 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Machine Unlearning Truly Remove Model Knowledge? A Framework for Auditing Unlearning in LLMs
May 29, 2025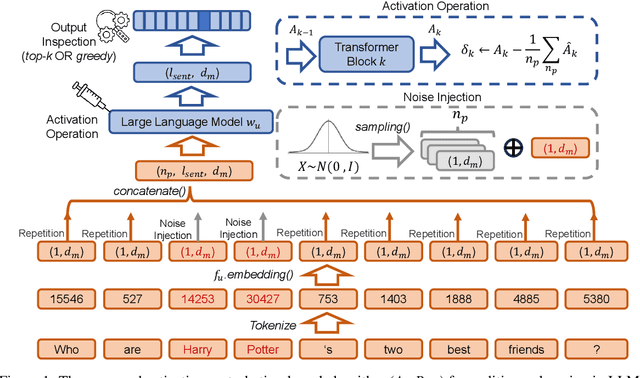
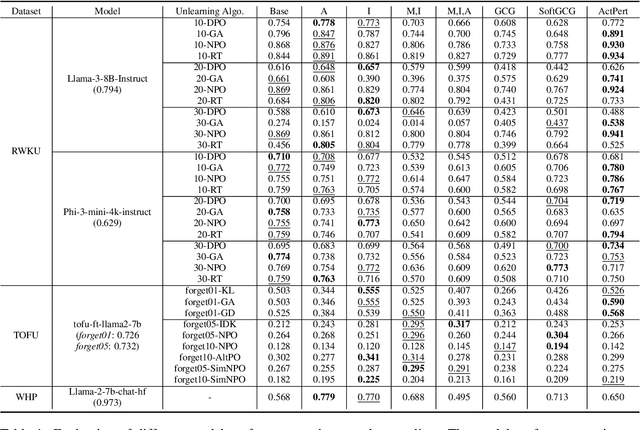
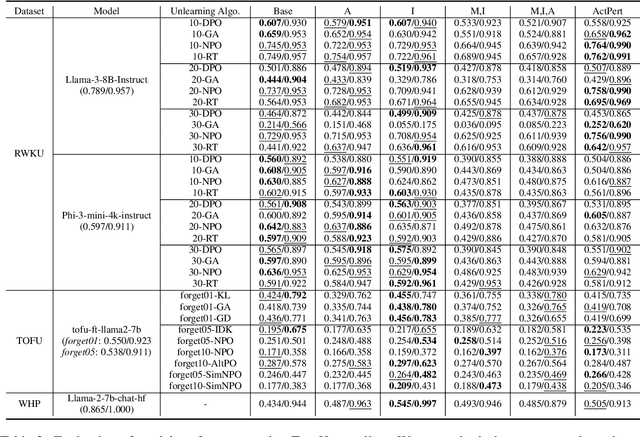
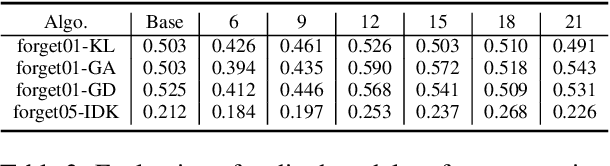
In recent years, Large Language Models (LLMs) have achieved remarkable advancements, drawing significant attention from the research community. Their capabilities are largely attributed to large-scale architectures, which require extensive training on massive datasets. However, such datasets often contain sensitive or copyrighted content sourced from the public internet, raising concerns about data privacy and ownership. Regulatory frameworks, such as the General Data Protection Regulation (GDPR), grant individuals the right to request the removal of such sensitive information. This has motivated the development of machine unlearning algorithms that aim to remove specific knowledge from models without the need for costly retraining. Despite these advancements, evaluating the efficacy of unlearning algorithms remains a challenge due to the inherent complexity and generative nature of LLMs. In this work, we introduce a comprehensive auditing framework for unlearning evaluation, comprising three benchmark datasets, six unlearning algorithms, and five prompt-based auditing methods. By using various auditing algorithms, we evaluate the effectiveness and robustness of different unlearning strategies. To explore alternatives beyond prompt-based auditing, we propose a novel technique that leverages intermediate activation perturbations, addressing the limitations of auditing methods that rely solely on model inputs and outputs.
