 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossEarth-SAR: A SAR-Centric and Billion-Scale Geospatial Foundation Model for Domain Generalizable Semantic Segmentation
Mar 12, 2026Synthetic Aperture Radar (SAR) enables global, all-weather earth observation. However, owing to diverse imaging mechanisms, domain shifts across sensors and regions severely hinder its semantic generalization. To address this, we present CrossEarth-SAR, the first billion-scale SAR vision foundation model built upon a novel physics-guided sparse mixture-of-experts (MoE) architecture incorporating physical descriptors, explicitly designed for cross-domain semantic segmentation. To facilitate large-scale pre-training, we develop CrossEarth-SAR-200K, a weakly and fully supervised dataset that unifies public and private SAR imagery. We also introduce a benchmark suite comprising 22 sub-benchmarks across 8 distinct domain gaps, establishing the first unified standard for domain generalization semantic segmentation on SAR imagery. Extensive experiments demonstrate that CrossEarth-SAR achieves state-of-the-art results on 20 benchmarks, surpassing previous methods by over 10\% mIoU on some benchmarks under multi-gap transfer. All code, benchmark and datasets will be publicly available.
COP-GEN-Beta: Unified Generative Modelling of COPernicus Imagery Thumbnails
Apr 14, 2025In remote sensing, multi-modal data from various sensors capturing the same scene offers rich opportunities, but learning a unified representation across these modalities remains a significant challenge. Traditional methods have often been limited to single or dual-modality approaches. In this paper, we introduce COP-GEN-Beta, a generative diffusion model trained on optical, radar, and elevation data from the Major TOM dataset. What sets COP-GEN-Beta apart is its ability to map any subset of modalities to any other, enabling zero-shot modality translation after training. This is achieved through a sequence-based diffusion transformer, where each modality is controlled by its own timestep embedding. We extensively evaluate COP-GEN-Beta on thumbnail images from the Major TOM dataset, demonstrating its effectiveness in generating high-quality samples. Qualitative and quantitative evaluations validate the model's performance, highlighting its potential as a powerful pre-trained model for future remote sensing tasks.
Earth-Adapter: Bridge the Geospatial Domain Gaps with Mixture of Frequency Adaptation
Apr 09, 2025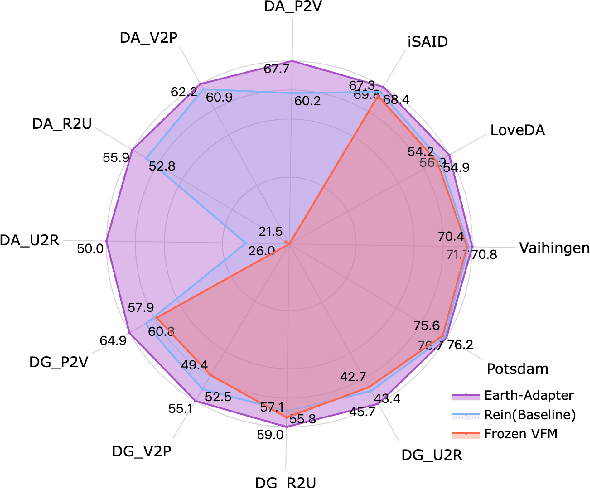
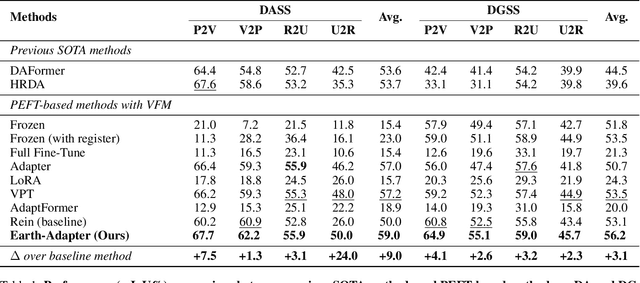
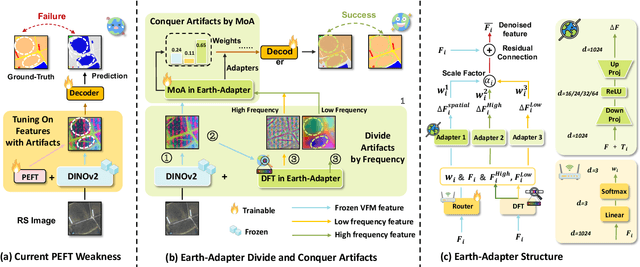
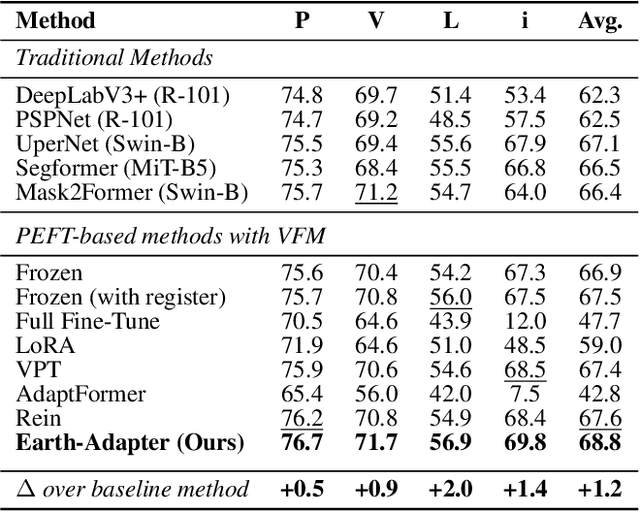
