 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Selection Bias in Statistical Studies With Amortized Bayesian Inference
Apr 20, 2026Selection bias arises when the probability that an observation enters a dataset depends on variables related to the quantities of interest, leading to systematic distortions in estimation and uncertainty quantification. For example, in epidemiological or survey settings, individuals with certain outcomes may be more likely to be included, resulting in biased prevalence estimates with potentially substantial downstream impact. Classical corrections, such as inverse-probability weighting or explicit likelihood-based models of the selection process, rely on tractable likelihoods, which limits their applicability in complex stochastic models with latent dynamics or high-dimensional structure. Simulation-based inference enables Bayesian analysis without tractable likelihoods but typically assumes missingness at random and thus fails when selection depends on unobserved outcomes or covariates. Here, we develop a bias-aware simulation-based inference framework that explicitly incorporates selection into neural posterior estimation. By embedding the selection mechanism directly into the generative simulator, the approach enables amortized Bayesian inference without requiring tractable likelihoods. This recasting of selection bias as part of the simulation process allows us to both obtain debiased estimates and explicitly test for the presence of bias. The framework integrates diagnostics to detect discrepancies between simulated and observed data and to assess posterior calibration. The method recovers well-calibrated posterior distributions across three statistical applications with diverse selection mechanisms, including settings in which likelihood-based approaches yield biased estimates. These results recast the correction of selection bias as a simulation problem and establish simulation-based inference as a practical and testable strategy for parameter estimation under selection bias.
Cross-modal feature fusion for robust point cloud registration with ambiguous geometry
May 19, 2025



Point cloud registration has seen significant advancements with the application of deep learning techniques. However, existing approaches often overlook the potential of integrating radiometric information from RGB images. This limitation reduces their effectiveness in aligning point clouds pairs, especially in regions where geometric data alone is insufficient. When used effectively, radiometric information can enhance the registration process by providing context that is missing from purely geometric data. In this paper, we propose CoFF, a novel Cross-modal Feature Fusion method that utilizes both point cloud geometry and RGB images for pairwise point cloud registration. Assuming that the co-registration between point clouds and RGB images is available, CoFF explicitly addresses the challenges where geometric information alone is unclear, such as in regions with symmetric similarity or planar structures, through a two-stage fusion of 3D point cloud features and 2D image features. It incorporates a cross-modal feature fusion module that assigns pixel-wise image features to 3D input point clouds to enhance learned 3D point features, and integrates patch-wise image features with superpoint features to improve the quality of coarse matching. This is followed by a coarse-to-fine matching module that accurately establishes correspondences using the fused features. We extensively evaluate CoFF on four common datasets: 3DMatch, 3DLoMatch, IndoorLRS, and the recently released ScanNet++ datasets. In addition, we assess CoFF on specific subset datasets containing geometrically ambiguous cases. Our experimental results demonstrate that CoFF achieves state-of-the-art registration performance across all benchmarks, including remarkable registration recalls of 95.9% and 81.6% on the widely-used 3DMatch and 3DLoMatch datasets, respectively...(Truncated to fit arXiv abstract length)
DEFLOW: Self-supervised 3D Motion Estimation of Debris Flow
Apr 05, 2023Existing work on scene flow estimation focuses on autonomous driving and mobile robotics, while automated solutions are lacking for motion in nature, such as that exhibited by debris flows. We propose DEFLOW, a model for 3D motion estimation of debris flows, together with a newly captured dataset. We adopt a novel multi-level sensor fusion architecture and self-supervision to incorporate the inductive biases of the scene. We further adopt a multi-frame temporal processing module to enable flow speed estimation over time. Our model achieves state-of-the-art optical flow and depth estimation on our dataset, and fully automates the motion estimation for debris flows. The source code and dataset are available at project page.
