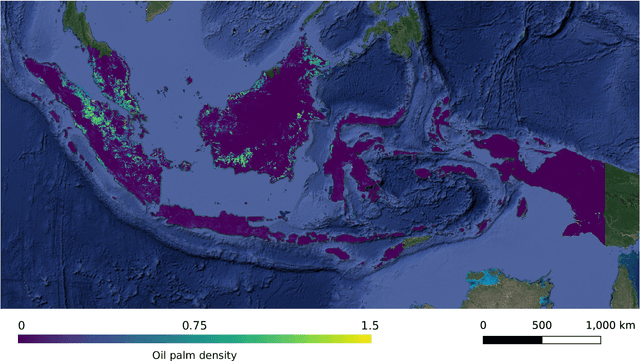

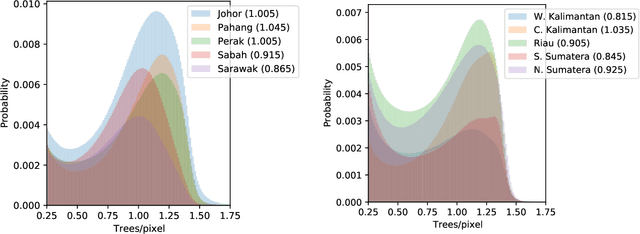
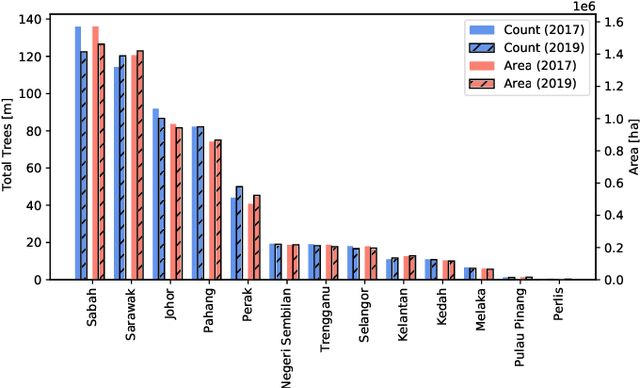
Accurate mapping of oil palm is important for understanding its past and future impact on the environment. We propose to map and count oil palms by estimating tree densities per pixel for large-scale analysis. This allows for fine-grained analysis, for example regarding different planting patterns. To that end, we propose a new, active deep learning method to estimate oil palm density at large scale from Sentinel-2 satellite images, and apply it to generate complete maps for Malaysia and Indonesia. What makes the regression of oil palm density challenging is the need for representative reference data that covers all relevant geographical conditions across a large territory. Specifically for density estimation, generating reference data involves counting individual trees. To keep the associated labelling effort low we propose an active learning (AL) approach that automatically chooses the most relevant samples to be labelled. Our method relies on estimates of the epistemic model uncertainty and of the diversity among samples, making it possible to retrieve an entire batch of relevant samples in a single iteration. Moreover, our algorithm has linear computational complexity and is easily parallelisable to cover large areas. We use our method to compute the first oil palm density map with $10\,$m Ground Sampling Distance (GSD) , for all of Indonesia and Malaysia and for two different years, 2017 and 2019. The maps have a mean absolute error of $\pm$7.3 trees/$ha$, estimated from an independent validation set. We also analyse density variations between different states within a country and compare them to official estimates. According to our estimates there are, in total, $>1.2$ billion oil palms in Indonesia covering $>$15 million $ha$, and $>0.5$ billion oil palms in Malaysia covering $>6$ million $ha$.