Parameter-Efficient Fine-Tuning (PEFT) is a technique that allows us to adapt powerful Foundation Models (FMs) to diverse downstream tasks while preserving and unleashing their inherent capabilities. However, we have observed that existing PEFT methods, which are often designed with natural imagery in mind, struggle when applied to Remote Sensing (RS) scenarios. This is primarily due to their inability to handle artifact influences, a problem particularly severe in RS image features. To tackle this challenge, we introduce Earth-Adapter, the first PEFT method specifically designed for RS artifacts conquering. Earth-Adapter introduces a novel Mixture of Frequency Adaptation process that combines a Mixture of Adapter (MoA) with Discrete Fourier Transformation (DFT). By utilizing DFT, Earth-Adapter can decompose features into different frequency components, precisely separating artifacts from original features. The MoA then dynamically assigns weights to each adapter expert, allowing for the combination of features across various frequency domains. These simple-yet-effective approaches enable Earth-Adapter to more efficiently overcome the disturbances caused by artifacts than previous PEFT methods, significantly enhancing the FMs' performance on RS scenarios. Experiments on Domain Adaptation (DA), and Domain Generalization (DG) semantic segmentation benchmarks showcase the Earth-Adapter's effectiveness. Compared with baseline Rein, Earth-Adapter significantly improves 9.0% mIoU in DA and 3.1% mIoU in DG benchmarks. Our code will be released at https://github.com/VisionXLab/Earth-Adapter.
Can Generative Geospatial Diffusion Models Excel as Discriminative Geospatial Foundation Models?
Mar 10, 2025Self-supervised learning (SSL) has revolutionized representation learning in Remote Sensing (RS), advancing Geospatial Foundation Models (GFMs) to leverage vast unlabeled satellite imagery for diverse downstream tasks. Currently, GFMs primarily focus on discriminative objectives, such as contrastive learning or masked image modeling, owing to their proven success in learning transferable representations. However, generative diffusion models--which demonstrate the potential to capture multi-grained semantics essential for RS tasks during image generation--remain underexplored for discriminative applications. This prompts the question: can generative diffusion models also excel and serve as GFMs with sufficient discriminative power? In this work, we answer this question with SatDiFuser, a framework that transforms a diffusion-based generative geospatial foundation model into a powerful pretraining tool for discriminative RS. By systematically analyzing multi-stage, noise-dependent diffusion features, we develop three fusion strategies to effectively leverage these diverse representations. Extensive experiments on remote sensing benchmarks show that SatDiFuser outperforms state-of-the-art GFMs, achieving gains of up to +5.7% mIoU in semantic segmentation and +7.9% F1-score in classification, demonstrating the capacity of diffusion-based generative foundation models to rival or exceed discriminative GFMs. Code will be released.
