 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Gradient Signal-to-Noise Data Selection for Instruction Tuning
Jan 20, 2026Instruction tuning is a standard paradigm for adapting large language models (LLMs), but modern instruction datasets are large, noisy, and redundant, making full-data fine-tuning costly and often unnecessary. Existing data selection methods either build expensive gradient datastores or assign static scores from a weak proxy, largely ignoring evolving uncertainty, and thus missing a key source of LLM interpretability. We propose GRADFILTERING, an objective-agnostic, uncertainty-aware data selection framework that utilizes a small GPT-2 proxy with a LoRA ensemble and aggregates per-example gradients into a Gradient Signal-to-Noise Ratio (G-SNR) utility. Our method matches or surpasses random subsets and strong baselines in most LLM-as-a-judge evaluations as well as in human assessment. Moreover, GRADFILTERING-selected subsets converge faster than competitive filters under the same compute budget, reflecting the benefit of uncertainty-aware scoring.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025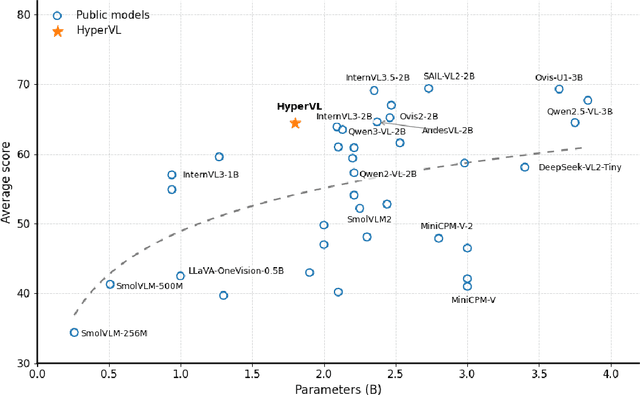

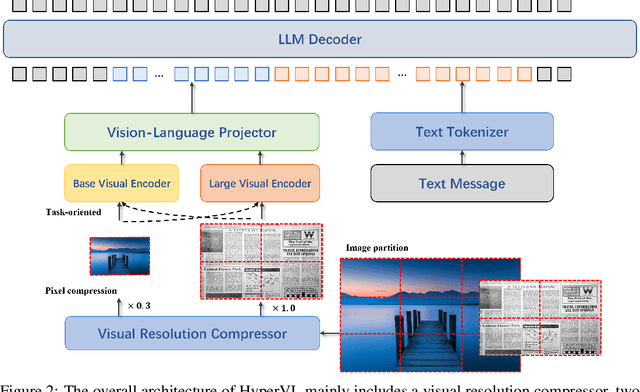

Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
Taming the Chaos: Coordinated Autoscaling for Heterogeneous and Disaggregated LLM Inference
Aug 27, 2025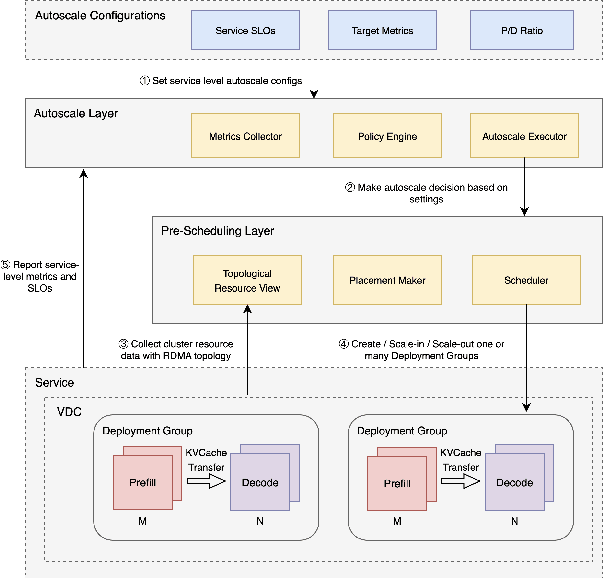

