 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTT-NF: Tensor Train Neural Fields
Sep 30, 2022

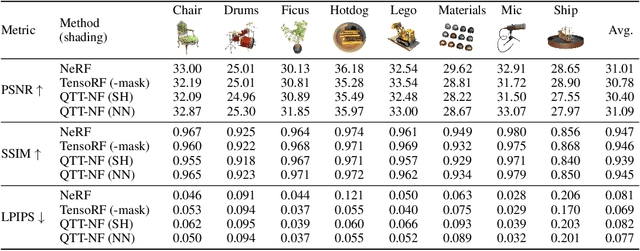

Learning neural fields has been an active topic in deep learning research, focusing, among other issues, on finding more compact and easy-to-fit representations. In this paper, we introduce a novel low-rank representation termed Tensor Train Neural Fields (TT-NF) for learning neural fields on dense regular grids and efficient methods for sampling from them. Our representation is a TT parameterization of the neural field, trained with backpropagation to minimize a non-convex objective. We analyze the effect of low-rank compression on the downstream task quality metrics in two settings. First, we demonstrate the efficiency of our method in a sandbox task of tensor denoising, which admits comparison with SVD-based schemes designed to minimize reconstruction error. Furthermore, we apply the proposed approach to Neural Radiance Fields, where the low-rank structure of the field corresponding to the best quality can be discovered only through learning.
T4DT: Tensorizing Time for Learning Temporal 3D Visual Data
Aug 02, 2022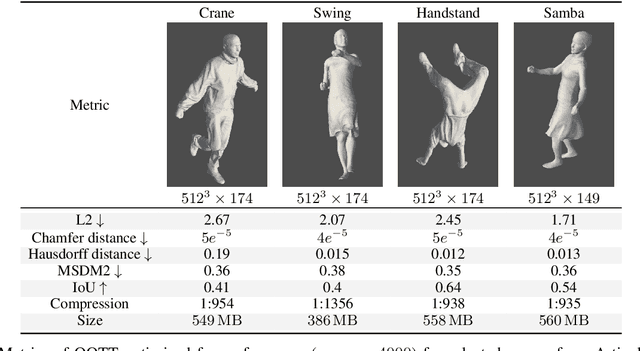

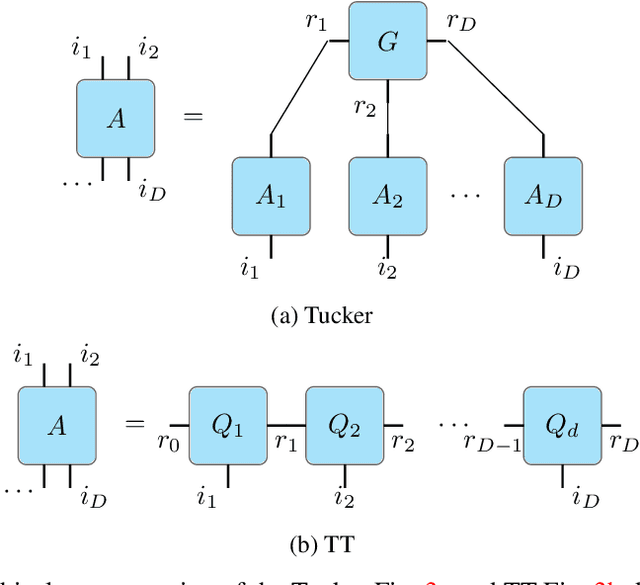
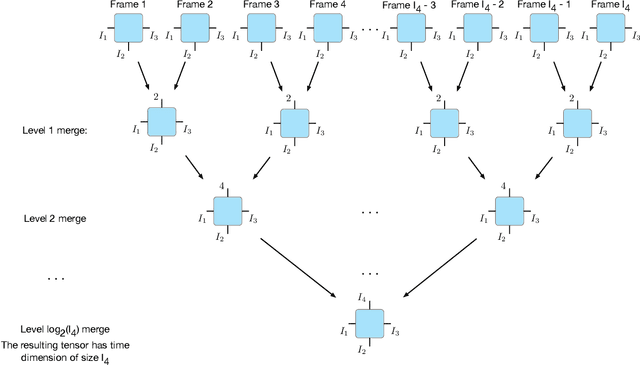
Unlike 2D raster images, there is no single dominant representation for 3D visual data processing. Different formats like point clouds, meshes, or implicit functions each have their strengths and weaknesses. Still, grid representations such as signed distance functions have attractive properties also in 3D. In particular, they offer constant-time