 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Contrastive Loss for Zero-Day Network Intrusion Detection
Jan 14, 2026Machine learning has achieved state-of-the-art results in network intrusion detection; however, its performance significantly degrades when confronted by a new attack class -- a zero-day attack. In simple terms, classical machine learning-based approaches are adept at identifying attack classes on which they have been previously trained, but struggle with those not included in their training data. One approach to addressing this shortcoming is to utilise anomaly detectors which train exclusively on benign data with the goal of generalising to all attack classes -- both known and zero-day. However, this comes at the expense of a prohibitively high false positive rate. This work proposes a novel contrastive loss function which is able to maintain the advantages of other contrastive learning-based approaches (robustness to imbalanced data) but can also generalise to zero-day attacks. Unlike anomaly detectors, this model learns the distributions of benign traffic using both benign and known malign samples, i.e. other well-known attack classes (not including the zero-day class), and consequently, achieves significant performance improvements. The proposed approach is experimentally verified on the Lycos2017 dataset where it achieves an AUROC improvement of .000065 and .060883 over previous models in known and zero-day attack detection, respectively. Finally, the proposed method is extended to open-set recognition achieving OpenAUC improvements of .170883 over existing approaches.
* Published in: IEEE Transactions on Network Service and Management (TNSM), 2026. Official version: https://ieeexplore.ieee.org/document/11340750 Code: https://github.com/jackwilkie/CLOSR
Non-invasive Diver Respiration Rate Monitoring in Hyperbaric Lifeboat Environments using Short-Range Radar
Apr 15, 2024

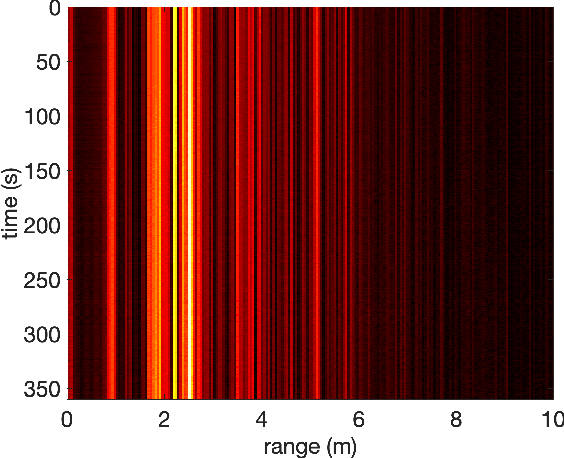

The monitoring of diver health during emergency events is crucial to ensuring the safety of personnel. A non-invasive system continuously providing a measure of the respiration rate of individual divers is exceedingly beneficial in this context. The paper reports on the application of short-range radar to record the respiration rate of divers within hyperbaric lifeboat environments. Results demonstrate that the respiratory motion can be extracted from the radar return signal applying routine signal processing. Further, evidence is provided that the radar-based approach yields a more accurate measure of respiration rate than an audio signal from a headset microphone. The system promotes an improvement in evacuation protocols under critical operational scenarios.
On Models and Approaches for Human Vital Signs Extraction from Short Range Radar Signals
Apr 15, 2024



The paper centres on an assessment of the modelling approaches for the processing of signals in CW and FMCW radar-based systems for the detection of vital signs. It is shown that the use of the widely adopted phase extraction method, which relies on the approximation of the target as a single point scatterer, has limitations in respect of the simultaneous estimation of both respiratory and heart rates. A method based on a velocity spectrum is proposed as an alternative with the ability to treat a wider range of application scenarios.
A Novel Micro-Doppler Coherence Loss for Deep Learning Radar Applications
Apr 12, 2024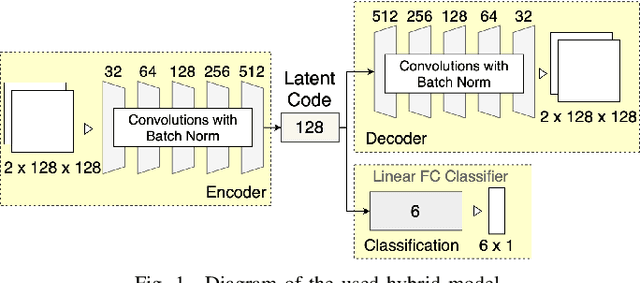