Dynamic 3D Scene Analysis by Point Cloud Accumulation
Jul 25, 2022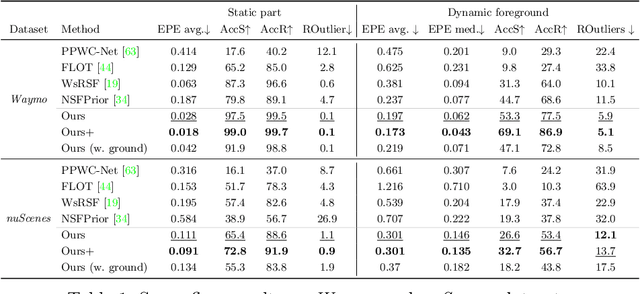


Multi-beam LiDAR sensors, as used on autonomous vehicles and mobile robots, acquire sequences of 3D range scans ("frames"). Each frame covers the scene sparsely, due to limited angular scanning resolution and occlusion. The sparsity restricts the performance of downstream processes like semantic segmentation or surface reconstruction. Luckily, when the sensor moves, frames are captured from a sequence of different viewpoints. This provides complementary information and, when accumulated in a common scene coordinate frame, yields a denser sampling and a more complete coverage of the underlying 3D scene. However, often the scanned scenes contain moving objects. Points on those objects are not correctly aligned by just undoing the scanner's ego-motion. In the present paper, we explore multi-frame point cloud accumulation as a mid-level representation of 3D scan sequences, and develop a method that exploits inductive biases of outdoor street scenes, including their geometric layout and object-level rigidity. Compared to state-of-the-art scene flow estimators, our proposed approach aims to align all 3D points in a common reference frame correctly accumulating the points on the individual objects. Our approach greatly reduces the alignment errors on several benchmark datasets. Moreover, the accumulated point clouds benefit high-level tasks like surface reconstruction.
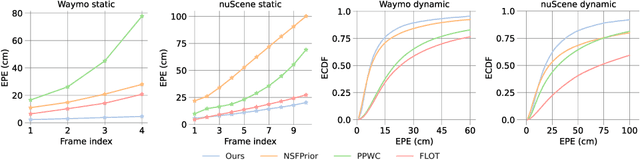
Weakly Supervised Learning of Rigid 3D Scene Flow
Feb 17, 2021
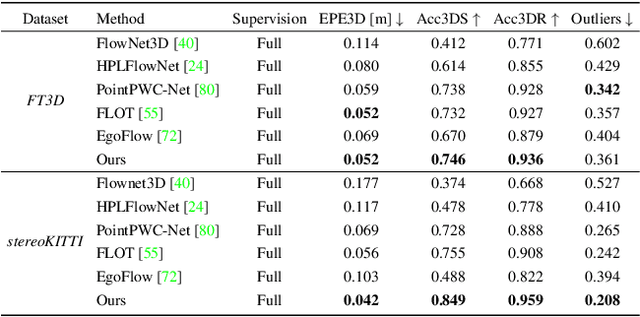

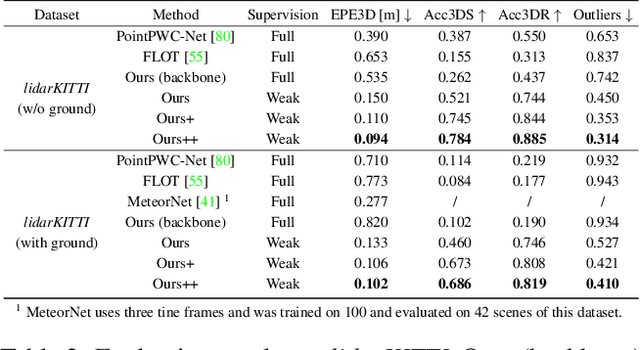
We propose a data-driven scene flow estimation algorithm exploiting the observation that many 3D scenes can be explained by a collection of agents moving as rigid bodies. At the core of our method lies a deep architecture able to reason at the \textbf{object-level} by considering 3D scene flow in conjunction with other 3D tasks. This object level abstraction, enables us to relax the requirement for dense scene flow supervision with simpler binary background segmentation mask and ego-motion annotations. Our mild supervision requirements make our method well suited for recently released massive data collections for autonomous driving, which do not contain dense scene flow annotations. As output, our model provides low-level cues like pointwise flow and higher-level cues such as holistic scene understanding at the level of rigid objects. We further propose a test-time optimization refining the predicted rigid scene flow. We showcase the effectiveness and generalization capacity of our method on four different autonomous driving datasets. We release our source code and pre-trained models under \url{github.com/zgojcic/Rigid3DSceneFlow}.
