 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeΦeat: Physically-Grounded Feature Representation
Nov 14, 2025Foundation models have emerged as effective backbones for many vision tasks. However, current self-supervised features entangle high-level semantics with low-level physical factors, such as geometry and illumination, hindering their use in tasks requiring explicit physical reasoning. In this paper, we introduce $Φ$eat, a novel physically-grounded visual backbone that encourages a representation sensitive to material identity, including reflectance cues and geometric mesostructure. Our key idea is to employ a pretraining strategy that contrasts spatial crops and physical augmentations of the same material under varying shapes and lighting conditions. While similar data have been used in high-end supervised tasks such as intrinsic decomposition or material estimation, we demonstrate that a pure self-supervised training strategy, without explicit labels, already provides a strong prior for tasks requiring robust features invariant to external physical factors. We evaluate the learned representations through feature similarity analysis and material selection, showing that $Φ$eat captures physically-grounded structure beyond semantic grouping. These findings highlight the promise of unsupervised physical feature learning as a foundation for physics-aware perception in vision and graphics. These findings highlight the promise of unsupervised physical feature learning as a foundation for physics-aware perception in vision and graphics.
MultiMat: Multimodal Program Synthesis for Procedural Materials using Large Multimodal Models
Sep 26, 2025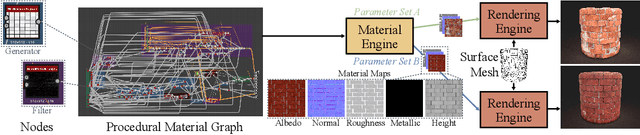

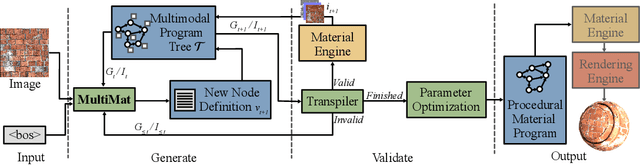

Material node graphs are programs that generate the 2D channels of procedural materials, including geometry such as roughness and displacement maps, and reflectance such as albedo and conductivity maps. They are essential in computer graphics for representing the appearance of virtual 3D objects parametrically and at arbitrary resolution. In particular, their directed acyclic graph structures and intermediate states provide an intuitive understanding and workflow for interactive appearance modeling. Creating such graphs is a challenging task and typically requires professional training. While recent neural program synthesis approaches attempt to simplify this process, they solely represent graphs as textual programs, failing to capture the inherently visual-spatial nature of node graphs that makes them accessible to humans. To address this gap, we present MultiMat, a multimodal program synthesis framework that leverages large multimodal models to process both visual and textual graph representations for improved generation of procedural material graphs. We train our models on a new dataset of production-quality procedural materials and combine them with a constrained tree search inference algorithm that ensures syntactic validity while efficiently navigating the program space. Our experimental results show that our multimodal program synthesis method is more efficient in both unconditional and conditional graph synthesis with higher visual quality and fidelity than text-only baselines, establishing new state-of-the-art performance.
N-BVH: Neural ray queries with bounding volume hierarchies
May 25, 2024



