 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Weight Step Video Compression
Dec 02, 2021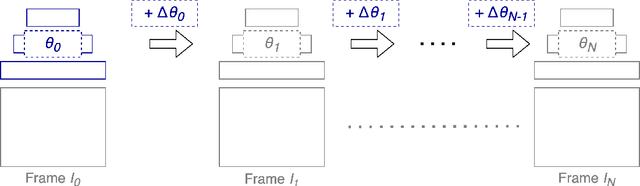
A variety of compression methods based on encoding images as weights of a neural network have been recently proposed. Yet, the potential of similar approaches for video compression remains unexplored. In this work, we suggest a set of experiments for testing the feasibility of compressing video using two architectural paradigms, coordinate-based MLP (CbMLP) and convolutional network. Furthermore, we propose a novel technique of neural weight stepping, where subsequent frames of a video are encoded as low-entropy parameter updates. To assess the feasibility of the considered approaches, we will test the video compression performance on several high-resolution video datasets and compare against existing conventional and neural compression techniques.
Neural Knitworks: Patched Neural Implicit Representation Networks
Sep 29, 2021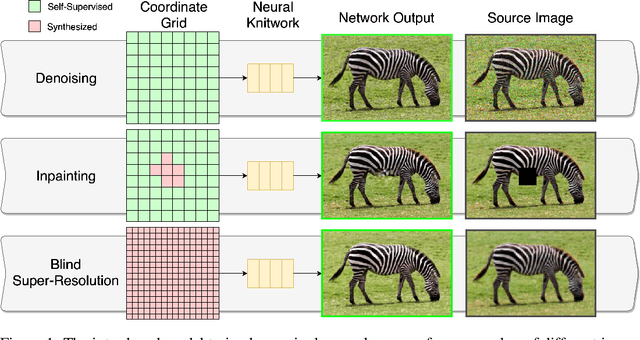
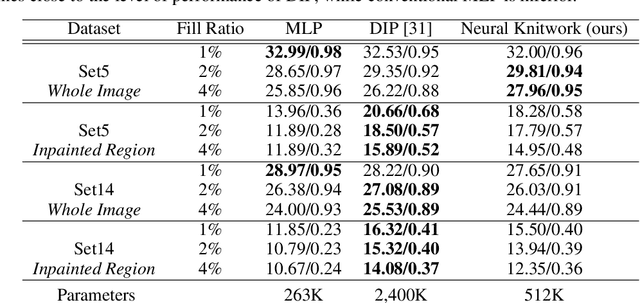
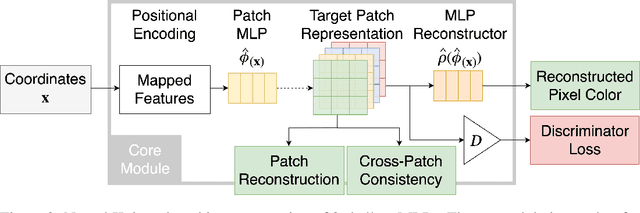
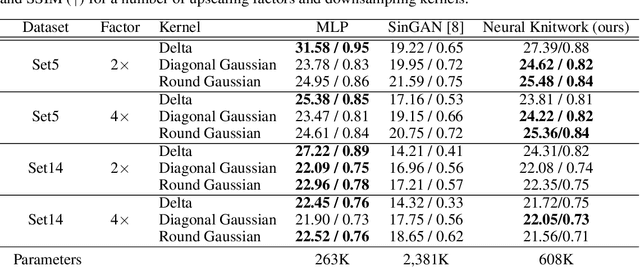
Coordinate-based Multilayer Perceptron (MLP) networks, despite being capable of learning neural implicit representations, are not performant for internal image synthesis applications. Convolutional Neural Networks (CNNs) are typically used instead for a variety of internal generative tasks, at the cost of a larger model. We propose Neural Knitwork, an architecture for neural implicit representation learning of natural images that achieves image synthesis by optimizing the distribution of image patches in an adversarial manner and by enforcing consistency between the patch predictions. To the best of our knowledge, this is the first implementation of a coordinate-based MLP tailored for synthesis tasks such as image inpainting, super-resolution, and denoising. We demonstrate the utility of the proposed technique by training on these three tasks. The results show that modeling natural images using patches, rather than pixels, produces results of higher fidelity. The resulting model requires 80% fewer parameters than alternative CNN-based solutions while achieving comparable performance and training time.