random access and are eminently suitable for modern machine learning. Unfortunately, the storage size of a grid grows exponentially with its dimension. Hence they often exceed memory limits even at moderate resolution. This work explores various low-rank tensor formats, including the Tucker, tensor train, and quantics tensor train decompositions, to compress time-varying 3D data. Our method iteratively computes, voxelizes, and compresses each frame's truncated signed distance function and applies tensor rank truncation to condense all frames into a single, compressed tensor that represents the entire 4D scene. We show that low-rank tensor compression is extremely compact to store and query time-varying signed distance functions. It significantly reduces the memory footprint of 4D scenes while surprisingly preserving their geometric quality. Unlike existing iterative learning-based approaches like DeepSDF and NeRF, our method uses a closed-form algorithm with theoretical guarantees.
tntorch: Tensor Network Learning with PyTorch
Jun 22, 2022

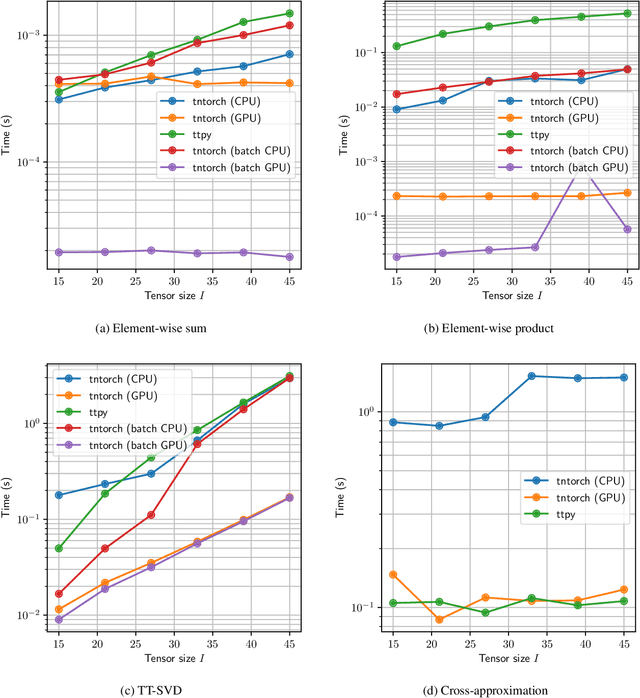
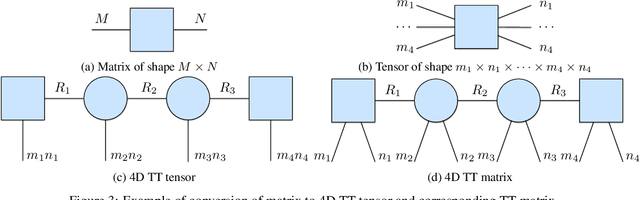
We present tntorch, a tensor learning framework that supports multiple decompositions (including Candecomp/Parafac, Tucker, and Tensor Train) under a unified interface. With our library, the user can learn and handle low-rank tensors with automatic differentiation, seamless GPU support, and the convenience of PyTorch's API. Besides decomposition algorithms, tntorch implements differentiable tensor algebra, rank truncation, cross-approximation, batch processing, comprehensive tensor arithmetics, and more.