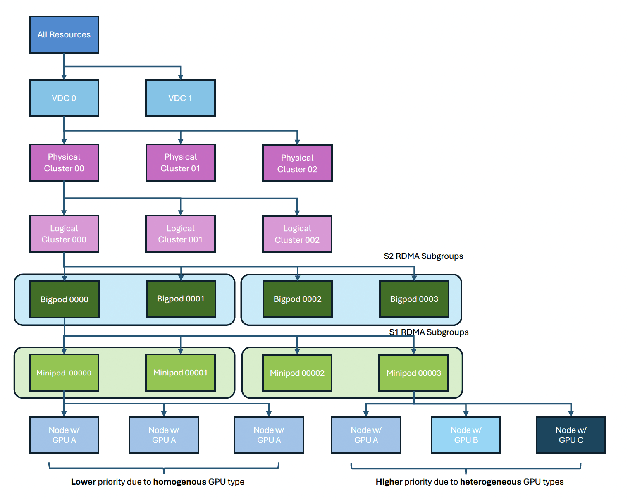
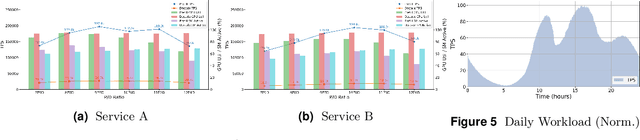
Serving Large Language Models (LLMs) is a GPU-intensive task where traditional autoscalers fall short, particularly for modern Prefill-Decode (P/D) disaggregated architectures. This architectural shift, while powerful, introduces significant operational challenges, including inefficient use of heterogeneous hardware, network bottlenecks, and critical imbalances between prefill and decode stages. We introduce HeteroScale, a coordinated autoscaling framework that addresses the core challenges of P/D disaggregated serving. HeteroScale combines a topology-aware scheduler that adapts to heterogeneous hardware and network constraints with a novel metric-driven policy derived from the first large-scale empirical study of autoscaling signals in production. By leveraging a single, robust metric to jointly scale prefill and decode pools, HeteroScale maintains architectural balance while ensuring efficient, adaptive resource management. Deployed in a massive production environment on tens of thousands of GPUs, HeteroScale has proven its effectiveness, increasing average GPU utilization by a significant 26.6 percentage points and saving hundreds of thousands of GPU-hours daily, all while upholding stringent service level objectives.
HQOD: Harmonious Quantization for Object Detection
Aug 05, 2024

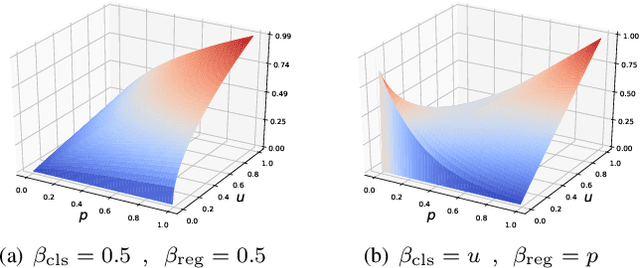
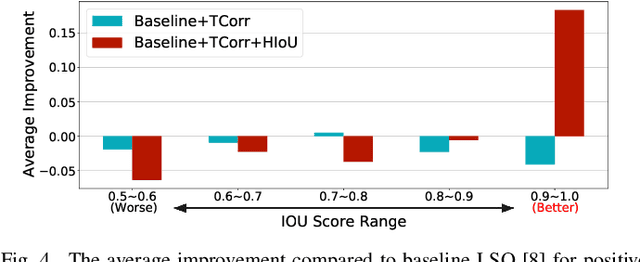
Task inharmony problem commonly occurs in modern object detectors, leading to inconsistent qualities between classification and regression tasks. The predicted boxes with high classification scores but poor localization positions or low classification scores but accurate localization positions will worsen the performance of detectors after Non-Maximum Suppression. Furthermore, when object detectors collaborate with Quantization-Aware Training (QAT), we observe that the task inharmony problem will be further exacerbated, which is considered one of the main causes of the performance degradation of quantized detectors. To tackle this issue, we propose the Harmonious Quantization for Object Detection (HQOD) framework, which consists of two components. Firstly, we propose a task-correlated loss to encourage detectors to focus on improving samples with lower task harmony quality during QAT. Secondly, a harmonious Intersection over Union (IoU) loss is incorporated to balance the optimization of the regression branch across different IoU levels. The proposed HQOD can be easily integrated into different QAT algorithms and detectors. Remarkably, on the MS COCO dataset, our 4-bit ATSS with ResNet-50 backbone achieves a state-of-the-art mAP of 39.6%, even surpassing the full-precision one.
Soft Multipath Information-Based UWB Tracking in Cluttered Scenarios: Preliminaries and Validations
May 29, 2024