FedBiP: Heterogeneous One-Shot Federated Learning with Personalized Latent Diffusion Models
Oct 07, 2024



One-Shot Federated Learning (OSFL), a special decentralized machine learning paradigm, has recently gained significant attention. OSFL requires only a single round of client data or model upload, which reduces communication costs and mitigates privacy threats compared to traditional FL. Despite these promising prospects, existing methods face challenges due to client data heterogeneity and limited data quantity when applied to real-world OSFL systems. Recently, Latent Diffusion Models (LDM) have shown remarkable advancements in synthesizing high-quality images through pretraining on large-scale datasets, thereby presenting a potential solution to overcome these issues. However, directly applying pretrained LDM to heterogeneous OSFL results in significant distribution shifts in synthetic data, leading to performance degradation in classification models trained on such data. This issue is particularly pronounced in rare domains, such as medical imaging, which are underrepresented in LDM's pretraining data. To address this challenge, we propose Federated Bi-Level Personalization (FedBiP), which personalizes the pretrained LDM at both instance-level and concept-level. Hereby, FedBiP synthesizes images following the client's local data distribution without compromising the privacy regulations. FedBiP is also the first approach to simultaneously address feature space heterogeneity and client data scarcity in OSFL. Our method is validated through extensive experiments on three OSFL benchmarks with feature space heterogeneity, as well as on challenging medical and satellite image datasets with label heterogeneity. The results demonstrate the effectiveness of FedBiP, which substantially outperforms other OSFL methods.
Only the Curve Shape Matters: Training Foundation Models for Zero-Shot Multivariate Time Series Forecasting through Next Curve Shape Prediction
Feb 19, 2024


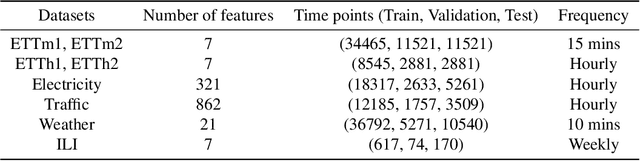
We present General Time Transformer (GTT), an encoder-only style foundation model for zero-shot multivariate time series forecasting. GTT is pretrained on a large dataset of 200M high-quality time series samples spanning diverse domains. In our proposed framework, the task of multivariate time series forecasting is formulated as a channel-wise next curve shape prediction problem, where each time series sample is represented as a sequence of non-overlapping curve shapes with a unified numerical magnitude. GTT is trained to predict the next curve shape based on a window of past curve shapes in a channel-wise manner. Experimental results demonstrate that GTT exhibits superior zero-shot multivariate forecasting capabilities on unseen time series datasets, even surpassing state-of-the-art supervised baselines. Additionally, we investigate the impact of varying GTT model parameters and training dataset scales, observing that the scaling law also holds in the context of zero-shot multivariate time series forecasting.
FedDAT: An Approach for Foundation Model Finetuning in Multi-Modal Heterogeneous Federated Learning
Aug 21, 2023
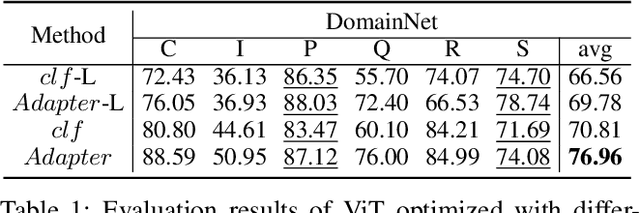
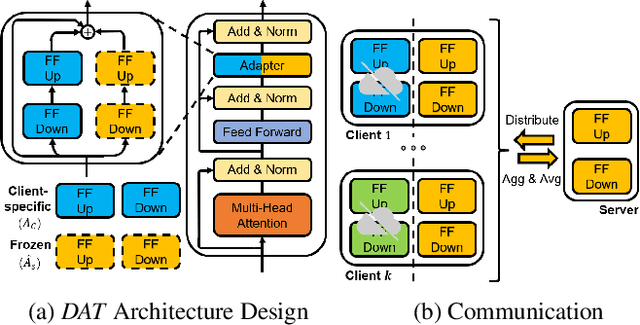
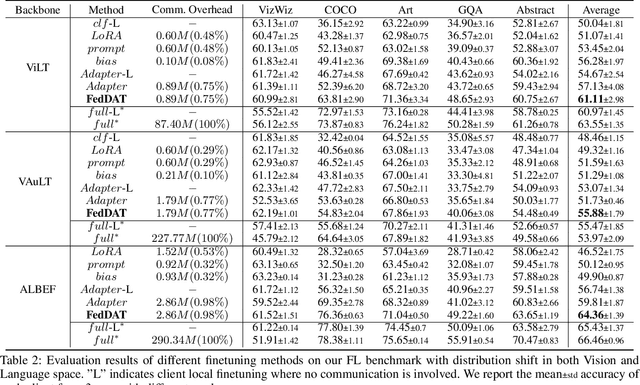
Recently, foundation models have exhibited remarkable advancements in multi-modal learning. These models, equipped with millions (or billions) of parameters, typically require a substantial amount of data for finetuning. However, collecting and centralizing training data from diverse sectors becomes challenging due to distinct privacy regulations. Federated Learning (FL) emerges as a promising solution, enabling multiple clients to collaboratively train neural networks without centralizing their local data. To alleviate client computation burdens and communication overheads, previous works have adapted Parameter-efficient Finetuning (PEFT) methods for FL. Hereby, only a small fraction of the model parameters are optimized and communicated during federated communications. Nevertheless, most previous works have focused on a single modality and neglected one common phenomenon, i.e., the presence of data heterogeneity across the clients. Therefore, in this work, we propose a finetuning framework tailored to heterogeneous multi-modal FL, called Federated Dual-Aadapter Teacher (FedDAT). Specifically, our approach leverages a Dual-Adapter Teacher (DAT) to address data heterogeneity by regularizing the client local updates and applying Mutual Knowledge Distillation (MKD) for an efficient knowledge transfer. FedDAT is the first approach that enables an efficient distributed finetuning of foundation models for a variety of heterogeneous Vision-Language tasks. To demonstrate its effectiveness, we conduct extensive experiments on four multi-modality FL benchmarks with different types of data heterogeneity, where FedDAT substantially outperforms the existing centralized PEFT methods adapted for FL.
