 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormal-guided Garment UV Prediction for Human Re-texturing
Mar 11, 2023



Clothes undergo complex geometric deformations, which lead to appearance changes. To edit human videos in a physically plausible way, a texture map must take into account not only the garment transformation induced by the body movements and clothes fitting, but also its 3D fine-grained surface geometry. This poses, however, a new challenge of 3D reconstruction of dynamic clothes from an image or a video. In this paper, we show that it is possible to edit dressed human images and videos without 3D reconstruction. We estimate a geometry aware texture map between the garment region in an image and the texture space, a.k.a, UV map. Our UV map is designed to preserve isometry with respect to the underlying 3D surface by making use of the 3D surface normals predicted from the image. Our approach captures the underlying geometry of the garment in a self-supervised way, requiring no ground truth annotation of UV maps and can be readily extended to predict temporally coherent UV maps. We demonstrate that our method outperforms the state-of-the-art human UV map estimation approaches on both real and synthetic data.
Learning Generative Models of Shape Handles
Apr 06, 2020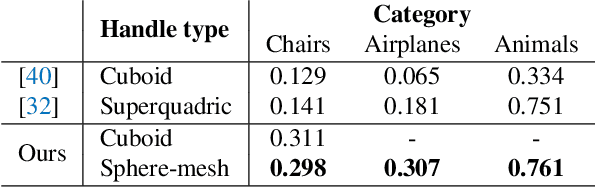
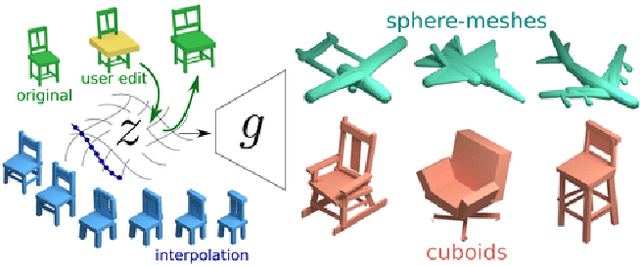

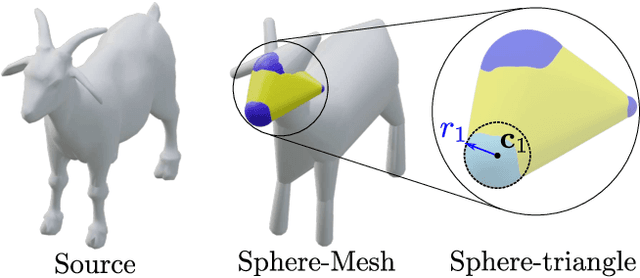
We present a generative model to synthesize 3D shapes as sets of handles -- lightweight proxies that approximate the original 3D shape -- for applications in interactive editing, shape parsing, and building compact 3D representations. Our model can generate handle sets with varying cardinality and different types of handles (Figure 1). Key to our approach is a deep architecture that predicts both the parameters and existence of shape handles, and a novel similarity measure that can easily accommodate different types of handles, such as cuboids or sphere-meshes. We leverage the recent advances in semantic 3D annotation as well as automatic shape summarizing techniques to supervise our approach. We show that the resulting shape representations are intuitive and achieve superior quality than previous state-of-the-art. Finally, we demonstrate how our method can be used in applications such as interactive shape editing, completion, and interpolation, leveraging the latent space learned by our model to guide these tasks. Project page: http://mgadelha.me/shapehandles.
DiffTaichi: Differentiable Programming for Physical Simulation
Oct 01, 2019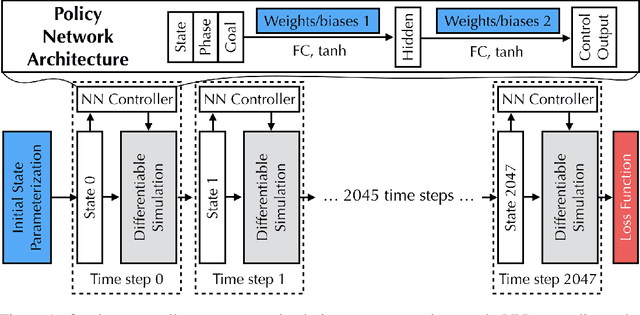

