 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-Free Domain Generalization
Oct 25, 2021

In this work, we investigate the unexplored intersection of domain generalization and data-free learning. In particular, we address the question: How can knowledge contained in models trained on different source data domains can be merged into a single model that generalizes well to unseen target domains, in the absence of source and target domain data? Machine learning models that can cope with domain shift are essential for for real-world scenarios with often changing data distributions. Prior domain generalization methods typically rely on using source domain data, making them unsuitable for private decentralized data. We define the novel problem of Data-Free Domain Generalization (DFDG), a practical setting where models trained on the source domains separately are available instead of the original datasets, and investigate how to effectively solve the domain generalization problem in that case. We propose DEKAN, an approach that extracts and fuses domain-specific knowledge from the available teacher models into a student model robust to domain shift. Our empirical evaluation demonstrates the effectiveness of our method which achieves first state-of-the-art results in DFDG by significantly outperforming ensemble and data-free knowledge distillation baselines.
COLUMBUS: Automated Discovery of New Multi-Level Features for Domain Generalization via Knowledge Corruption
Sep 09, 2021
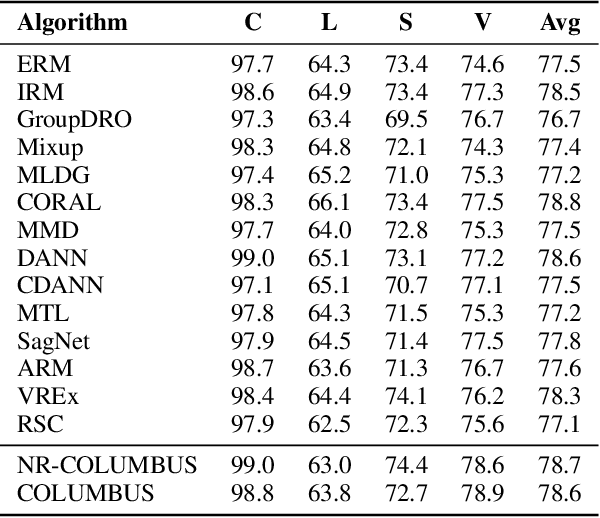
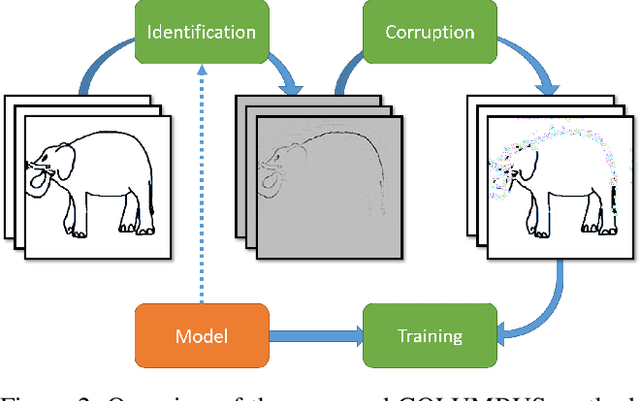

Machine learning models that can generalize to unseen domains are essential when applied in real-world scenarios involving strong domain shifts. We address the challenging domain generalization (DG) problem, where a model trained on a set of source domains is expected to generalize well in unseen domains without any exposure to their data. The main challenge of DG is that the features learned from the source domains are not necessarily present in the unseen target domains, leading to performance deterioration. We assume that learning a richer set of features is crucial to improve the transfer to a wider set of unknown domains. For this reason, we propose COLUMBUS, a method that enforces new feature discovery via a targeted corruption of the most relevant input and multi-level representations of the data. We conduct an extensive empirical evaluation to demonstrate the effectiveness of the proposed approach which achieves new state-of-the-art results by outperforming 18 DG algorithms on multiple DG benchmark datasets in the DomainBed framework.
ARCADe: A Rapid Continual Anomaly Detector
Aug 10, 2020