Cherry-Picking Gradients: Learning Low-Rank Embeddings of Visual Data via Differentiable Cross-Approximation
May 29, 2021


We propose an end-to-end trainable framework that processes large-scale visual data tensors by looking \emph{at a fraction of their entries only}. Our method combines a neural network encoder with a \emph{tensor train decomposition} to learn a low-rank latent encoding, coupled with cross-approximation (CA) to learn the representation through a subset of the original samples. CA is an adaptive sampling algorithm that is native to tensor decompositions and avoids working with the full high-resolution data explicitly. Instead, it actively selects local representative samples that we fetch out-of-core and on-demand. The required number of samples grows only logarithmically with the size of the input. Our implicit representation of the tensor in the network enables processing large grids that could not be otherwise tractable in their uncompressed form. The proposed approach is particularly useful for large-scale multidimensional grid data (e.g., 3D tomography), and for tasks that require context over a large receptive field (e.g., predicting the medical condition of entire organs). The code will be available at https://github.com/aelphy/c-pic
PREDATOR: Registration of 3D Point Clouds with Low Overlap
Nov 25, 2020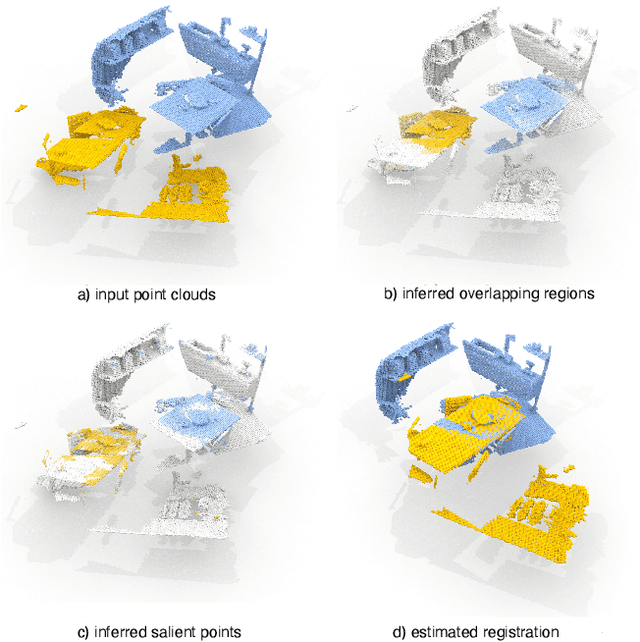
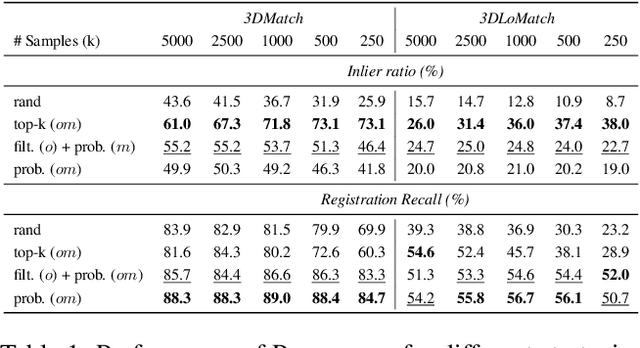
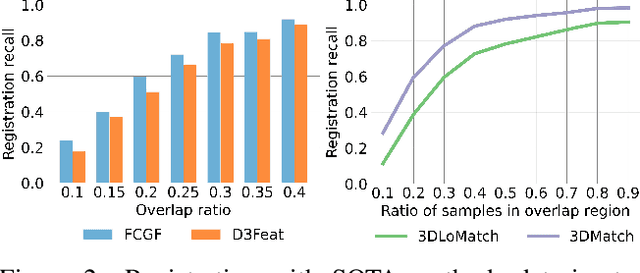
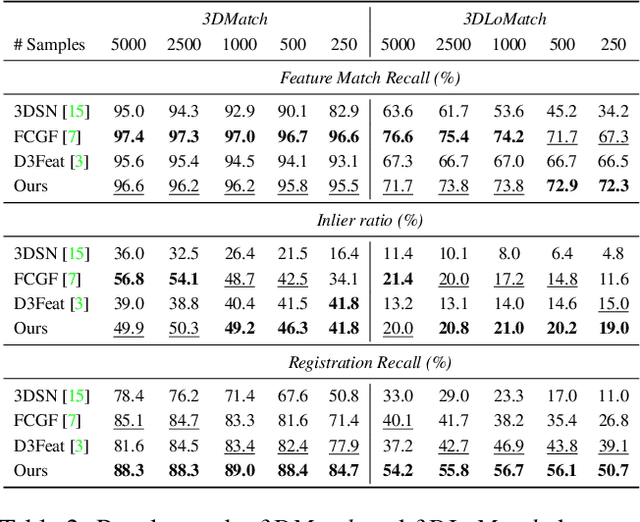
We introduce PREDATOR, a model for pairwise point-cloud registration with deep attention to the overlap region. Different from previous work, our model is specifically designed to handle (also) point-cloud pairs with low overlap. Its key novelty is an overlap-attention block for early information exchange between the latent encodings of the two point clouds. In this way the subsequent decoding of the latent representations into per-point features is conditioned on the respective other point cloud, and thus can predict which points are not only salient, but also lie in the overlap region between the two point clouds. The ability to focus on points that are relevant for matching greatly improves performance: PREDATOR raises the rate of successful registrations by more than 20% in the low-overlap scenario, and also sets a new state of the art for the 3DMatch benchmark with 89% registration recall. Source code and pre-trained models will be available at https://github.com/ShengyuH/OverlapPredator.
Indoor Scene Recognition in 3D