Neural representations have shown spectacular ability to compress complex signals in a fraction of the raw data size. In 3D computer graphics, the bulk of a scene's memory usage is due to polygons and textures, making them ideal candidates for neural compression. Here, the main challenge lies in finding good trade-offs between efficient compression and cheap inference while minimizing training time. In the context of rendering, we adopt a ray-centric approach to this problem and devise N-BVH, a neural compression architecture designed to answer arbitrary ray queries in 3D. Our compact model is learned from the input geometry and substituted for it whenever a ray intersection is queried by a path-tracing engine. While prior neural compression methods have focused on point queries, ours proposes neural ray queries that integrate seamlessly into standard ray-tracing pipelines. At the core of our method, we employ an adaptive BVH-driven probing scheme to optimize the parameters of a multi-resolution hash grid, focusing its neural capacity on the sparse 3D occupancy swept by the original surfaces. As a result, our N-BVH can serve accurate ray queries from a representation that is more than an order of magnitude more compact, providing faithful approximations of visibility, depth, and appearance attributes. The flexibility of our method allows us to combine and overlap neural and non-neural entities within the same 3D scene and extends to appearance level of detail.
* 10 pages
ControlMat: A Controlled Generative Approach to Material Capture
Sep 04, 2023
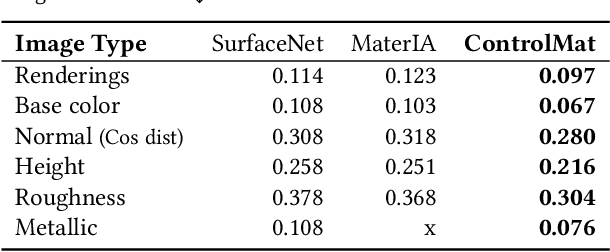
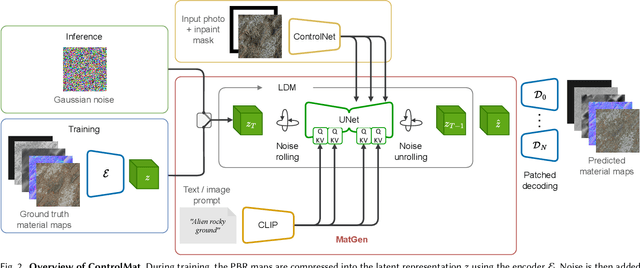

Material reconstruction from a photograph is a key component of 3D content creation democratization. We propose to formulate this ill-posed problem as a controlled synthesis one, leveraging the recent progress in generative deep networks. We present ControlMat, a method which, given a single photograph with uncontrolled illumination as input, conditions a diffusion model to generate plausible, tileable, high-resolution physically-based digital materials. We carefully analyze the behavior of diffusion models for multi-channel outputs, adapt the sampling process to fuse multi-scale information and introduce rolled diffusion to enable both tileability and patched diffusion for high-resolution outputs. Our generative approach further permits exploration of a variety of materials which could correspond to the input image, mitigating the unknown lighting conditions. We show that our approach outperforms recent inference and latent-space-optimization methods, and carefully validate our diffusion process design choices. Supplemental materials and additional details are available at: https://gvecchio.com/controlmat/.
The Visual Language of Fabrics
Jul 25, 2023



