 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacyScalpel: Enhancing LLM Privacy via Interpretable Feature Intervention with Sparse Autoencoders
Mar 14, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language processing but also pose significant privacy risks by memorizing and leaking Personally Identifiable Information (PII). Existing mitigation strategies, such as differential privacy and neuron-level interventions, often degrade model utility or fail to effectively prevent leakage. To address this challenge, we introduce PrivacyScalpel, a novel privacy-preserving framework that leverages LLM interpretability techniques to identify and mitigate PII leakage while maintaining performance. PrivacyScalpel comprises three key steps: (1) Feature Probing, which identifies layers in the model that encode PII-rich representations, (2) Sparse Autoencoding, where a k-Sparse Autoencoder (k-SAE) disentangles and isolates privacy-sensitive features, and (3) Feature-Level Interventions, which employ targeted ablation and vector steering to suppress PII leakage. Our empirical evaluation on Gemma2-2b and Llama2-7b, fine-tuned on the Enron dataset, shows that PrivacyScalpel significantly reduces email leakage from 5.15\% to as low as 0.0\%, while maintaining over 99.4\% of the original model's utility. Notably, our method outperforms neuron-level interventions in privacy-utility trade-offs, demonstrating that acting on sparse, monosemantic features is more effective than manipulating polysemantic neurons. Beyond improving LLM privacy, our approach offers insights into the mechanisms underlying PII memorization, contributing to the broader field of model interpretability and secure AI deployment.
PII-Scope: A Benchmark for Training Data PII Leakage Assessment in LLMs
Oct 09, 2024



In this work, we introduce PII-Scope, a comprehensive benchmark designed to evaluate state-of-the-art methodologies for PII extraction attacks targeting LLMs across diverse threat settings. Our study provides a deeper understanding of these attacks by uncovering several hyperparameters (e.g., demonstration selection) crucial to their effectiveness. Building on this understanding, we extend our study to more realistic attack scenarios, exploring PII attacks that employ advanced adversarial strategies, including repeated and diverse querying, and leveraging iterative learning for continual PII extraction. Through extensive experimentation, our results reveal a notable underestimation of PII leakage in existing single-query attacks. In fact, we show that with sophisticated adversarial capabilities and a limited query budget, PII extraction rates can increase by up to fivefold when targeting the pretrained model. Moreover, we evaluate PII leakage on finetuned models, showing that they are more vulnerable to leakage than pretrained models. Overall, our work establishes a rigorous empirical benchmark for PII extraction attacks in realistic threat scenarios and provides a strong foundation for developing effective mitigation strategies.
ObfuscaTune: Obfuscated Offsite Fine-tuning and Inference of Proprietary LLMs on Private Datasets
Jul 03, 2024This work addresses the timely yet underexplored problem of performing inference and finetuning of a proprietary LLM owned by a model provider entity on the confidential/private data of another data owner entity, in a way that ensures the confidentiality of both the model and the data. Hereby, the finetuning is conducted offsite, i.e., on the computation infrastructure of a third-party cloud provider. We tackle this problem by proposing ObfuscaTune, a novel, efficient and fully utility-preserving approach that combines a simple yet effective obfuscation technique with an efficient usage of confidential computing (only 5% of the model parameters are placed on TEE). We empirically demonstrate the effectiveness of ObfuscaTune by validating it on GPT-2 models with different sizes on four NLP benchmark datasets. Finally, we compare to a na\"ive version of our approach to highlight the necessity of using random matrices with low condition numbers in our approach to reduce errors induced by the obfuscation.
IncogniText: Privacy-enhancing Conditional Text Anonymization via LLM-based Private Attribute Randomization
Jul 03, 2024



In this work, we address the problem of text anonymization where the goal is to prevent adversaries from correctly inferring private attributes of the author, while keeping the text utility, i.e., meaning and semantics. We propose IncogniText, a technique that anonymizes the text to mislead a potential adversary into predicting a wrong private attribute value. Our empirical evaluation shows a reduction of private attribute leakage by more than 90%. Finally, we demonstrate the maturity of IncogniText for real-world applications by distilling its anonymization capability into a set of LoRA parameters associated with an on-device model.
PII-Compass: Guiding LLM training data extraction prompts towards the target PII via grounding
Jul 03, 2024