Feb 28, 2020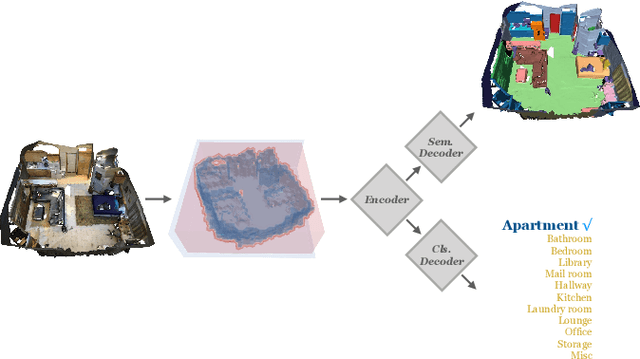
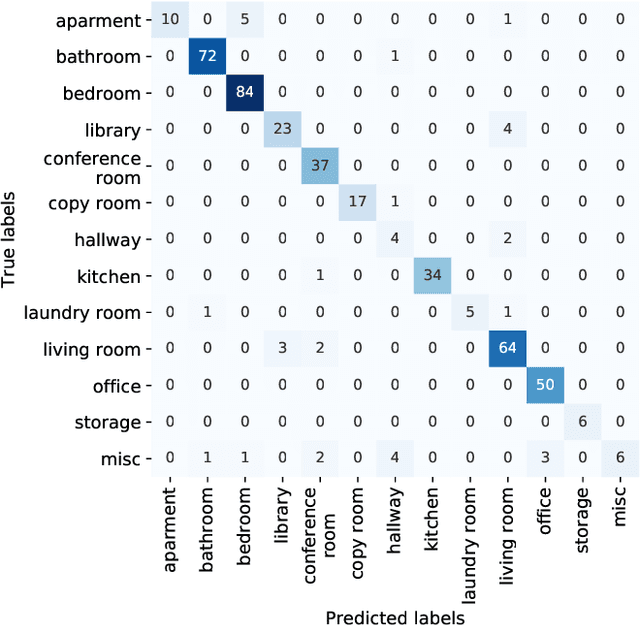
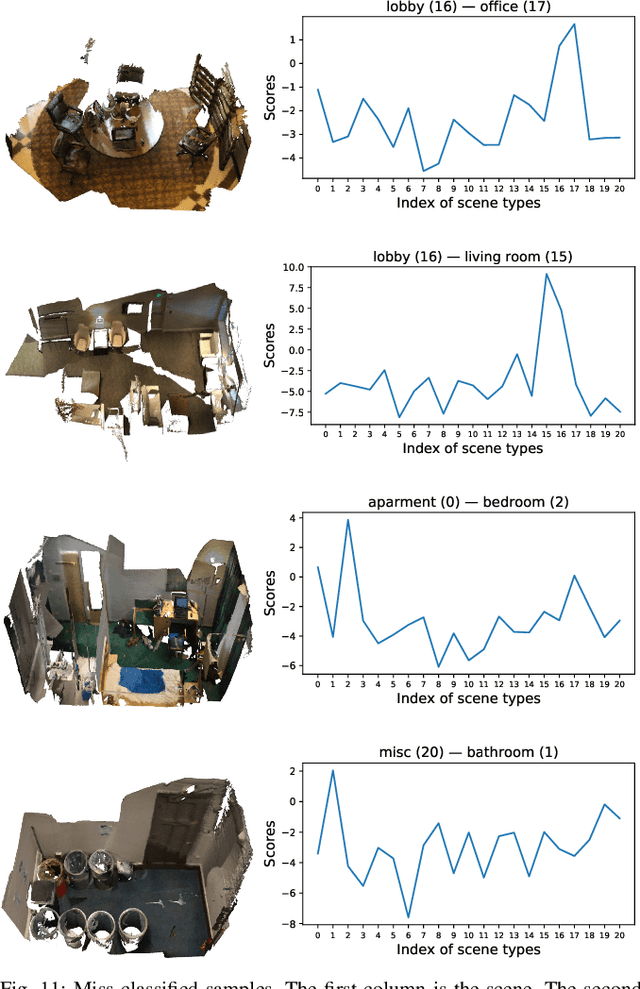
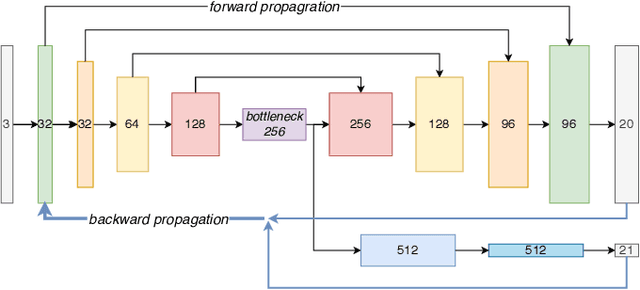
Recognising in what type of environment one is located is an important perception task. For instance, for a robot operating in indoors it is helpful to be aware whether it is in a kitchen, a hallway or a bedroom. Existing approaches attempt to classify the scene based on 2D images or 2.5D range images. Here, we study scene recognition from 3D point cloud (or voxel) data, and show that it greatly outperforms methods based on 2D birds-eye views. Moreover, we advocate multi-task learning as a way of improving scene recognition, building on the fact that the scene type is highly correlated with the objects in the scene, and therefore with its semantic segmentation into different object classes. In a series of ablation studies, we show that successful scene recognition is not just the recognition of individual objects unique to some scene type (such as a bathtub), but depends on several different cues, including coarse 3D geometry, colour, and the (implicit) distribution of object categories. Moreover, we demonstrate that surprisingly sparse 3D data is sufficient to classify indoor scenes with good accuracy.