FedPop: Federated Population-based Hyperparameter Tuning
Aug 16, 2023Federated Learning (FL) is a distributed machine learning (ML) paradigm, in which multiple clients collaboratively train ML models without centralizing their local data. Similar to conventional ML pipelines, the client local optimization and server aggregation procedure in FL are sensitive to the hyperparameter (HP) selection. Despite extensive research on tuning HPs for centralized ML, these methods yield suboptimal results when employed in FL. This is mainly because their "training-after-tuning" framework is unsuitable for FL with limited client computation power. While some approaches have been proposed for HP-Tuning in FL, they are limited to the HPs for client local updates. In this work, we propose a novel HP-tuning algorithm, called Federated Population-based Hyperparameter Tuning (FedPop), to address this vital yet challenging problem. FedPop employs population-based evolutionary algorithms to optimize the HPs, which accommodates various HP types at both client and server sides. Compared with prior tuning methods, FedPop employs an online "tuning-while-training" framework, offering computational efficiency and enabling the exploration of a broader HP search space. Our empirical validation on the common FL benchmarks and complex real-world FL datasets demonstrates the effectiveness of the proposed method, which substantially outperforms the concurrent state-of-the-art HP tuning methods for FL.
CL-CrossVQA: A Continual Learning Benchmark for Cross-Domain Visual Question Answering
Nov 19, 2022



Visual Question Answering (VQA) is a multi-discipline research task. To produce the right answer, it requires an understanding of the visual content of images, the natural language questions, as well as commonsense reasoning over the information contained in the image and world knowledge. Recently, large-scale Vision-and-Language Pre-trained Models (VLPMs) have been the mainstream approach to VQA tasks due to their superior performance. The standard practice is to fine-tune large-scale VLPMs pre-trained on huge general-domain datasets using the domain-specific VQA datasets. However, in reality, the application domain can change over time, necessitating VLPMs to continually learn and adapt to new domains without forgetting previously acquired knowledge. Most existing continual learning (CL) research concentrates on unimodal tasks, whereas a more practical application scenario, i.e, CL on cross-domain VQA, has not been studied. Motivated by this, we introduce CL-CrossVQA, a rigorous Continual Learning benchmark for Cross-domain Visual Question Answering, through which we conduct extensive experiments on 4 VLPMs, 4 CL approaches, and 5 VQA datasets from different domains. In addition, by probing the forgetting phenomenon of the intermediate layers, we provide insights into how model architecture affects CL performance, why CL approaches can help mitigate forgetting in VLPMs to some extent, and how to design CL approaches suitable for VLPMs in this challenging continual learning environment. To facilitate future work on CL for cross-domain VQA, we will release our datasets and code.
