 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Customer Feedback for Product Fit Prediction
Aug 28, 2019
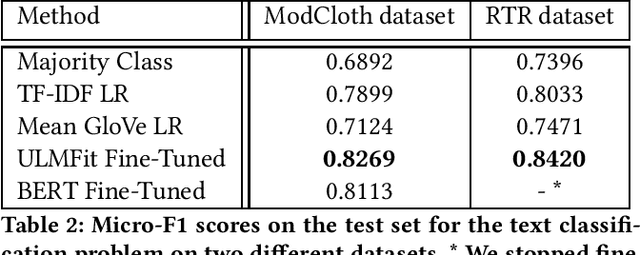

One of the biggest hurdles for customers when purchasing fashion online, is the difficulty of finding products with the right fit. In order to provide a better online shopping experience, platforms need to find ways to recommend the right product sizes and the best fitting products to their customers. These recommendation systems, however, require customer feedback in order to estimate the most suitable sizing options. Such feedback is rare and often only available as natural text. In this paper, we examine the extraction of product fit feedback from customer reviews using natural language processing techniques. In particular, we compare traditional methods with more recent transfer learning techniques for text classification, and analyze their results. Our evaluation shows, that the transfer learning approach ULMFit is not only comparatively fast to train, but also achieves highest accuracy on this task. The integration of the extracted information with actual size recommendation systems is left for future work.
Improving Visual Relationship Detection using Semantic Modeling of Scene Descriptions
Sep 01, 2018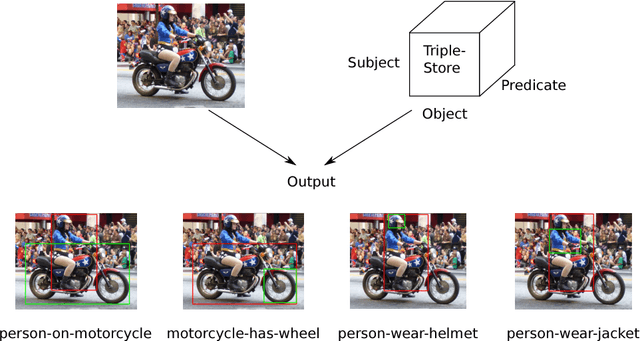

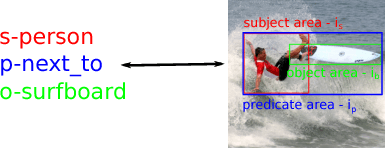

Structured scene descriptions of images are useful for the automatic processing and querying of large image databases. We show how the combination of a semantic and a visual statistical model can improve on the task of mapping images to their associated scene description. In this paper we consider scene descriptions which are represented as a set of triples (subject, predicate, object), where each triple consists of a pair of visual objects, which appear in the image, and the relationship between them (e.g. man-riding-elephant, man-wearing-hat). We combine a standard visual model for object detection, based on convolutional neural networks, with a latent variable model for link prediction. We apply multiple state-of-the-art link prediction methods and compare their capability for visual relationship detection. One of the main advantages of link prediction methods is that they can also generalize to triples, which have never been observed in the training data. Our experimental results on the recently published Stanford Visual Relationship dataset, a challenging real world dataset, show that the integration of a semantic model using link prediction methods can significantly improve the results for visual relationship detection. Our combined approach achieves superior performance compared to the state-of-the-art method from the Stanford computer vision group.
Improving Information Extraction from Images with Learned Semantic Models
Aug 27, 2018
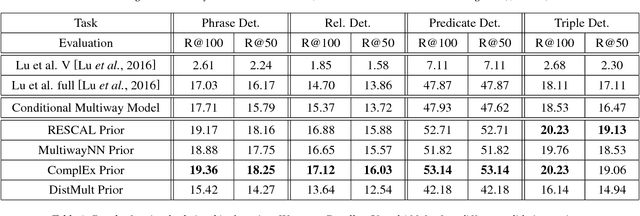