Visual recognition in the wild by sampling deep similarity functions
Mar 15, 2019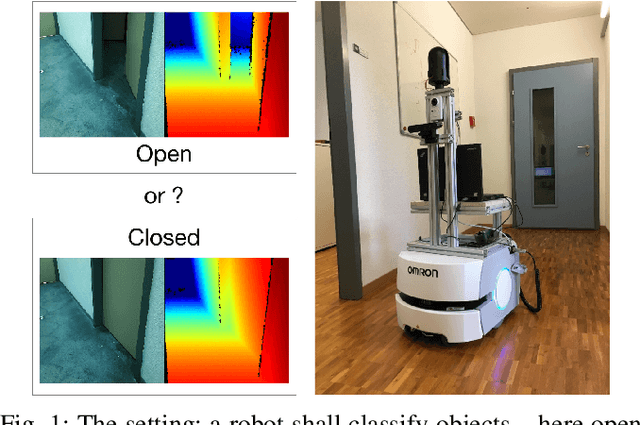
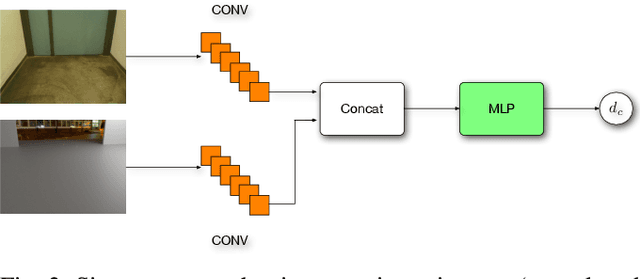


Recognising relevant objects or object states in its environment is a basic capability for an autonomous robot. The dominant approach to object recognition in images and range images is classification by supervised machine learning, nowadays mostly with deep convolutional neural networks (CNNs). This works well for target classes whose variability can be completely covered with training examples. However, a robot moving in the wild, i.e., in an environment that is not known at the time the recognition system is trained, will often face \emph{domain shift}: the training data cannot be assumed to exhaustively cover all the within-class variability that will be encountered in the test data. In that situation, learning is in principle possible, since the training set does capture the defining properties, respectively dissimilarities, of the target classes. But directly training a CNN to predict class probabilities is prone to overfitting to irrelevant correlations between the class labels and the specific subset of the target class that is represented in the training set. We explore the idea to instead learn a Siamese CNN that acts as similarity function between pairs of training examples. Class predictions are then obtained by measuring the similarities between a new test instance and the training samples. We show that the CNN embedding correctly recovers the relative similarities to arbitrary class exemplars in the training set. And that therefore few, randomly picked training exemplars are sufficient to achieve good predictions, making the procedure efficient.
Inference, Learning and Attention Mechanisms that Exploit and Preserve Sparsity in Convolutional Networks
Feb 09, 2018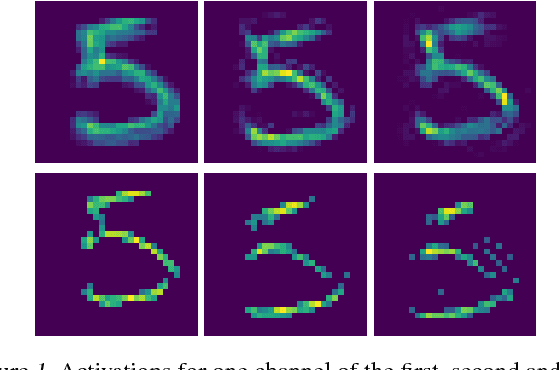

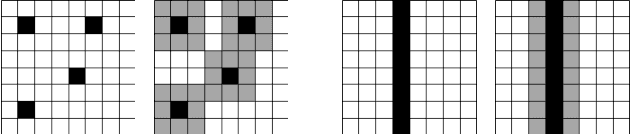
While CNNs naturally lend themselves to densely sampled data, and sophisticated implementations are available, they lack the ability to efficiently process sparse data. In this work we introduce a suite of tools that exploit sparsity in both the feature maps and the filter weights, and thereby allow for significantly lower memory footprints and computation times than the conventional dense framework when processing data with a high degree of sparsity. Our scheme provides (i) an efficient GPU implementation of a convolution layer based on direct, sparse convolution; (ii) a filter step within the convolution layer, which we call attention, that prevents fill-in, i.e., the tendency of convolution to rapidly decrease sparsity, and guarantees an upper bound on the computational resources; and (iii) an adaptation of the back-propagation algorithm, which makes it possible to combine our approach with standard learning frameworks, while still exploiting sparsity in the data and the model.