 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarthEmbeddingExplorer: A Web Application for Cross-Modal Retrieval of Global Satellite Images
Mar 31, 2026While the Earth observation community has witnessed a surge in high-impact foundation models and global Earth embedding datasets, a significant barrier remains in translating these academic assets into freely accessible tools. This tutorial introduces EarthEmbeddingExplorer, an interactive web application designed to bridge this gap, transforming static research artifacts into dynamic, practical workflows for discovery. We will provide a comprehensive hands-on guide to the system, detailing its cloud-native software architecture, demonstrating cross-modal queries (natural language, visual, and geolocation), and showcasing how to derive scientific insights from retrieval results. By democratizing access to precomputed Earth embeddings, this tutorial empowers researchers to seamlessly transition from state-of-the-art models and data archives to real-world application and analysis. The web application is available at https://modelscope.ai/studios/Major-TOM/EarthEmbeddingExplorer.
COP-GEN: Latent Diffusion Transformer for Copernicus Earth Observation Data -- Generation Stochastic by Design
Mar 03, 2026Earth observation applications increasingly rely on data from multiple sensors, including optical, radar, elevation, and land-cover products. Relationships between these modalities are fundamental for data integration but are inherently non-injective: identical conditioning information can correspond to multiple physically plausible observations. Thus, such conditional mappings should be parametrised as data distributions. As a result, deterministic models tend to collapse toward conditional means and fail to represent the uncertainty and variability required for tasks such as data completion and cross-sensor translation. We introduce COP-GEN, a multimodal latent diffusion transformer that models the joint distribution of heterogeneous Earth Observation modalities at their native spatial resolutions. By parameterising cross-modal mappings as conditional distributions, COP-GEN enables flexible any-to-any conditional generation, including zero-shot modality translation, spectral band infilling, and generation under partial or missing inputs, without task-specific retraining. Experiments on a large-scale global multimodal dataset show that COP-GEN generates diverse yet physically consistent realisations while maintaining strong peak fidelity across optical, radar, and elevation modalities. Qualitative and quantitative analyses demonstrate that the model captures meaningful cross-modal structure and systematically adapts its output uncertainty as conditioning information increases. These results highlight the practical importance of stochastic generative modeling for Earth observation and motivate evaluation protocols that move beyond single-reference, pointwise metrics. Website: https:// miquel-espinosa.github.io/cop-gen
HeatMat: Simulation of City Material Impact on Urban Heat Island Effect
Jan 30, 2026The Urban Heat Island (UHI) effect, defined as a significant increase in temperature in urban environments compared to surrounding areas, is difficult to study in real cities using sensor data (satellites or in-situ stations) due to their coarse spatial and temporal resolution. Among the factors contributing to this effect are the properties of urban materials, which differ from those in rural areas. To analyze their individual impact and to test new material configurations, a high-resolution simulation at the city scale is required. Estimating the current materials used in a city, including those on building facades, is also challenging. We propose HeatMat, an approach to analyze at high resolution the individual impact of urban materials on the UHI effect in a real city, relying only on open data. We estimate building materials using street-view images and a pre-trained vision-language model (VLM) to supplement existing OpenStreetMap data, which describes the 2D geometry and features of buildings. We further encode this information into a set of 2D maps that represent the city's vertical structure and material characteristics. These maps serve as inputs for our 2.5D simulator, which models coupled heat transfers and enables random-access surface temperature estimation at multiple resolutions, reaching an x20 speedup compared to an equivalent simulation in 3D.
TerraMesh: A Planetary Mosaic of Multimodal Earth Observation Data
Apr 15, 2025Large-scale foundation models in Earth Observation can learn versatile, label-efficient representations by leveraging massive amounts of unlabeled data. However, existing public datasets are often limited in scale, geographic coverage, or sensor variety. We introduce TerraMesh, a new globally diverse, multimodal dataset combining optical, synthetic aperture radar, elevation, and land-cover modalities in an Analysis-Ready Data format. TerraMesh includes over 9 million samples with eight spatiotemporal aligned modalities, enabling large-scale pre-training and fostering robust cross-modal correlation learning. We provide detailed data processing steps, comprehensive statistics, and empirical evidence demonstrating improved model performance when pre-trained on TerraMesh. The dataset will be made publicly available with a permissive license.
COP-GEN-Beta: Unified Generative Modelling of COPernicus Imagery Thumbnails
Apr 14, 2025In remote sensing, multi-modal data from various sensors capturing the same scene offers rich opportunities, but learning a unified representation across these modalities remains a significant challenge. Traditional methods have often been limited to single or dual-modality approaches. In this paper, we introduce COP-GEN-Beta, a generative diffusion model trained on optical, radar, and elevation data from the Major TOM dataset. What sets COP-GEN-Beta apart is its ability to map any subset of modalities to any other, enabling zero-shot modality translation after training. This is achieved through a sequence-based diffusion transformer, where each modality is controlled by its own timestep embedding. We extensively evaluate COP-GEN-Beta on thumbnail images from the Major TOM dataset, demonstrating its effectiveness in generating high-quality samples. Qualitative and quantitative evaluations validate the model's performance, highlighting its potential as a powerful pre-trained model for future remote sensing tasks.
MESA: Text-Driven Terrain Generation Using Latent Diffusion and Global Copernicus Data
Apr 09, 2025