We introduce text2fabric, a novel dataset that links free-text descriptions to various fabric materials. The dataset comprises 15,000 natural language descriptions associated to 3,000 corresponding images of fabric materials. Traditionally, material descriptions come in the form of tags/keywords, which limits their expressivity, induces pre-existing knowledge of the appropriate vocabulary, and ultimately leads to a chopped description system. Therefore, we study the use of free-text as a more appropriate way to describe material appearance, taking the use case of fabrics as a common item that non-experts may often deal with. Based on the analysis of the dataset, we identify a compact lexicon, set of attributes and key structure that emerge from the descriptions. This allows us to accurately understand how people describe fabrics and draw directions for generalization to other types of materials. We also show that our dataset enables specializing large vision-language models such as CLIP, creating a meaningful latent space for fabric appearance, and significantly improving applications such as fine-grained material retrieval and automatic captioning.
CPFN: Cascaded Primitive Fitting Networks for High-Resolution Point Clouds
Sep 06, 2021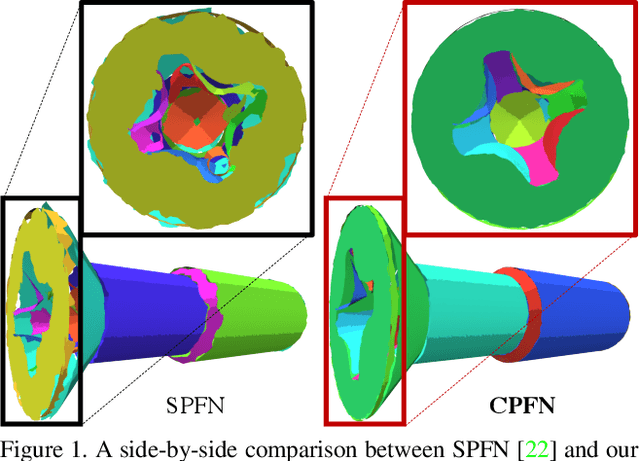
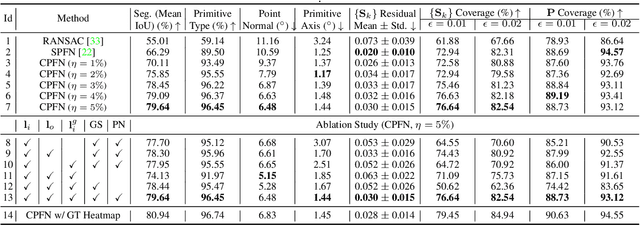
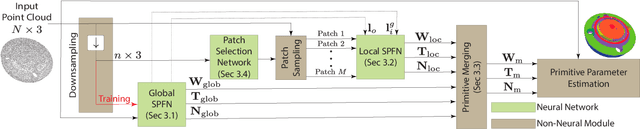
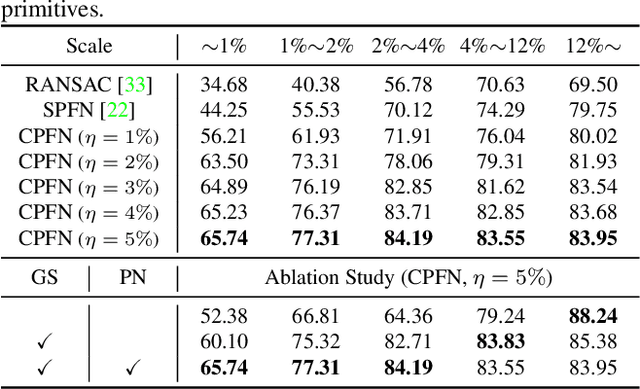
Representing human-made objects as a collection of base primitives has a long history in computer vision and reverse engineering. In the case of high-resolution point cloud scans, the challenge is to be able to detect both large primitives as well as those explaining the detailed parts. While the classical RANSAC approach requires case-specific parameter tuning, state-of-the-art networks are limited by memory consumption of their backbone modules such as PointNet++, and hence fail to detect the fine-scale primitives. We present Cascaded Primitive Fitting Networks (CPFN) that relies on an adaptive patch sampling network to assemble detection results of global and local primitive detection networks. As a key enabler, we present a merging formulation that dynamically aggregates the primitives across global and local scales. Our evaluation demonstrates that CPFN improves the state-of-the-art SPFN performance by 13-14% on high-resolution point cloud datasets and specifically improves the detection of fine-scale primitives by 20-22%.
* ICCV 2021: 15 pages, 8 figures
Learning Generative Models of Shape Handles
Apr 06, 2020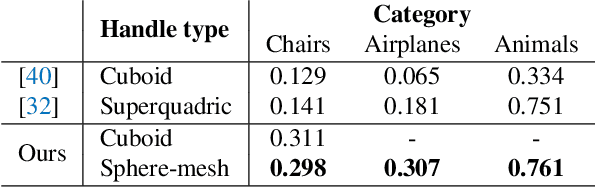
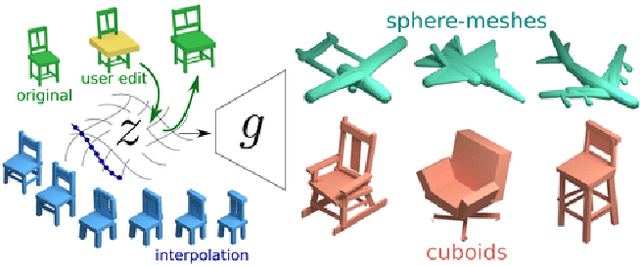