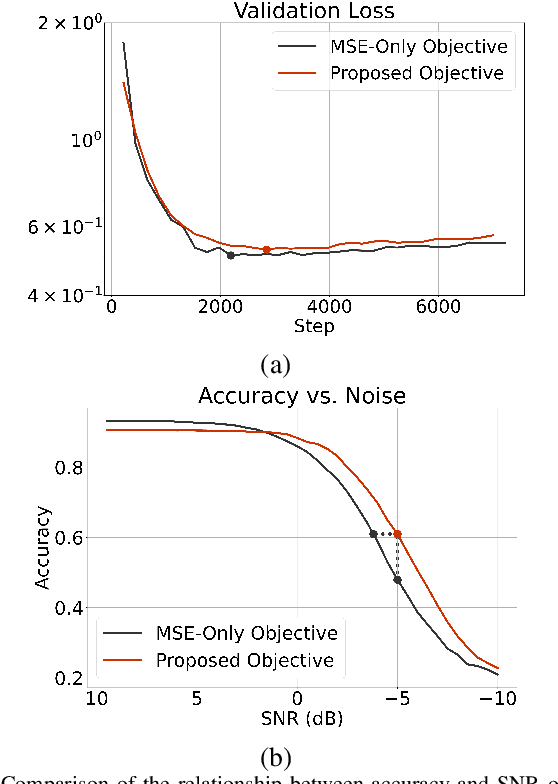
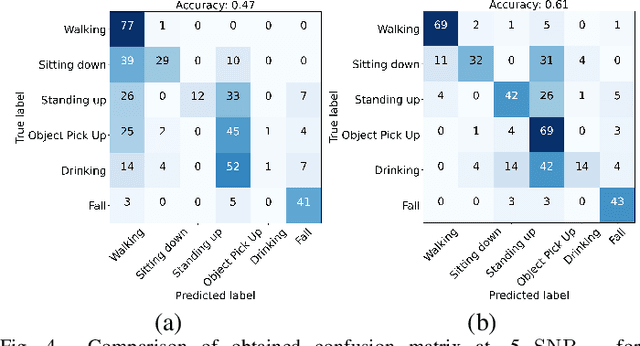
Deep learning techniques are subject to increasing adoption for a wide range of micro-Doppler applications, where predictions need to be made based on time-frequency signal representations. Most, if not all, of the reported applications focus on translating an existing deep learning framework to this new domain with no adjustment made to the objective function. This practice results in a missed opportunity to encourage the model to prioritize features that are particularly relevant for micro-Doppler applications. Thus the paper introduces a micro-Doppler coherence loss, minimized when the normalized power of micro-Doppler oscillatory components between input and output is matched. The experiments conducted on real data show that the application of the introduced loss results in models more resilient to noise.
On Input Formats for Radar Micro-Doppler Signature Processing by Convolutional Neural Networks
Apr 12, 2024



Convolutional neural networks have often been proposed for processing radar Micro-Doppler signatures, most commonly with the goal of classifying the signals. The majority of works tend to disregard phase information from the complex time-frequency representation. Here, the utility of the phase information, as well as the optimal format of the Doppler-time input for a convolutional neural network, is analysed. It is found that the performance achieved by convolutional neural network classifiers is heavily influenced by the type of input representation, even across formats with equivalent information. Furthermore, it is demonstrated that the phase component of the Doppler-time representation contains rich information useful for classification and that unwrapping the phase in the temporal dimension can improve the results compared to a magnitude-only solution, improving accuracy from 0.920 to 0.938 on the tested human activity dataset. Further improvement of 0.947 is achieved by training a linear classifier on embeddings from multiple-formats.
Interference Motion Removal for Doppler Radar Vital Sign Detection Using Variational Encoder-Decoder Neural Network
Apr 12, 2024