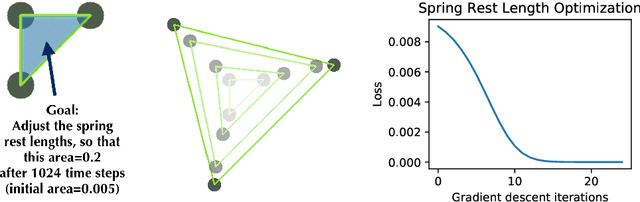

We study the problem of learning and optimizing through physical simulations via differentiable programming. We present DiffTaichi, a new differentiable programming language tailored for building high-performance differentiable physical simulations. We demonstrate the performance and productivity of our language in gradient-based learning and optimization tasks on 10 different physical simulators. For example, a differentiable elastic object simulator written in our language is 4.2x faster than the hand-engineered CUDA version yet runs as fast, and is 188x faster than TensorFlow. Using our differentiable programs, neural network controllers are typically optimized within only tens of iterations. Finally, we share the lessons learned from our experience developing these simulators, that is, differentiating physical simulators does not always yield useful gradients of the physical system being simulated. We systematically study the underlying reasons and propose solutions to improve gradient quality.
Fast Spatially-Varying Indoor Lighting Estimation
Jun 10, 2019
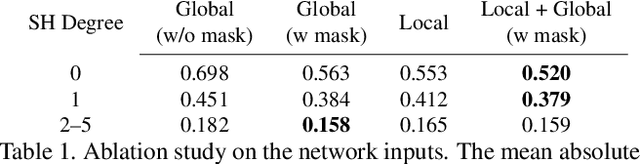

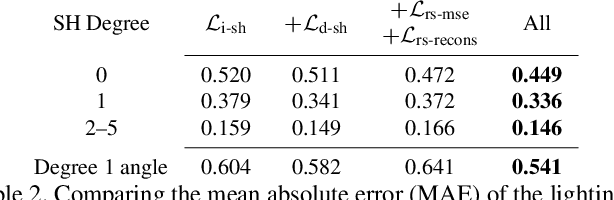
We propose a real-time method to estimate spatiallyvarying indoor lighting from a single RGB image. Given an image and a 2D location in that image, our CNN estimates a 5th order spherical harmonic representation of the lighting at the given location in less than 20ms on a laptop mobile graphics card. While existing approaches estimate a single, global lighting representation or require depth as input, our method reasons about local lighting without requiring any geometry information. We demonstrate, through quantitative experiments including a user study, that our results achieve lower lighting estimation errors and are preferred by users over the state-of-the-art. Our approach can be used directly for augmented reality applications, where a virtual object is relit realistically at any position in the scene in real-time.
* CVPR19
SeeThrough: Finding Chairs in Heavily Occluded Indoor Scene Images
Dec 04, 2017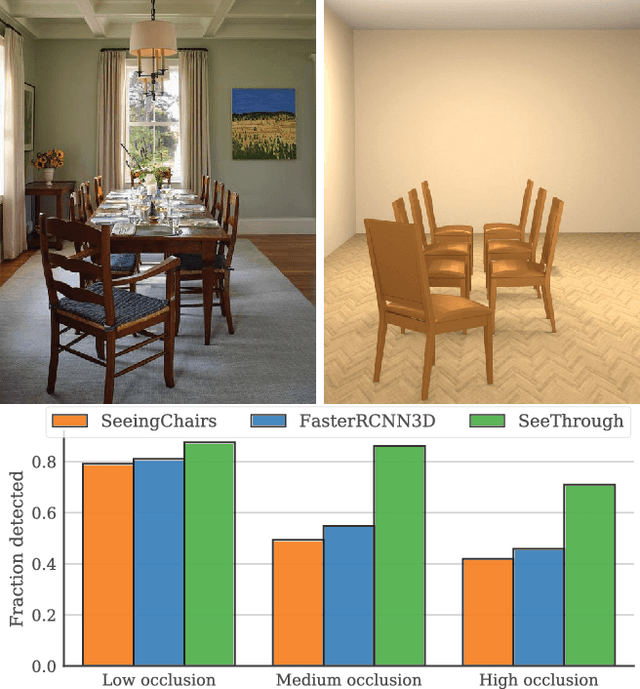