Although continual learning and anomaly detection have separately been well-studied in previous works, their intersection remains rather unexplored. The present work addresses a learning scenario where a model has to incrementally learn a sequence of anomaly detection tasks, i.e. tasks from which only examples from the normal (majority) class are available for training. We define this novel learning problem of continual anomaly detection (CAD) and formulate it as a meta-learning problem. Moreover, we propose A Rapid Continual Anomaly Detector (ARCADe), an approach to train neural networks to be robust against the major challenges of this new learning problem, namely catastrophic forgetting and overfitting to the majority class. The results of our experiments on three datasets show that, in the CAD problem setting, ARCADe substantially outperforms baselines from the continual learning and anomaly detection literature. Finally, we provide deeper insights into the learning strategy yielded by the proposed meta-learning algorithm.
Few-Shot One-Class Classification via Meta-Learning
Jul 08, 2020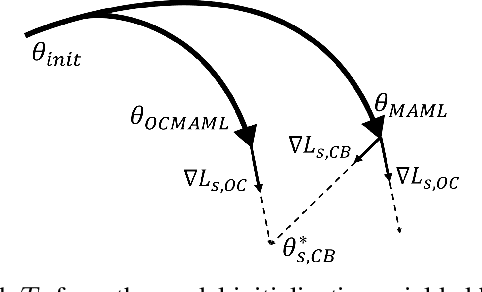

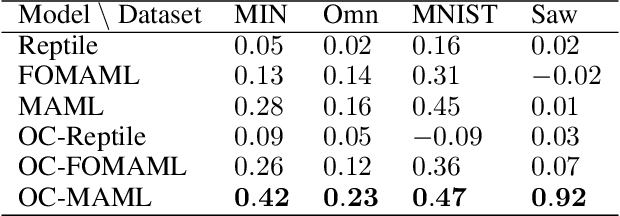

Although few-shot learning and one-class classification (OCC), i.e. learning a binary classifier with data from only one class, have been separately well studied, their intersection remains rather unexplored. Our work addresses the few-shot OCC problem and presents a method to modify the episodic data sampling strategy of the model-agnostic meta-learning (MAML) algorithm to learn a model initialization particularly suited for learning few-shot OCC tasks. This is done by explicitly optimizing for an initialization which only requires few gradient steps with one-class minibatches to yield a performance increase on class-balanced test data. We provide a theoretical analysis that explains why our approach works in the few-shot OCC scenario, while other meta-learning algorithms, including MAML, fail. Our experiments on eight datasets from the image and time-series domains show that our method leads to higher results than classical OCC and few-shot classification approaches, and demonstrate the ability to learn unseen tasks from only few normal class samples. Moreover, we successfully train anomaly detectors for a real-world application on sensor readings recorded during industrial manufacturing of workpieces with a CNC milling machine using few normal examples. Finally, we empirically demonstrate that the proposed data sampling technique increases the performance of more recent meta-learning algorithms in few-shot OCC.
Learning with Memory Embeddings
May 07, 2016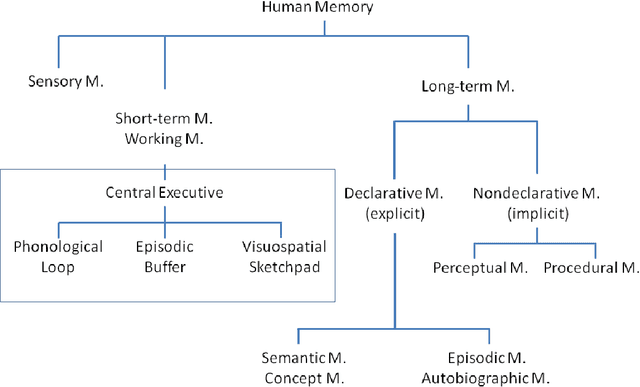