The treatment of interfering motion contributions remains one of the key challenges in the domain of radar-based vital sign monitoring. Removal of the interference to extract the vital sign contributions is demanding due to overlapping Doppler bands, the complex structure of the interference motions and significant variations in the power levels of their contributions. A novel approach to the removal of interference through the use of a probabilistic deep learning model is presented. Results show that a convolutional encoder-decoder neural network with a variational objective is capable of learning a meaningful representation space of vital sign Doppler-time distribution facilitating their extraction from a mixture signal. The approach is tested on semi-experimental data containing real vital sign signatures and simulated returns from interfering body motions. The application of the proposed network enhances the extraction of the micro-Doppler frequency corresponding to the respiration rate is demonstrated.
Robustness of Deep Neural Networks for Micro-Doppler Radar Classification
Feb 22, 2024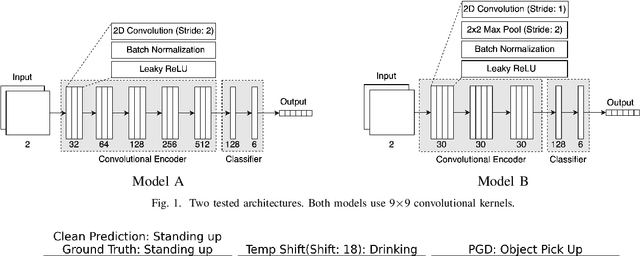
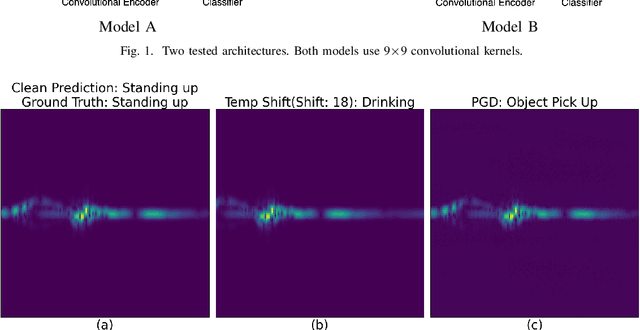
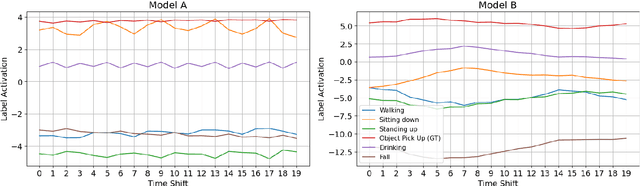
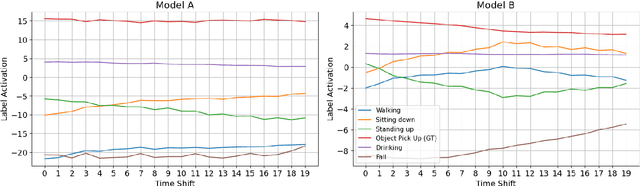
With the great capabilities of deep classifiers for radar data processing come the risks of learning dataset-specific features that do not generalize well. In this work, the robustness of two deep convolutional architectures, trained and tested on the same data, is evaluated. When standard training practice is followed, both classifiers exhibit sensitivity to subtle temporal shifts of the input representation, an augmentation that carries minimal semantic content. Furthermore, the models are extremely susceptible to adversarial examples. Both small temporal shifts and adversarial examples are a result of a model overfitting on features that do not generalize well. As a remedy, it is shown that training on adversarial examples and temporally augmented samples can reduce this effect and lead to models that generalise better. Finally, models operating on cadence-velocity diagram representation rather than Doppler-time are demonstrated to be naturally more immune to adversarial examples.
Exploring the Capability of Text-to-Image Diffusion Models with Structural Edge Guidance for Multi-Spectral Satellite Image Inpainting
Nov 06, 2023
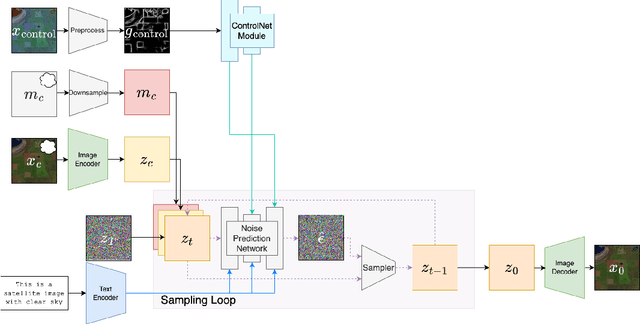