Terrain modeling has traditionally relied on procedural techniques, which often require extensive domain expertise and handcrafted rules. In this paper, we present MESA - a novel data-centric alternative by training a diffusion model on global remote sensing data. This approach leverages large-scale geospatial information to generate high-quality terrain samples from text descriptions, showcasing a flexible and scalable solution for terrain generation. The model's capabilities are demonstrated through extensive experiments, highlighting its ability to generate realistic and diverse terrain landscapes. The dataset produced to support this work, the Major TOM Core-DEM extension dataset, is released openly as a comprehensive resource for global terrain data. The results suggest that data-driven models, trained on remote sensing data, can provide a powerful tool for realistic terrain modeling and generation.
Global and Dense Embeddings of Earth: Major TOM Floating in the Latent Space
Dec 07, 2024



With the ever-increasing volumes of the Earth observation data present in the archives of large programmes such as Copernicus, there is a growing need for efficient vector representations of the underlying raw data. The approach of extracting feature representations from pretrained deep neural networks is a powerful approach that can provide semantic abstractions of the input data. However, the way this is done for imagery archives containing geospatial data has not yet been defined. In this work, an extension is proposed to an existing community project, Major TOM, focused on the provision and standardization of open and free AI-ready datasets for Earth observation. Furthermore, four global and dense embedding datasets are released openly and for free along with the publication of this manuscript, resulting in the most comprehensive global open dataset of geospatial visual embeddings in terms of covered Earth's surface.
IceCloudNet: 3D reconstruction of cloud ice from Meteosat SEVIRI
Oct 05, 2024IceCloudNet is a novel method based on machine learning able to predict high-quality vertically resolved cloud ice water contents (IWC) and ice crystal number concentrations (N$_\textrm{ice}$). The predictions come at the spatio-temporal coverage and resolution of geostationary satellite observations (SEVIRI) and the vertical resolution of active satellite retrievals (DARDAR). IceCloudNet consists of a ConvNeXt-based U-Net and a 3D PatchGAN discriminator model and is trained by predicting DARDAR profiles from co-located SEVIRI images. Despite the sparse availability of DARDAR data due to its narrow overpass, IceCloudNet is able to predict cloud occurrence, spatial structure, and microphysical properties with high precision. The model has been applied to ten years of SEVIRI data, producing a dataset of vertically resolved IWC and N$_\textrm{ice}$ of clouds containing ice with a 3 kmx3 kmx240 mx15 minute resolution in a spatial domain of 30{\deg}W to 30{\deg}E and 30{\deg}S to 30{\deg}N. The produced dataset increases the availability of vertical cloud profiles, for the period when DARDAR is available, by more than six orders of magnitude and moreover, IceCloudNet is able to produce vertical cloud profiles beyond the lifetime of the recently ended satellite missions underlying DARDAR.
Non-invasive Diver Respiration Rate Monitoring in Hyperbaric Lifeboat Environments using Short-Range Radar
Apr 15, 2024

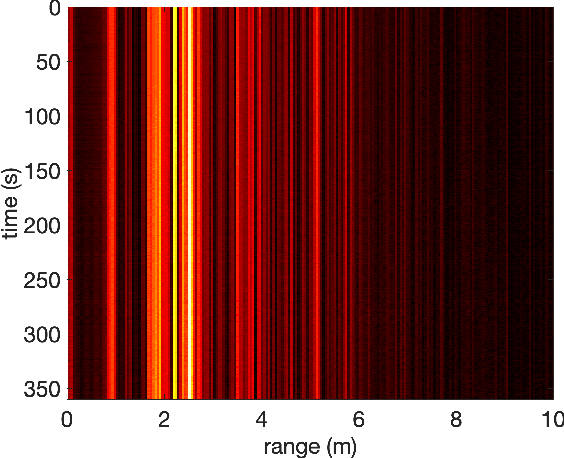

The monitoring of diver health during emergency events is crucial to ensuring the safety of personnel. A non-invasive system continuously providing a measure of the respiration rate of individual divers is exceedingly beneficial in this context. The paper reports on the application of short-range radar to record the respiration rate of divers within hyperbaric lifeboat environments. Results demonstrate that the respiratory motion can be extracted from the radar return signal applying routine signal processing. Further, evidence is provided that the radar-based approach yields a more accurate measure of respiration rate than an audio signal from a headset microphone. The system promotes an improvement in evacuation protocols under critical operational scenarios.
On Models and Approaches for Human Vital Signs Extraction from Short Range Radar Signals
Apr 15, 2024



The paper centres on an assessment of the modelling approaches for the processing of signals in CW and FMCW radar-based systems for the detection of vital signs. It is shown that the use of the widely adopted phase extraction method, which relies on the approximation of the target as a single point scatterer, has limitations in respect of the simultaneous estimation of both respiratory and heart rates. A method based on a velocity spectrum is proposed as an alternative with the ability to treat a wider range of application scenarios.