 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERMES: A Holistic End-to-End Risk-Aware Multimodal Embodied System with Vision-Language Models for Long-Tail Autonomous Driving
Feb 01, 2026End-to-end autonomous driving models increasingly benefit from large vision--language models for semantic understanding, yet ensuring safe and accurate operation under long-tail conditions remains challenging. These challenges are particularly prominent in long-tail mixed-traffic scenarios, where autonomous vehicles must interact with heterogeneous road users, including human-driven vehicles and vulnerable road users, under complex and uncertain conditions. This paper proposes HERMES, a holistic risk-aware end-to-end multimodal driving framework designed to inject explicit long-tail risk cues into trajectory planning. HERMES employs a foundation-model-assisted annotation pipeline to produce structured Long-Tail Scene Context and Long-Tail Planning Context, capturing hazard-centric cues together with maneuver intent and safety preference, and uses these signals to guide end-to-end planning. HERMES further introduces a Tri-Modal Driving Module that fuses multi-view perception, historical motion cues, and semantic guidance, ensuring risk-aware accurate trajectory planning under long-tail scenarios. Experiments on the real-world long-tail dataset demonstrate that HERMES consistently outperforms representative end-to-end and VLM-driven baselines under long-tail mixed-traffic scenarios. Ablation studies verify the complementary contributions of key components.
Cross-modal feature fusion for robust point cloud registration with ambiguous geometry
May 19, 2025



Point cloud registration has seen significant advancements with the application of deep learning techniques. However, existing approaches often overlook the potential of integrating radiometric information from RGB images. This limitation reduces their effectiveness in aligning point clouds pairs, especially in regions where geometric data alone is insufficient. When used effectively, radiometric information can enhance the registration process by providing context that is missing from purely geometric data. In this paper, we propose CoFF, a novel Cross-modal Feature Fusion method that utilizes both point cloud geometry and RGB images for pairwise point cloud registration. Assuming that the co-registration between point clouds and RGB images is available, CoFF explicitly addresses the challenges where geometric information alone is unclear, such as in regions with symmetric similarity or planar structures, through a two-stage fusion of 3D point cloud features and 2D image features. It incorporates a cross-modal feature fusion module that assigns pixel-wise image features to 3D input point clouds to enhance learned 3D point features, and integrates patch-wise image features with superpoint features to improve the quality of coarse matching. This is followed by a coarse-to-fine matching module that accurately establishes correspondences using the fused features. We extensively evaluate CoFF on four common datasets: 3DMatch, 3DLoMatch, IndoorLRS, and the recently released ScanNet++ datasets. In addition, we assess CoFF on specific subset datasets containing geometrically ambiguous cases. Our experimental results demonstrate that CoFF achieves state-of-the-art registration performance across all benchmarks, including remarkable registration recalls of 95.9% and 81.6% on the widely-used 3DMatch and 3DLoMatch datasets, respectively...(Truncated to fit arXiv abstract length)