FRAug: Tackling Federated Learning with Non-IID Features via Representation Augmentation
May 30, 2022

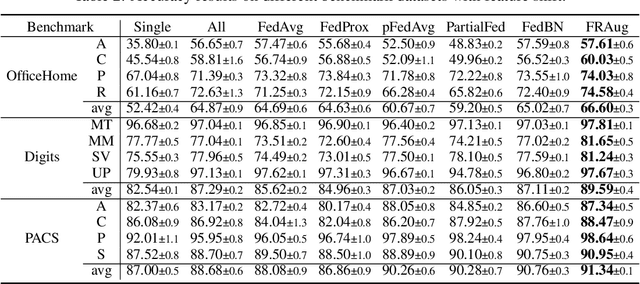
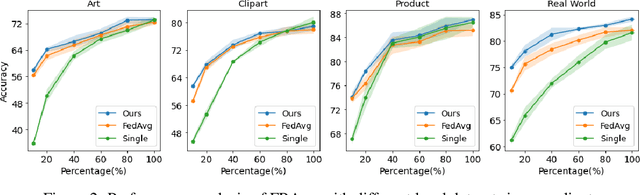
Federated Learning (FL) is a decentralized learning paradigm in which multiple clients collaboratively train deep learning models without centralizing their local data and hence preserve data privacy. Real-world applications usually involve a distribution shift across the datasets of the different clients, which hurts the generalization ability of the clients to unseen samples from their respective data distributions. In this work, we address the recently proposed feature shift problem where the clients have different feature distributions while the label distribution is the same. We propose Federated Representation Augmentation (FRAug) to tackle this practical and challenging problem. Our approach generates synthetic client-specific samples in the embedding space to augment the usually small client datasets. For that, we train a shared generative model to fuse the clients' knowledge, learned from different feature distributions, to synthesize client-agnostic embeddings, which are then locally transformed into client-specific embeddings by Representation Transformation Networks (RTNets). By transferring knowledge across the clients, the generated embeddings act as a regularizer for the client models and reduce overfitting to the local original datasets, hence improving generalization. Our empirical evaluation on multiple benchmark datasets demonstrates the effectiveness of the proposed method, which substantially outperforms the current state-of-the-art FL methods for non-IID features, including PartialFed and FedBN.
Tensor-Train Recurrent Neural Networks for Video Classification
Jul 06, 2017

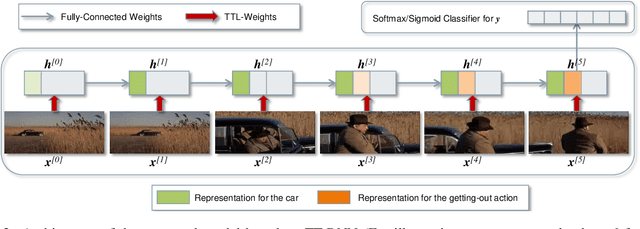

The Recurrent Neural Networks and their variants have shown promising performances in sequence modeling tasks such as Natural Language Processing. These models, however, turn out to be impractical and difficult to train when exposed to very high-dimensional inputs due to the large input-to-hidden weight matrix. This may have prevented RNNs' large-scale application in tasks that involve very high input dimensions such as video modeling; current approaches reduce the input dimensions using various feature extractors. To address this challenge, we propose a new, more general and efficient approach by factorizing the input-to-hidden weight matrix using Tensor-Train decomposition which is trained simultaneously with the weights themselves. We test our model on classification tasks using multiple real-world video datasets and achieve competitive performances with state-of-the-art models, even though our model architecture is orders of magnitude less complex. We believe that the proposed approach provides a novel and fundamental building block for modeling high-dimensional sequential data with RNN architectures and opens up many possibilities to transfer the expressive and advanced architectures from other domains such as NLP to modeling high-dimensional sequential data.
Towards a New Science of a Clinical Data Intelligence
Dec 30, 2013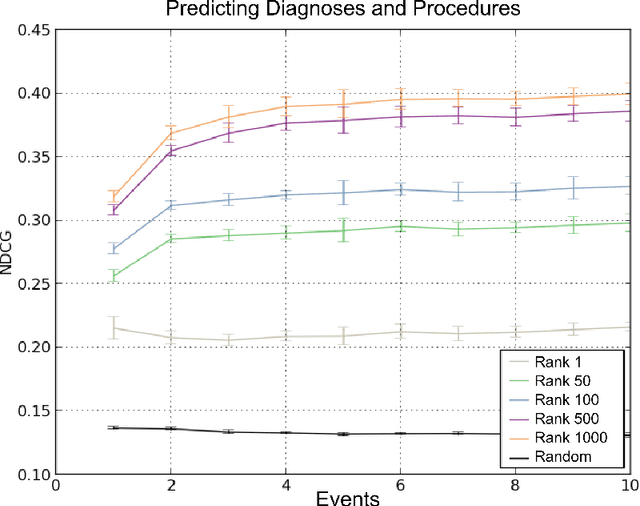
In this paper we define Clinical Data Intelligence as the analysis of data generated in the clinical routine with the goal of improving patient care. We define a science of a Clinical Data Intelligence as a data analysis that permits the derivation of scientific, i.e., generalizable and reliable results. We argue that a science of a Clinical Data Intelligence is sensible in the context of a Big Data analysis, i.e., with data from many patients and with complete patient information. We discuss that Clinical Data Intelligence requires the joint efforts of knowledge engineering, information extraction (from textual and other unstructured data), and statistics and statistical machine learning. We describe some of our main results as conjectures and relate them to a recently funded research project involving two major German university hospitals.