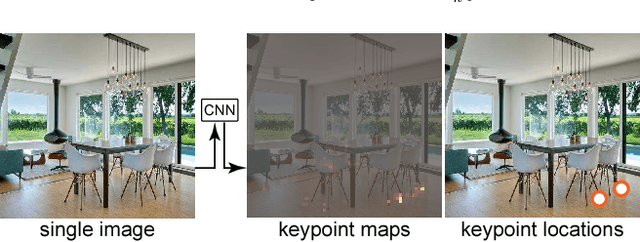
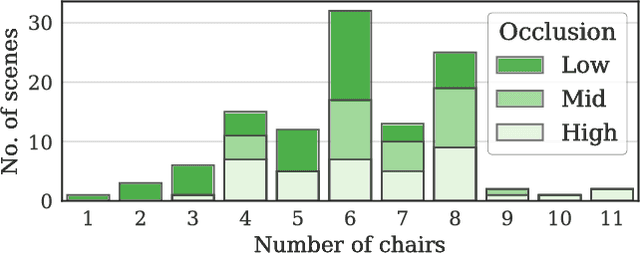
Discovering 3D arrangements of objects from single indoor images is important given its many applications including interior design, content creation, etc. Although heavily researched in the recent years, existing approaches break down under medium or heavy occlusion as the core object detection module starts failing in absence of directly visible cues. Instead, we take into account holistic contextual 3D information, exploiting the fact that objects in indoor scenes co-occur mostly in typical near-regular configurations. First, we use a neural network trained on real indoor annotated images to extract 2D keypoints, and feed them to a 3D candidate object generation stage. Then, we solve a global selection problem among these 3D candidates using pairwise co-occurrence statistics discovered from a large 3D scene database. We iterate the process allowing for candidates with low keypoint response to be incrementally detected based on the location of the already discovered nearby objects. Focusing on chairs, we demonstrate significant performance improvement over combinations of state-of-the-art methods, especially for scenes with moderately to severely occluded objects.
A Visual Representation for Editing Face Images
Dec 02, 2016

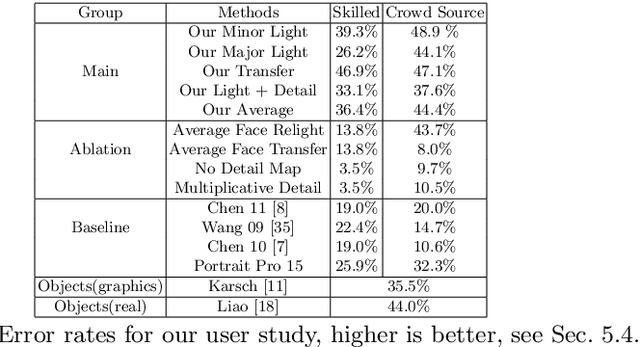

We propose a new approach for editing face images, which enables numerous exciting applications including face relighting, makeup transfer and face detail editing. Our face edits are based on a visual representation, which includes geometry, face segmentation, albedo, illumination and detail map. To recover our visual representation, we start by estimating geometry using a morphable face model, then decompose the face image to recover the albedo, and then shade the geometry with the albedo and illumination. The residual between our shaded geometry and the input image produces our detail map, which carries high frequency information that is either insufficiently or incorrectly captured by our shading process. By manipulating the detail map, we can edit face images with reality and identity preserved. Our representation allows various applications. First, it allows a user to directly manipulate various illumination. Second, it allows non-parametric makeup transfer with input face's distinctive identity features preserved. Third, it allows non-parametric modifications to the face appearance by transferring details. For face relighting and detail editing, we evaluate via a user study and our method outperforms other methods. For makeup transfer, we evaluate via an online attractiveness evaluation system, and can reliably make people look younger and more attractive. We also show extensive qualitative comparisons to existing methods, and have significant improvements over previous techniques.