PREDATOR: Registration of 3D Point Clouds with Low Overlap
Nov 25, 2020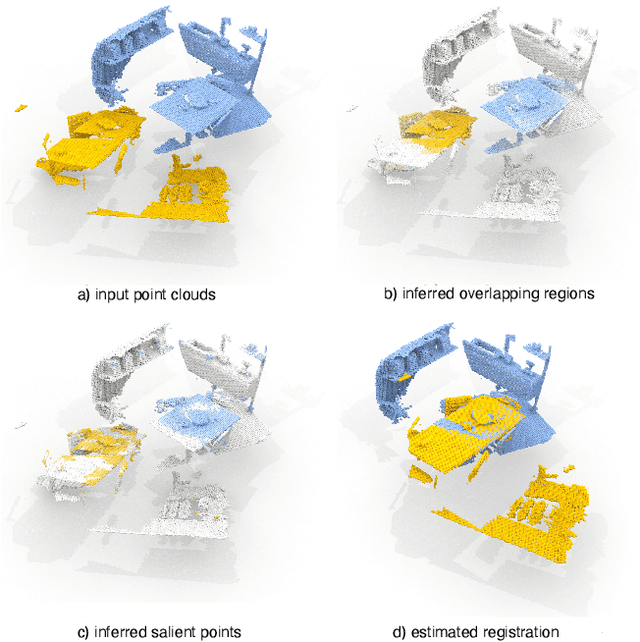
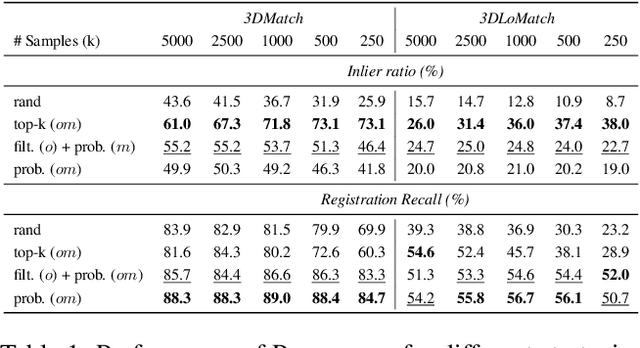
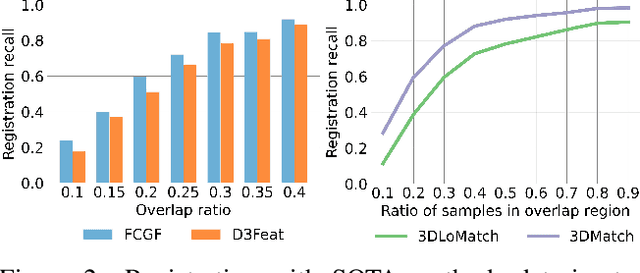
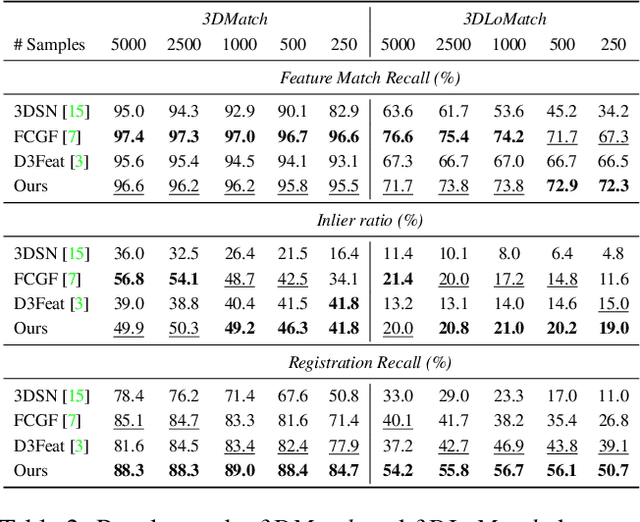
We introduce PREDATOR, a model for pairwise point-cloud registration with deep attention to the overlap region. Different from previous work, our model is specifically designed to handle (also) point-cloud pairs with low overlap. Its key novelty is an overlap-attention block for early information exchange between the latent encodings of the two point clouds. In this way the subsequent decoding of the latent representations into per-point features is conditioned on the respective other point cloud, and thus can predict which points are not only salient, but also lie in the overlap region between the two point clouds. The ability to focus on points that are relevant for matching greatly improves performance: PREDATOR raises the rate of successful registrations by more than 20% in the low-overlap scenario, and also sets a new state of the art for the 3DMatch benchmark with 89% registration recall. Source code and pre-trained models will be available at https://github.com/ShengyuH/OverlapPredator.
An iterative scheme for feature based positioning using a weighted dissimilarity measure
May 30, 2019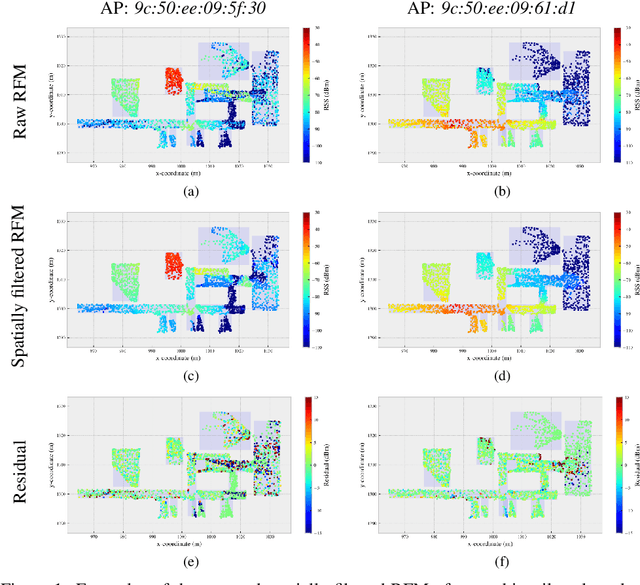

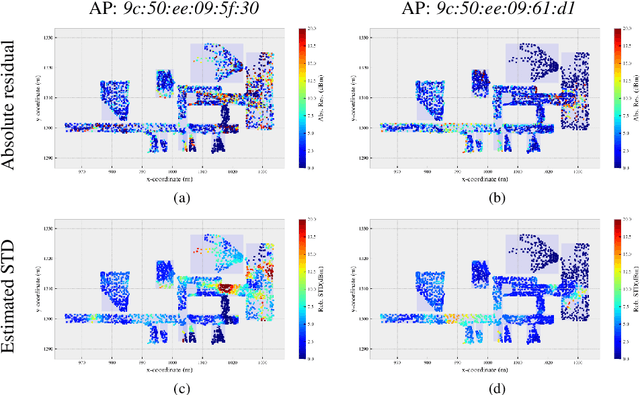
We propose an iterative scheme for feature-based positioning using a new weighted dissimilarity measure with the goal of reducing the impact of large errors among the measured or modeled features. The weights are computed from the location-dependent standard deviations of the features and stored as part of the reference fingerprint map (RFM). Spatial filtering and kernel smoothing of the kinematically collected raw data allow efficiently estimating the standard deviations during RFM generation. In the positioning stage, the weights control the contribution of each feature to the dissimilarity measure, which in turn quantifies the difference between the set of online measured features and the fingerprints stored in the RFM. Features with little variability contribute more to the estimated position than features with high variability. Iterations are necessary because the variability depends on the location, and the location is initially unknown when estimating the position. Using real WiFi signal strength data from extended test measurements with ground truth in an office building, we show that the standard deviations of these features vary considerably within the region of interest and are neither simple functions of the signal strength nor of the distances from the corresponding access points. This is the motivation to include the empirical standard deviations in the RFM. We then analyze the deviations of the estimated positions with and without the location-dependent weighting. In the present example the maximum radial positioning error from ground truth are reduced by 40% comparing to kNN without the weighted dissimilarity measure.