The latest and most impactful advances in large models stem from their increased size. Unfortunately, this translates into an improved memorization capacity, raising data privacy concerns. Specifically, it has been shown that models can output personal identifiable information (PII) contained in their training data. However, reported PIII extraction performance varies widely, and there is no consensus on the optimal methodology to evaluate this risk, resulting in underestimating realistic adversaries. In this work, we empirically demonstrate that it is possible to improve the extractability of PII by over ten-fold by grounding the prefix of the manually constructed extraction prompt with in-domain data. Our approach, PII-Compass, achieves phone number extraction rates of 0.92%, 3.9%, and 6.86% with 1, 128, and 2308 queries, respectively, i.e., the phone number of 1 person in 15 is extractable.
CL-CrossVQA: A Continual Learning Benchmark for Cross-Domain Visual Question Answering
Nov 19, 2022



Visual Question Answering (VQA) is a multi-discipline research task. To produce the right answer, it requires an understanding of the visual content of images, the natural language questions, as well as commonsense reasoning over the information contained in the image and world knowledge. Recently, large-scale Vision-and-Language Pre-trained Models (VLPMs) have been the mainstream approach to VQA tasks due to their superior performance. The standard practice is to fine-tune large-scale VLPMs pre-trained on huge general-domain datasets using the domain-specific VQA datasets. However, in reality, the application domain can change over time, necessitating VLPMs to continually learn and adapt to new domains without forgetting previously acquired knowledge. Most existing continual learning (CL) research concentrates on unimodal tasks, whereas a more practical application scenario, i.e, CL on cross-domain VQA, has not been studied. Motivated by this, we introduce CL-CrossVQA, a rigorous Continual Learning benchmark for Cross-domain Visual Question Answering, through which we conduct extensive experiments on 4 VLPMs, 4 CL approaches, and 5 VQA datasets from different domains. In addition, by probing the forgetting phenomenon of the intermediate layers, we provide insights into how model architecture affects CL performance, why CL approaches can help mitigate forgetting in VLPMs to some extent, and how to design CL approaches suitable for VLPMs in this challenging continual learning environment. To facilitate future work on CL for cross-domain VQA, we will release our datasets and code.
FRAug: Tackling Federated Learning with Non-IID Features via Representation Augmentation
May 30, 2022

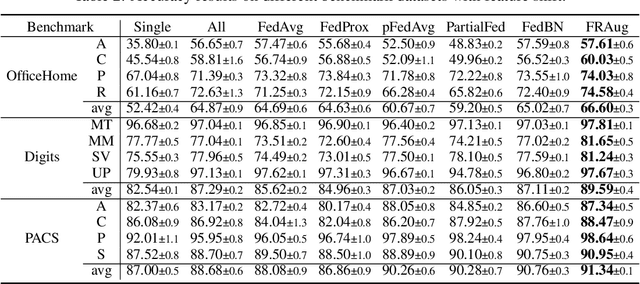
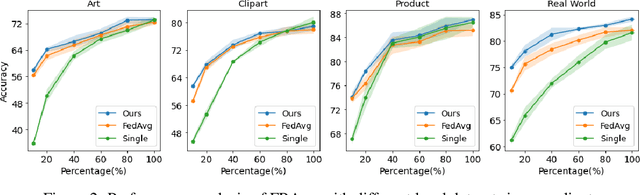
Federated Learning (FL) is a decentralized learning paradigm in which multiple clients collaboratively train deep learning models without centralizing their local data and hence preserve data privacy. Real-world applications usually involve a distribution shift across the datasets of the different clients, which hurts the generalization ability of the clients to unseen samples from their respective data distributions. In this work, we address the recently proposed feature shift problem where the clients have different feature distributions while the label distribution is the same. We propose Federated Representation Augmentation (FRAug) to tackle this practical and challenging problem. Our approach generates synthetic client-specific samples in the embedding space to augment the usually small client datasets. For that, we train a shared generative model to fuse the clients' knowledge, learned from different feature distributions, to synthesize client-agnostic embeddings, which are then locally transformed into client-specific embeddings by Representation Transformation Networks (RTNets). By transferring knowledge across the clients, the generated embeddings act as a regularizer for the client models and reduce overfitting to the local original datasets, hence improving generalization. Our empirical evaluation on multiple benchmark datasets demonstrates the effectiveness of the proposed method, which substantially outperforms the current state-of-the-art FL methods for non-IID features, including PartialFed and FedBN.
Towards Data-Free Domain Generalization
Oct 25, 2021