In this paper, we investigate ultra-wideband (UWB) localization and tracking in cluttered environments. Instead of mitigating the multipath, we exploit the specular reflections to enhance the localizability and improve the positioning accuracy. With the assistance of the multipath, it is also possible to achieve localization purposes using fewer anchors or when the line-of-sight propagations are blocked. Rather than using single-value distance, angle, or Doppler estimates for the localization, we model the likelihoods of both the line-of-sight and specular multipath components, namely soft multipath information, and propose the multipath-assisted probabilistic UWB tracking algorithm. Experimental results in a cluttered industrial scenario show that the proposed algorithm achieves 46.4 cm and 33.1 cm 90th percentile errors in the cases of 3 and 4 anchors, respectively, which outperforms conventional methods with more than 61.8% improvement given fewer anchors and strong multipath effect.
Only the Curve Shape Matters: Training Foundation Models for Zero-Shot Multivariate Time Series Forecasting through Next Curve Shape Prediction
Feb 19, 2024


We present General Time Transformer (GTT), an encoder-only style foundation model for zero-shot multivariate time series forecasting. GTT is pretrained on a large dataset of 200M high-quality time series samples spanning diverse domains. In our proposed framework, the task of multivariate time series forecasting is formulated as a channel-wise next curve shape prediction problem, where each time series sample is represented as a sequence of non-overlapping curve shapes with a unified numerical magnitude. GTT is trained to predict the next curve shape based on a window of past curve shapes in a channel-wise manner. Experimental results demonstrate that GTT exhibits superior zero-shot multivariate forecasting capabilities on unseen time series datasets, even surpassing state-of-the-art supervised baselines. Additionally, we investigate the impact of varying GTT model parameters and training dataset scales, observing that the scaling law also holds in the context of zero-shot multivariate time series forecasting.
Model Pruning Based on Quantified Similarity of Feature Maps
May 13, 2021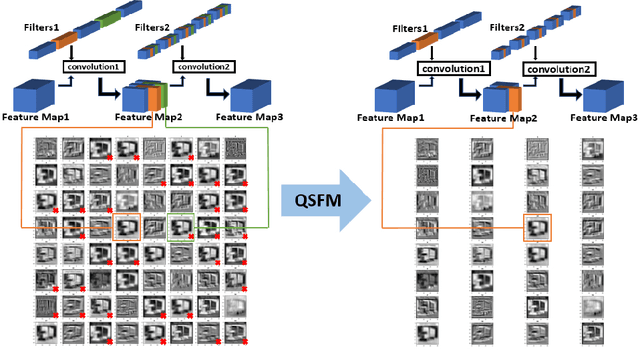

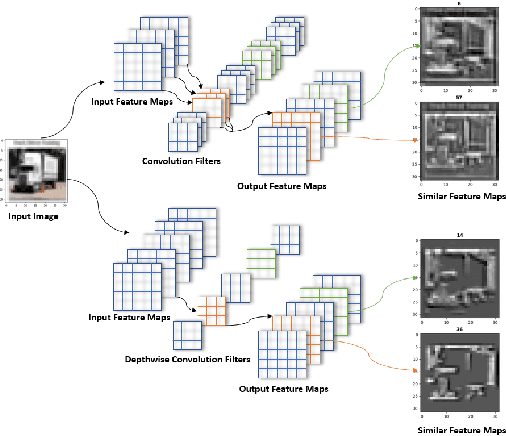
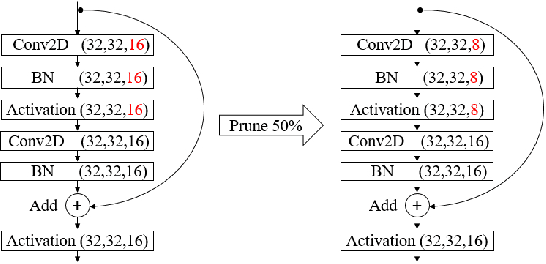
A high-accuracy CNN is often accompanied by huge parameters, which are usually stored in the high-dimensional tensors. However, there are few methods can figure out the redundant information of the parameters stored in the high-dimensional tensors, which leads to the lack of theoretical guidance for the compression of CNNs. In this paper, we propose a novel theory to find redundant information in three dimensional tensors, namely Quantified Similarity of Feature Maps (QSFM), and use this theory to prune convolutional neural networks to enhance the inference speed. Our method belongs to filter pruning, which can be implemented without using any special libraries. We perform our method not only on common convolution layers but also on special convolution layers, such as depthwise separable convolution layers. The experiments prove that QSFM can find the redundant information in the neural network effectively. Without any fine-tuning operation, QSFM can compress ResNet-56 on CIFAR-10 significantly (48.27% FLOPs and 57.90% parameters reduction) with only a loss of 0.54% in the top-1 accuracy. QSFM also prunes ResNet-56, VGG-16 and MobileNetV2 with fine-tuning operation, which also shows excellent results.