 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference, Learning and Attention Mechanisms that Exploit and Preserve Sparsity in Convolutional Networks
Feb 09, 2018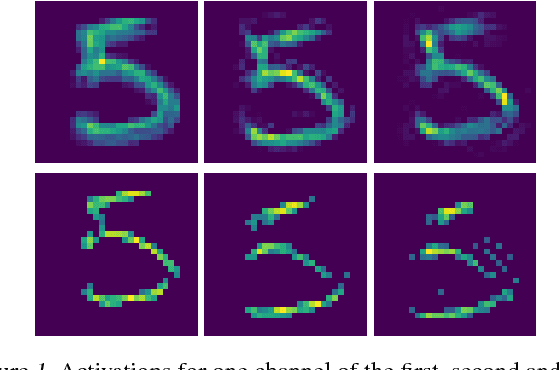

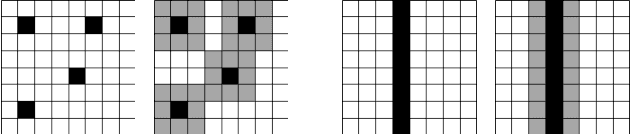
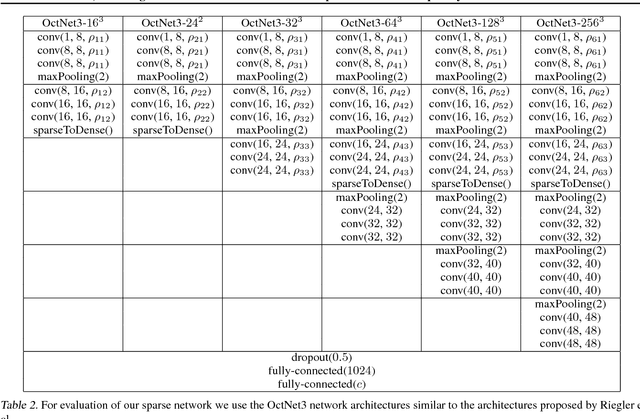
While CNNs naturally lend themselves to densely sampled data, and sophisticated implementations are available, they lack the ability to efficiently process sparse data. In this work we introduce a suite of tools that exploit sparsity in both the feature maps and the filter weights, and thereby allow for significantly lower memory footprints and computation times than the conventional dense framework when processing data with a high degree of sparsity. Our scheme provides (i) an efficient GPU implementation of a convolution layer based on direct, sparse convolution; (ii) a filter step within the convolution layer, which we call attention, that prevents fill-in, i.e., the tendency of convolution to rapidly decrease sparsity, and guarantees an upper bound on the computational resources; and (iii) an adaptation of the back-propagation algorithm, which makes it possible to combine our approach with standard learning frameworks, while still exploiting sparsity in the data and the model.
Semantic3D.net: A new Large-scale Point Cloud Classification Benchmark
Apr 12, 2017

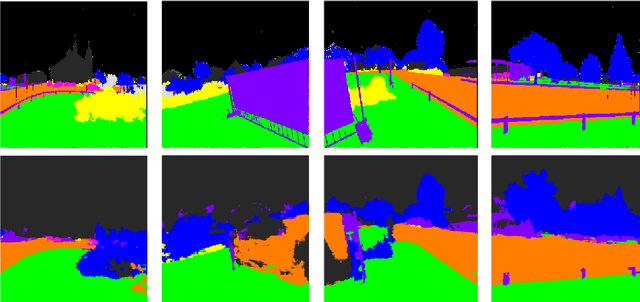

This paper presents a new 3D point cloud classification benchmark data set with over four billion manually labelled points, meant as input for data-hungry (deep) learning methods. We also discuss first submissions to the benchmark that use deep convolutional neural networks (CNNs) as a work horse, which already show remarkable performance improvements over state-of-the-art. CNNs have become the de-facto standard for many tasks in computer vision and machine learning like semantic segmentation or object detection in images, but have no yet led to a true breakthrough for 3D point cloud labelling tasks due to lack of training data. With the massive data set presented in this paper, we aim at closing this data gap to help unleash the full potential of deep learning methods for 3D labelling tasks. Our semantic3D.net data set consists of dense point clouds acquired with static terrestrial laser scanners. It contains 8 semantic classes and covers a wide range of urban outdoor scenes: churches, streets, railroad tracks, squares, villages, soccer fields and castles. We describe our labelling interface and show that our data set provides more dense and complete point clouds with much higher overall number of labelled points compared to those already available to the research community. We further provide baseline method descriptions and comparison between methods submitted to our online system. We hope semantic3D.net will pave the way for deep learning methods in 3D point cloud labelling to learn richer, more general 3D representations, and first submissions after only a few months indicate that this might indeed be the case.