The paper investigates the utility of text-to-image inpainting models for satellite image data. Two technical challenges of injecting structural guiding signals into the generative process as well as translating the inpainted RGB pixels to a wider set of MSI bands are addressed by introducing a novel inpainting framework based on StableDiffusion and ControlNet as well as a novel method for RGB-to-MSI translation. The results on a wider set of data suggest that the inpainting synthesized via StableDiffusion suffers from undesired artefacts and that a simple alternative of self-supervised internal inpainting achieves higher quality of synthesis.
Detecting Cloud Presence in Satellite Images Using the RGB-based CLIP Vision-Language Model
Aug 01, 2023

This work explores capabilities of the pre-trained CLIP vision-language model to identify satellite images affected by clouds. Several approaches to using the model to perform cloud presence detection are proposed and evaluated, including a purely zero-shot operation with text prompts and several fine-tuning approaches. Furthermore, the transferability of the methods across different datasets and sensor types (Sentinel-2 and Landsat-8) is tested. The results that CLIP can achieve non-trivial performance on the cloud presence detection task with apparent capability to generalise across sensing modalities and sensing bands. It is also found that a low-cost fine-tuning stage leads to a strong increase in true negative rate. The results demonstrate that the representations learned by the CLIP model can be useful for satellite image processing tasks involving clouds.
Neural Weight Step Video Compression
Dec 02, 2021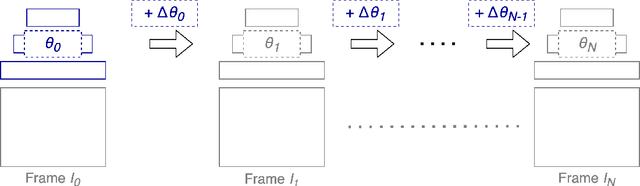
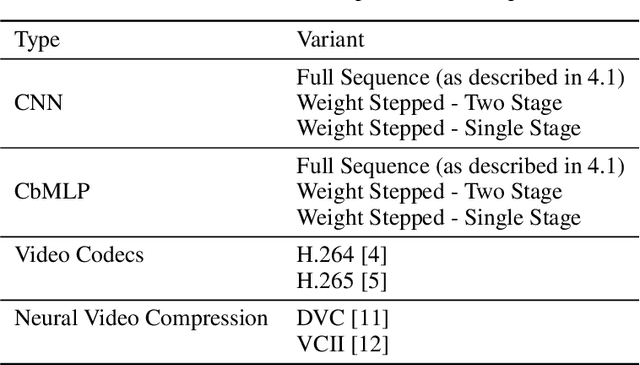
A variety of compression methods based on encoding images as weights of a neural network have been recently proposed. Yet, the potential of similar approaches for video compression remains unexplored. In this work, we suggest a set of experiments for testing the feasibility of compressing video using two architectural paradigms, coordinate-based MLP (CbMLP) and convolutional network. Furthermore, we propose a novel technique of neural weight stepping, where subsequent frames of a video are encoded as low-entropy parameter updates. To assess the feasibility of the considered approaches, we will test the video compression performance on several high-resolution video datasets and compare against existing conventional and neural compression techniques.