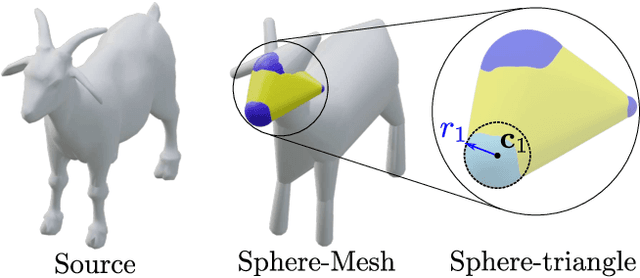
We present a generative model to synthesize 3D shapes as sets of handles -- lightweight proxies that approximate the original 3D shape -- for applications in interactive editing, shape parsing, and building compact 3D representations. Our model can generate handle sets with varying cardinality and different types of handles (Figure 1). Key to our approach is a deep architecture that predicts both the parameters and existence of shape handles, and a novel similarity measure that can easily accommodate different types of handles, such as cuboids or sphere-meshes. We leverage the recent advances in semantic 3D annotation as well as automatic shape summarizing techniques to supervise our approach. We show that the resulting shape representations are intuitive and achieve superior quality than previous state-of-the-art. Finally, we demonstrate how our method can be used in applications such as interactive shape editing, completion, and interpolation, leveraging the latent space learned by our model to guide these tasks. Project page: http://mgadelha.me/shapehandles.
Geometric Proxies for Live RGB-D Stream Enhancement and Consolidation
Jan 21, 2020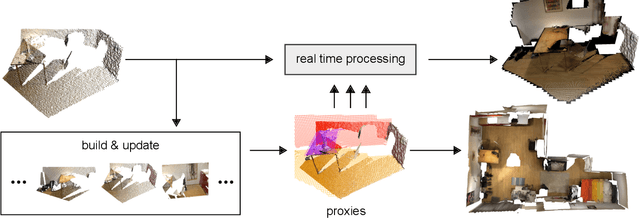
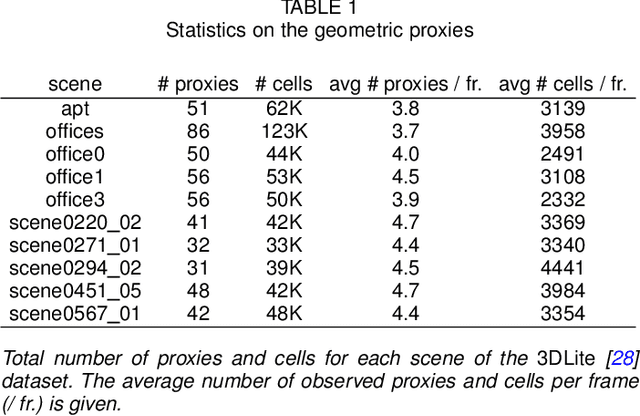


We propose a geometric superstructure for unified real-time processing of RGB-D data. Modern RGB-D sensors are widely used for indoor 3D capture, with applications ranging from modeling to robotics, through augmented reality. Nevertheless, their use is limited by their low resolution, with frames often corrupted with noise, missing data and temporal inconsistencies. Our approach consists in generating and updating through time a single set of compact local statistics parameterized over detected geometric proxies, which are fed from raw RGB-D data. Our proxies provide several processing primitives, which improve the quality of the RGB-D stream on the fly or lighten further operations. Experimental results confirm that our lightweight analysis framework copes well with embedded execution as well as moderate memory and computational capabilities compared to state-of-the-art methods. Processing RGB-D data with our proxies allows noise and temporal flickering removal, hole filling and resampling. As a substitute of the observed scene, our proxies can additionally be applied to compression and scene reconstruction. We present experiments performed with our framework in indoor scenes of different natures within a recent open RGB-D dataset.
Plane Pair Matching for Efficient 3D View Registration
Jan 20, 2020
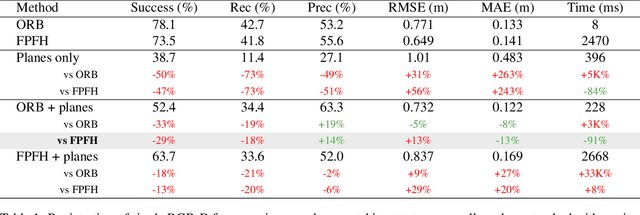


We present a novel method to estimate the motion matrix between overlapping pairs of 3D views in the context of indoor scenes. We use the Manhattan world assumption to introduce lightweight geometric constraints under the form of planes into the problem, which reduces complexity by taking into account the structure of the scene. In particular, we define a stochastic framework to categorize planes as vertical or horizontal and parallel or non-parallel. We leverage this classification to match pairs of planes in overlapping views with point-of-view agnostic structural metrics. We propose to split the motion computation using the classification and estimate separately the rotation and translation of the sensor, using a quadric minimizer. We validate our approach on a toy example and present quantitative experiments on a public RGB-D dataset, comparing against recent state-of-the-art methods. Our evaluation shows that planar constraints only add low computational overhead while improving results in precision when applied after a prior coarse estimate. We conclude by giving hints towards extensions and improvements of current results.