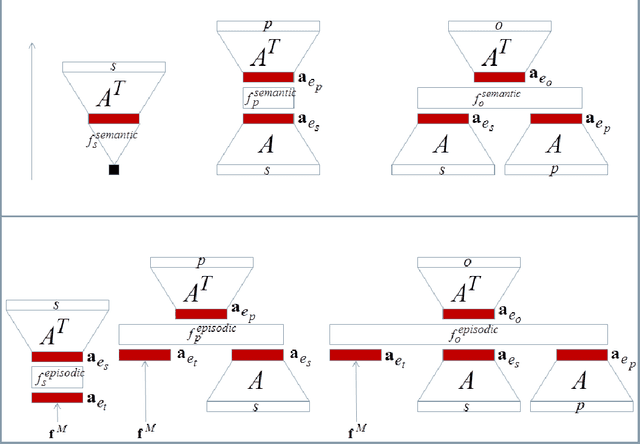
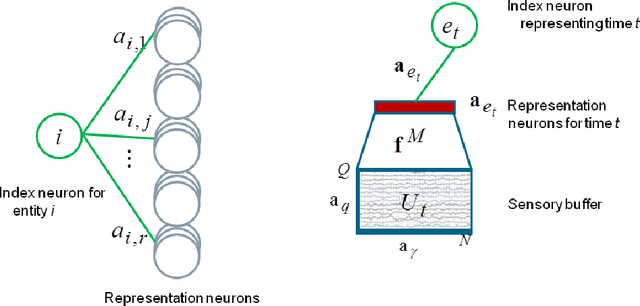
Embedding learning, a.k.a. representation learning, has been shown to be able to model large-scale semantic knowledge graphs. A key concept is a mapping of the knowledge graph to a tensor representation whose entries are predicted by models using latent representations of generalized entities. Latent variable models are well suited to deal with the high dimensionality and sparsity of typical knowledge graphs. In recent publications the embedding models were extended to also consider time evolutions, time patterns and subsymbolic representations. In this paper we map embedding models, which were developed purely as solutions to technical problems for modelling temporal knowledge graphs, to various cognitive memory functions, in particular to semantic and concept memory, episodic memory, sensory memory, short-term memory, and working memory. We discuss learning, query answering, the path from sensory input to semantic decoding, and the relationship between episodic memory and semantic memory. We introduce a number of hypotheses on human memory that can be derived from the developed mathematical models.
Predicting the Co-Evolution of Event and Knowledge Graphs
Dec 21, 2015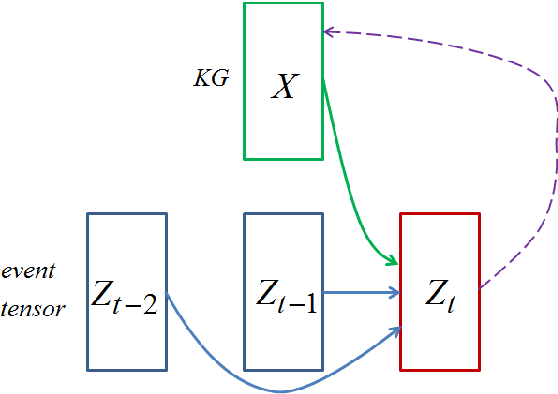



Embedding learning, a.k.a. representation learning, has been shown to be able to model large-scale semantic knowledge graphs. A key concept is a mapping of the knowledge graph to a tensor representation whose entries are predicted by models using latent representations of generalized entities. Knowledge graphs are typically treated as static: A knowledge graph grows more links when more facts become available but the ground truth values associated with links is considered time invariant. In this paper we address the issue of knowledge graphs where triple states depend on time. We assume that changes in the knowledge graph always arrive in form of events, in the sense that the events are the gateway to the knowledge graph. We train an event prediction model which uses both knowledge graph background information and information on recent events. By predicting future events, we also predict likely changes in the knowledge graph and thus obtain a model for the evolution of the knowledge graph as well. Our experiments demonstrate that our approach performs well in a clinical application, a recommendation engine and a sensor network application.
Type-Constrained Representation Learning in Knowledge Graphs
Aug 28, 2015


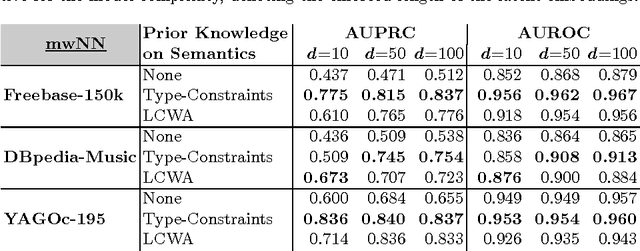
Large knowledge graphs increasingly add value to various applications that require machines to recognize and understand queries and their semantics, as in search or question answering systems. Latent variable models have increasingly gained attention for the statistical modeling of knowledge graphs, showing promising results in tasks related to knowledge graph completion and cleaning. Besides storing facts about the world, schema-based knowledge graphs are backed by rich semantic descriptions of entities and relation-types that allow machines to understand the notion of things and their semantic relationships. In this work, we study how type-constraints can generally support the statistical modeling with latent variable models. More precisely, we integrated prior knowledge in form of type-constraints in various state of the art latent variable approaches. Our experimental results show that prior knowledge on relation-types significantly improves these models up to 77% in link-prediction tasks. The achieved improvements are especially prominent when a low model complexity is enforced, a crucial requirement when these models are applied to very large datasets. Unfortunately, type-constraints are neither always available nor always complete e.g., they can become fuzzy when entities lack proper typing. We show that in these cases, it can be beneficial to apply a local closed-world assumption that approximates the semantics of relation-types based on observations made in the data.