 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeatMat: Simulation of City Material Impact on Urban Heat Island Effect
Jan 30, 2026The Urban Heat Island (UHI) effect, defined as a significant increase in temperature in urban environments compared to surrounding areas, is difficult to study in real cities using sensor data (satellites or in-situ stations) due to their coarse spatial and temporal resolution. Among the factors contributing to this effect are the properties of urban materials, which differ from those in rural areas. To analyze their individual impact and to test new material configurations, a high-resolution simulation at the city scale is required. Estimating the current materials used in a city, including those on building facades, is also challenging. We propose HeatMat, an approach to analyze at high resolution the individual impact of urban materials on the UHI effect in a real city, relying only on open data. We estimate building materials using street-view images and a pre-trained vision-language model (VLM) to supplement existing OpenStreetMap data, which describes the 2D geometry and features of buildings. We further encode this information into a set of 2D maps that represent the city's vertical structure and material characteristics. These maps serve as inputs for our 2.5D simulator, which models coupled heat transfers and enables random-access surface temperature estimation at multiple resolutions, reaching an x20 speedup compared to an equivalent simulation in 3D.
MESA: Text-Driven Terrain Generation Using Latent Diffusion and Global Copernicus Data
Apr 09, 2025



Terrain modeling has traditionally relied on procedural techniques, which often require extensive domain expertise and handcrafted rules. In this paper, we present MESA - a novel data-centric alternative by training a diffusion model on global remote sensing data. This approach leverages large-scale geospatial information to generate high-quality terrain samples from text descriptions, showcasing a flexible and scalable solution for terrain generation. The model's capabilities are demonstrated through extensive experiments, highlighting its ability to generate realistic and diverse terrain landscapes. The dataset produced to support this work, the Major TOM Core-DEM extension dataset, is released openly as a comprehensive resource for global terrain data. The results suggest that data-driven models, trained on remote sensing data, can provide a powerful tool for realistic terrain modeling and generation.
MatAtlas: Text-driven Consistent Geometry Texturing and Material Assignment
Apr 03, 2024



We present MatAtlas, a method for consistent text-guided 3D model texturing. Following recent progress we leverage a large scale text-to-image generation model (e.g., Stable Diffusion) as a prior to texture a 3D model. We carefully design an RGB texturing pipeline that leverages a grid pattern diffusion, driven by depth and edges. By proposing a multi-step texture refinement process, we significantly improve the quality and 3D consistency of the texturing output. To further address the problem of baked-in lighting, we move beyond RGB colors and pursue assigning parametric materials to the assets. Given the high-quality initial RGB texture, we propose a novel material retrieval method capitalized on Large Language Models (LLM), enabling editabiliy and relightability. We evaluate our method on a wide variety of geometries and show that our method significantly outperform prior arts. We also analyze the role of each component through a detailed ablation study.
ControlMat: A Controlled Generative Approach to Material Capture
Sep 04, 2023
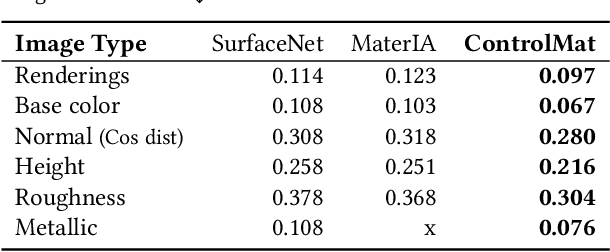
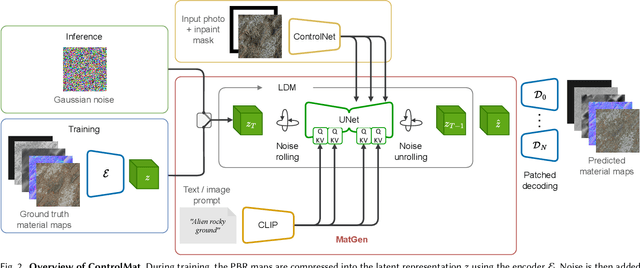

Material reconstruction from a photograph is a key component of 3D content creation democratization. We propose to formulate this ill-posed problem as a controlled synthesis one, leveraging the recent progress in generative deep networks. We present ControlMat, a method which, given a single photograph with uncontrolled illumination as input, conditions a diffusion model to generate plausible, tileable, high-resolution physically-based digital materials. We carefully analyze the behavior of diffusion models for multi-channel outputs, adapt the sampling process to fuse multi-scale information and introduce rolled diffusion to enable both tileability and patched diffusion for high-resolution outputs. Our generative approach further permits exploration of a variety of materials which could correspond to the input image, mitigating the unknown lighting conditions. We show that our approach outperforms recent inference and latent-space-optimization methods, and carefully validate our diffusion process design choices. Supplemental materials and additional details are available at: https://gvecchio.com/controlmat/.