In this work, we investigate the unexplored intersection of domain generalization and data-free learning. In particular, we address the question: How can knowledge contained in models trained on different source data domains can be merged into a single model that generalizes well to unseen target domains, in the absence of source and target domain data? Machine learning models that can cope with domain shift are essential for for real-world scenarios with often changing data distributions. Prior domain generalization methods typically rely on using source domain data, making them unsuitable for private decentralized data. We define the novel problem of Data-Free Domain Generalization (DFDG), a practical setting where models trained on the source domains separately are available instead of the original datasets, and investigate how to effectively solve the domain generalization problem in that case. We propose DEKAN, an approach that extracts and fuses domain-specific knowledge from the available teacher models into a student model robust to domain shift. Our empirical evaluation demonstrates the effectiveness of our method which achieves first state-of-the-art results in DFDG by significantly outperforming ensemble and data-free knowledge distillation baselines.
COLUMBUS: Automated Discovery of New Multi-Level Features for Domain Generalization via Knowledge Corruption
Sep 09, 2021
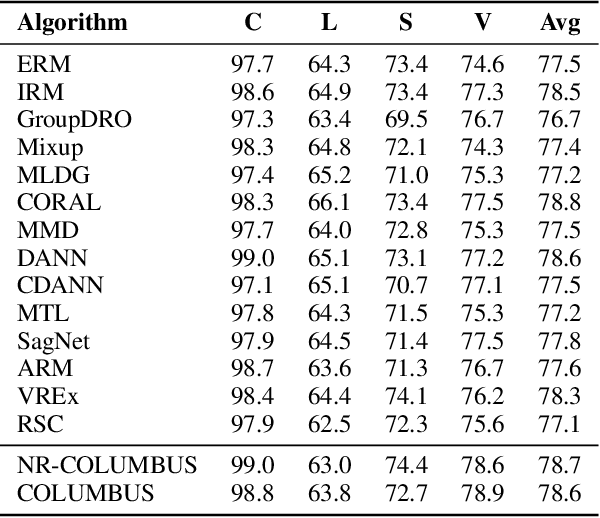
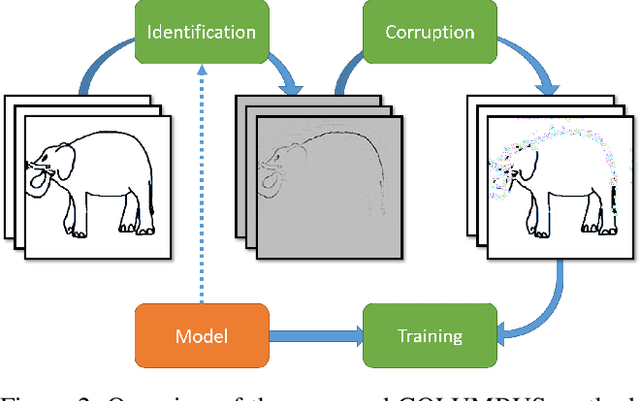

Machine learning models that can generalize to unseen domains are essential when applied in real-world scenarios involving strong domain shifts. We address the challenging domain generalization (DG) problem, where a model trained on a set of source domains is expected to generalize well in unseen domains without any exposure to their data. The main challenge of DG is that the features learned from the source domains are not necessarily present in the unseen target domains, leading to performance deterioration. We assume that learning a richer set of features is crucial to improve the transfer to a wider set of unknown domains. For this reason, we propose COLUMBUS, a method that enforces new feature discovery via a targeted corruption of the most relevant input and multi-level representations of the data. We conduct an extensive empirical evaluation to demonstrate the effectiveness of the proposed approach which achieves new state-of-the-art results by outperforming 18 DG algorithms on multiple DG benchmark datasets in the DomainBed framework.
ARCADe: A Rapid Continual Anomaly Detector
Aug 10, 2020



Although continual learning and anomaly detection have separately been well-studied in previous works, their intersection remains rather unexplored. The present work addresses a learning scenario where a model has to incrementally learn a sequence of anomaly detection tasks, i.e. tasks from which only examples from the normal (majority) class are available for training. We define this novel learning problem of continual anomaly detection (CAD) and formulate it as a meta-learning problem. Moreover, we propose A Rapid Continual Anomaly Detector (ARCADe), an approach to train neural networks to be robust against the major challenges of this new learning problem, namely catastrophic forgetting and overfitting to the majority class. The results of our experiments on three datasets show that, in the CAD problem setting, ARCADe substantially outperforms baselines from the continual learning and anomaly detection literature. Finally, we provide deeper insights into the learning strategy yielded by the proposed meta-learning algorithm.