The Perfect Match: 3D Point Cloud Matching with Smoothed Densities
Nov 16, 2018

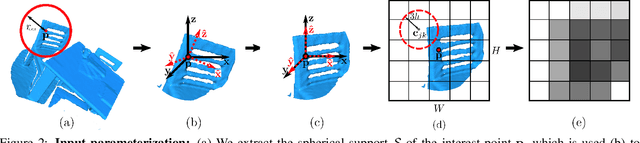

We propose 3DSmoothNet, a full workflow to match 3D point clouds with a siamese deep learning architecture and fully convolutional layers using a voxelized smoothed density value (SDV) representation. The latter is computed per interest point and aligned to the local reference frame (LRF) to achieve rotation invariance. Our compact, learned, rotation invariant 3D point cloud descriptor achieves 94.9% average recall on the 3DMatch benchmark data set, outperforming the state-of-the-art by more than 20 percent points with only 32 output dimensions. This very low output dimension allows for near real-time correspondence search with 0.1 ms per feature point on a standard PC. Our approach is sensor- and scene-agnostic because of SDV, LRF and learning highly descriptive features with fully convolutional layers. We show that 3DSmoothNet trained only on RGB-D indoor scenes of buildings achieves 79.0% average recall on laser scans of outdoor vegetation, more than double the performance of our closest, learningbased competitors.
CDM: Compound dissimilarity measure and an application to fingerprinting-based positioning
Jun 26, 2018

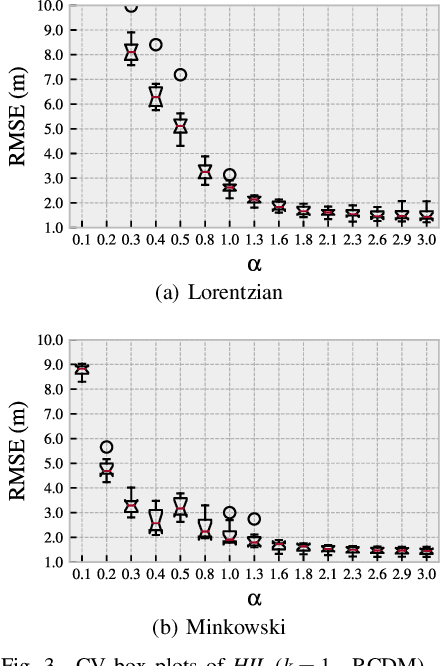
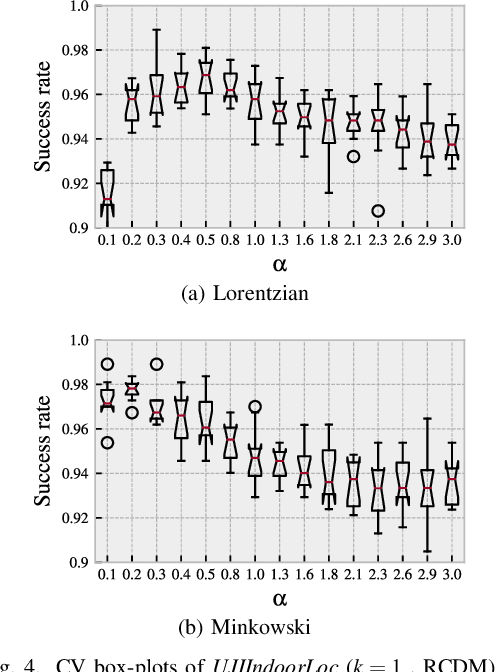
A non-vector-based dissimilarity measure is proposed by combining vector-based distance metrics and set operations. This proposed compound dissimilarity measure (CDM) is applicable to quantify similarity of collections of attribute/feature pairs where not all attributes are present in all collections. This is a typical challenge in the context of e.g., fingerprinting-based positioning (FbP). Compared to vector-based distance metrics (e.g., Minkowski), the merits of the proposed CDM are i) the data do not need to be converted to vectors of equal dimension, ii) shared and unshared attributes can be weighted differently within the assessment, and iii) additional degrees of freedom within the measure allow to adapt its properties to application needs in a data-driven way. We indicate the validity of the proposed CDM by demonstrating the improvements of the positioning performance of fingerprinting-based