PANGAEA: A Global and Inclusive Benchmark for Geospatial Foundation Models
Dec 05, 2024Geospatial Foundation Models (GFMs) have emerged as powerful tools for extracting representations from Earth observation data, but their evaluation remains inconsistent and narrow. Existing works often evaluate on suboptimal downstream datasets and tasks, that are often too easy or too narrow, limiting the usefulness of the evaluations to assess the real-world applicability of GFMs. Additionally, there is a distinct lack of diversity in current evaluation protocols, which fail to account for the multiplicity of image resolutions, sensor types, and temporalities, which further complicates the assessment of GFM performance. In particular, most existing benchmarks are geographically biased towards North America and Europe, questioning the global applicability of GFMs. To overcome these challenges, we introduce PANGAEA, a standardized evaluation protocol that covers a diverse set of datasets, tasks, resolutions, sensor modalities, and temporalities. It establishes a robust and widely applicable benchmark for GFMs. We evaluate the most popular GFMs openly available on this benchmark and analyze their performance across several domains. In particular, we compare these models to supervised baselines (e.g. UNet and vanilla ViT), and assess their effectiveness when faced with limited labeled data. Our findings highlight the limitations of GFMs, under different scenarios, showing that they do not consistently outperform supervised models. PANGAEA is designed to be highly extensible, allowing for the seamless inclusion of new datasets, models, and tasks in future research. By releasing the evaluation code and benchmark, we aim to enable other researchers to replicate our experiments and build upon our work, fostering a more principled evaluation protocol for large pre-trained geospatial models. The code is available at https://github.com/VMarsocci/pangaea-bench.
CrossEarth: Geospatial Vision Foundation Model for Domain Generalizable Remote Sensing Semantic Segmentation
Oct 31, 2024


The field of Remote Sensing Domain Generalization (RSDG) has emerged as a critical and valuable research frontier, focusing on developing models that generalize effectively across diverse scenarios. Despite the substantial domain gaps in RS images that are characterized by variabilities such as location, wavelength, and sensor type, research in this area remains underexplored: (1) Current cross-domain methods primarily focus on Domain Adaptation (DA), which adapts models to predefined domains rather than to unseen ones; (2) Few studies targeting the RSDG issue, especially for semantic segmentation tasks, where existing models are developed for specific unknown domains, struggling with issues of underfitting on other unknown scenarios; (3) Existing RS foundation models tend to prioritize in-domain performance over cross-domain generalization. To this end, we introduce the first vision foundation model for RSDG semantic segmentation, CrossEarth. CrossEarth demonstrates strong cross-domain generalization through a specially designed data-level Earth-Style Injection pipeline and a model-level Multi-Task Training pipeline. In addition, for the semantic segmentation task, we have curated an RSDG benchmark comprising 28 cross-domain settings across various regions, spectral bands, platforms, and climates, providing a comprehensive framework for testing the generalizability of future RSDG models. Extensive experiments on this benchmark demonstrate the superiority of CrossEarth over existing state-of-the-art methods.
DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
Dec 05, 2023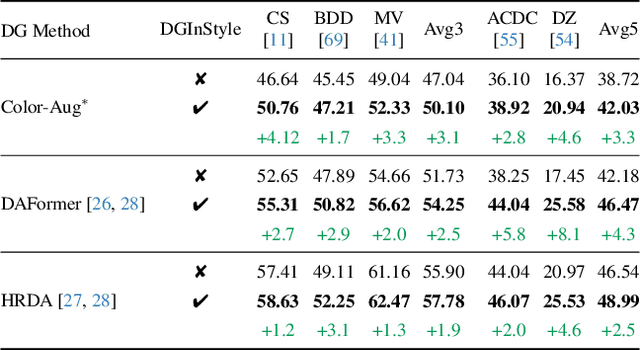
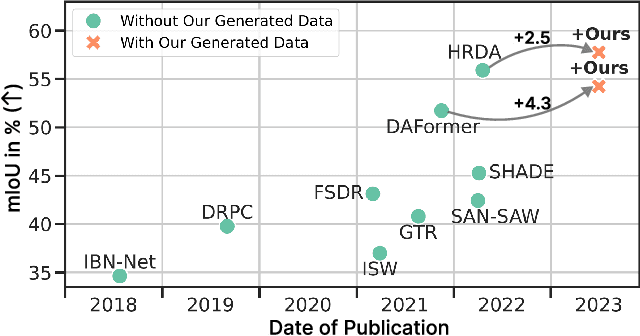
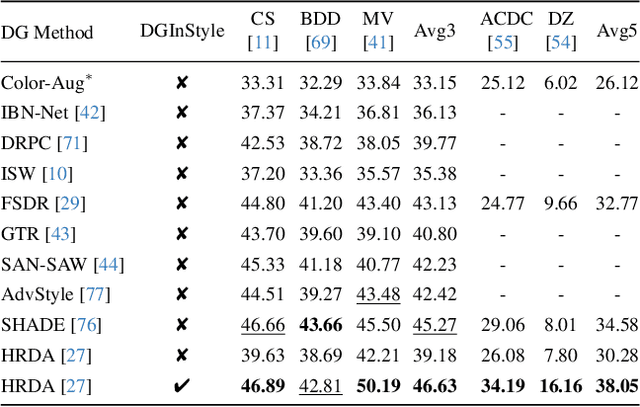
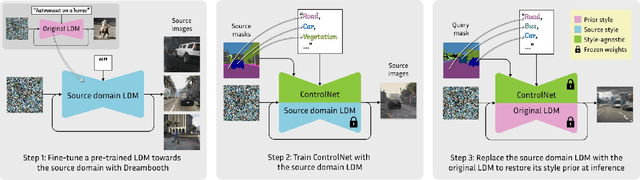
Large, pretrained latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate creative content, specialize to user data through few-shot fine-tuning, and condition their output on other modalities, such as semantic maps. However, are they usable as large-scale data generators, e.g., to improve tasks in the perception stack, like semantic segmentation? We investigate this question in the context of autonomous driving, and answer it with a resounding "yes". We propose an efficient data generation pipeline termed DGInStyle. First, we examine the problem of specializing a pretrained LDM to semantically-controlled generation within a narrow domain. Second, we design a Multi-resolution Latent Fusion technique to overcome the bias of LDMs towards dominant objects. Third, we propose a Style Swap technique to endow the rich generative prior with the learned semantic control. Using DGInStyle, we generate a diverse dataset of street scenes, train a domain-agnostic semantic segmentation model on it, and evaluate the model on multiple popular autonomous driving datasets. Our approach consistently increases the performance of several domain generalization methods, in some cases by +2.5 mIoU compared to the previous state-of-the-art method without our generative augmentation scheme. Source code and dataset are available at https://dginstyle.github.io .
DEFLOW: Self-supervised 3D Motion Estimation of Debris Flow
Apr 05, 2023Existing work on scene flow estimation focuses on autonomous driving and mobile robotics, while automated solutions are lacking for motion in nature, such as that exhibited by debris flows. We propose DEFLOW, a model for 3D motion estimation of debris flows, together with a newly captured dataset. We adopt a novel multi-level sensor fusion architecture and self-supervision to incorporate the inductive biases of the scene. We further adopt a multi-frame temporal processing module to enable flow speed estimation over time. Our model achieves state-of-the-art optical flow and depth estimation on our dataset, and fully automates the motion estimation for debris flows. The source code and dataset are available at project page.