Co-MTP: A Cooperative Trajectory Prediction Framework with Multi-Temporal Fusion for Autonomous Driving
Feb 25, 2025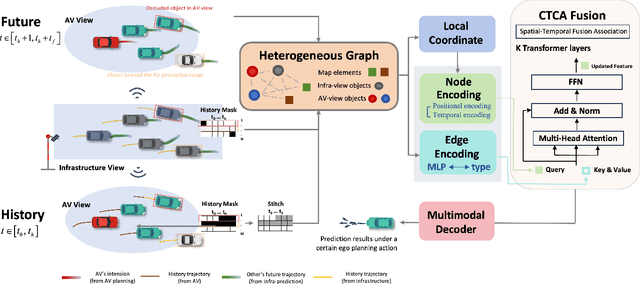
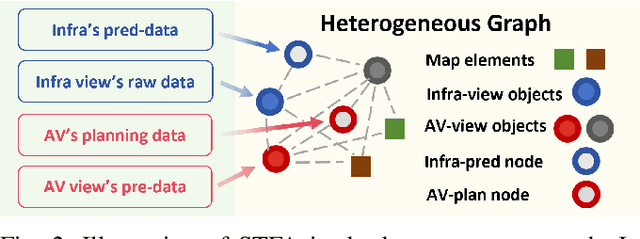
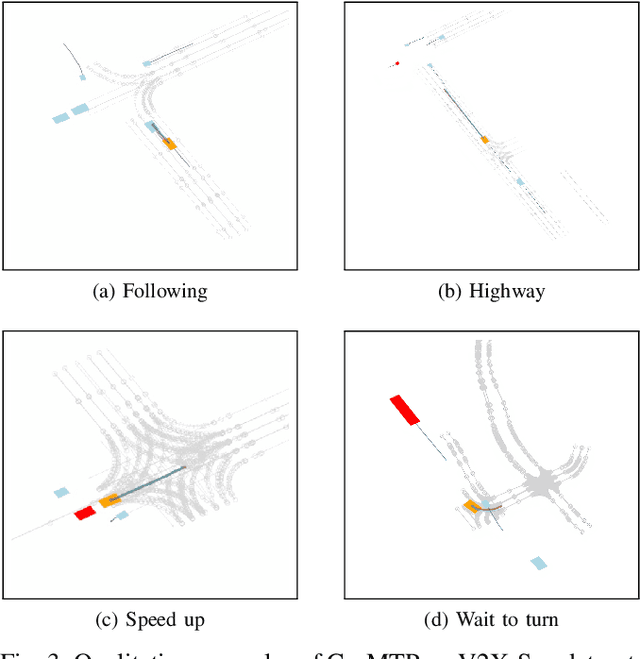

Vehicle-to-everything technologies (V2X) have become an ideal paradigm to extend the perception range and see through the occlusion. Exiting efforts focus on single-frame cooperative perception, however, how to capture the temporal cue between frames with V2X to facilitate the prediction task even the planning task is still underexplored. In this paper, we introduce the Co-MTP, a general cooperative trajectory prediction framework with multi-temporal fusion for autonomous driving, which leverages the V2X system to fully capture the interaction among agents in both history and future domains to benefit the planning. In the history domain, V2X can complement the incomplete history trajectory in single-vehicle perception, and we design a heterogeneous graph transformer to learn the fusion of the history feature from multiple agents and capture the history interaction. Moreover, the goal of prediction is to support future planning. Thus, in the future domain, V2X can provide the prediction results of surrounding objects, and we further extend the graph transformer to capture the future interaction among the ego planning and the other vehicles' intentions and obtain the final future scenario state under a certain planning action. We evaluate the Co-MTP framework on the real-world dataset V2X-Seq, and the results show that Co-MTP achieves state-of-the-art performance and that both history and future fusion can greatly benefit prediction.
SLHCat: Mapping Wikipedia Categories and Lists to DBpedia by Leveraging Semantic, Lexical, and Hierarchical Features
Sep 27, 2023Wikipedia articles are hierarchically organized through categories and lists, providing one of the most comprehensive and universal taxonomy, but its open creation is causing redundancies and inconsistencies. Assigning DBPedia classes to Wikipedia categories and lists can alleviate the problem, realizing a large knowledge graph which is essential for categorizing digital contents through entity linking and typing. However, the existing approach of CaLiGraph is producing incomplete and non-fine grained mappings. In this paper, we tackle the problem as ontology alignment, where structural information of knowledge graphs and lexical and semantic features of ontology class names are utilized to discover confident mappings, which are in turn utilized for finetuing pretrained language models in a distant supervision fashion. Our method SLHCat consists of two main parts: 1) Automatically generating training data by leveraging knowledge graph structure, semantic similarities, and named entity typing. 2) Finetuning and prompt-tuning of the pre-trained language model BERT are carried out over the training data, to capture semantic and syntactic properties of class names. Our model SLHCat is evaluated over a benchmark dataset constructed by annotating 3000 fine-grained CaLiGraph-DBpedia mapping pairs. SLHCat is outperforming the baseline model by a large margin of 25% in accuracy, offering a practical solution for large-scale ontology mapping.