WLAN indoor positioning using four different datasets, three of them publicly available. When processing these datasets using CDM instead of conventional distance metrics the accuracy of identifying buildings and floors improves by about 5% on average. The 2d positioning errors in terms of root mean squared error (RMSE) are reduced by a factor of two, and the percentage of position solutions with less than 2m error improves by over 10%.
Jaccard analysis and LASSO-based feature selection for location fingerprinting with limited computational complexity
Nov 21, 2017

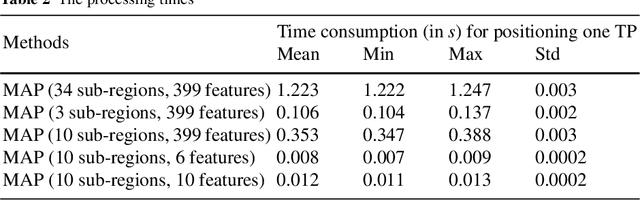
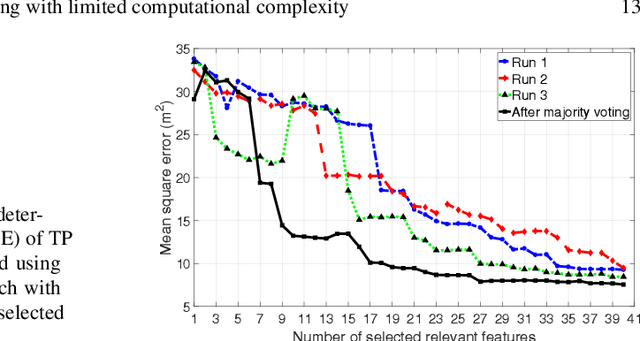
We propose an approach to reduce both computational complexity and data storage requirements for the online positioning stage of a fingerprinting-based indoor positioning system (FIPS) by introducing segmentation of the region of interest (RoI) into sub-regions, sub-region selection using a modified Jaccard index, and feature selection based on randomized least absolute shrinkage and selection operator (LASSO). We implement these steps into a Bayesian framework of position estimation using the maximum a posteriori (MAP) principle. An additional benefit of these steps is that the time for estimating the position, and the required data storage are virtually independent of the size of the RoI and of the total number of available features within the RoI. Thus the proposed steps facilitate application of FIPS to large areas. Results of an experimental analysis using real data collected in an office building using a Nexus 6P smart phone as user device and a total station for providing position ground truth corroborate the expected performance of the proposed approach. The positioning accuracy obtained by only processing 10 automatically identified features instead of all available ones and limiting position estimation to 10 automatically identified sub-regions instead of the entire RoI is equivalent to processing all available data. In the chosen example, 50% of the errors are less than 1.8 m and 90% are less than 5 m. However, the computation time using the automatically identified subset of data is only about 1% of that required for processing the entire data set.