Many applications require an understanding of an image that goes beyond the simple detection and classification of its objects. In particular, a great deal of semantic information is carried in the relationships between objects. We have previously shown that the combination of a visual model and a statistical semantic prior model can improve on the task of mapping images to their associated scene description. In this paper, we review the model and compare it to a novel conditional multi-way model for visual relationship detection, which does not include an explicitly trained visual prior model. We also discuss potential relationships between the proposed methods and memory models of the human brain.
Tensor Decompositions for Modeling Inverse Dynamics
Nov 13, 2017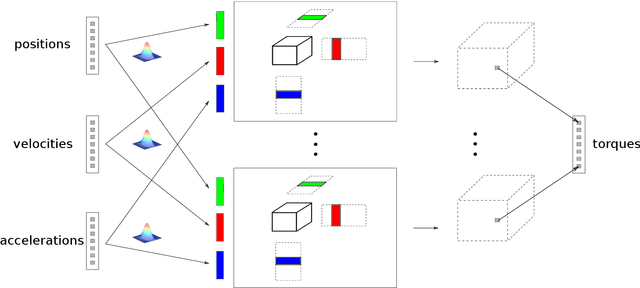

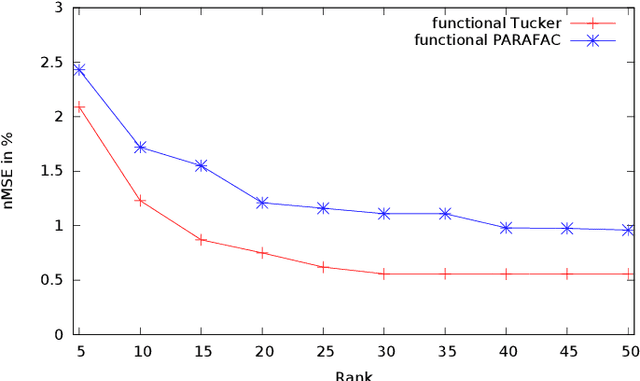
Modeling inverse dynamics is crucial for accurate feedforward robot control. The model computes the necessary joint torques, to perform a desired movement. The highly non-linear inverse function of the dynamical system can be approximated using regression techniques. We propose as regression method a tensor decomposition model that exploits the inherent three-way interaction of positions x velocities x accelerations. Most work in tensor factorization has addressed the decomposition of dense tensors. In this paper, we build upon the decomposition of sparse tensors, with only small amounts of nonzero entries. The decomposition of sparse tensors has successfully been used in relational learning, e.g., the modeling of large knowledge graphs. Recently, the approach has been extended to multi-class classification with discrete input variables. Representing the data in high dimensional sparse tensors enables the approximation of complex highly non-linear functions. In this paper we show how the decomposition of sparse tensors can be applied to regression problems. Furthermore, we extend the method to continuous inputs, by learning a mapping from the continuous inputs to the latent representations of the tensor decomposition, using basis functions. We evaluate our proposed model on a dataset with trajectories from a seven degrees of freedom SARCOS robot arm. Our experimental results show superior performance of the proposed functional tensor model, compared to challenging state-of-the art methods.
Attention-based Information Fusion using Multi-Encoder-Decoder Recurrent Neural Networks
Nov 13, 2017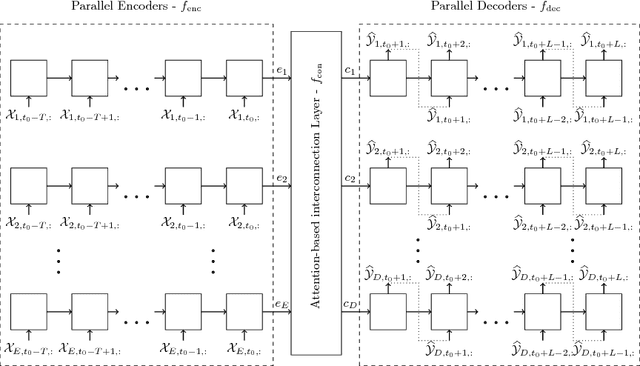
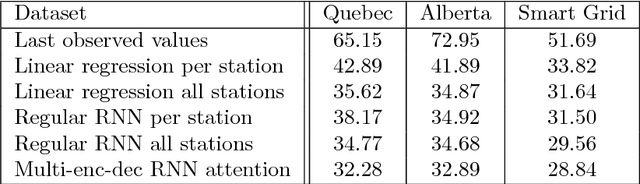
With the rising number of interconnected devices and sensors, modeling distributed sensor networks is of increasing interest. Recurrent neural networks (RNN) are considered particularly well suited for modeling sensory and streaming data. When predicting future behavior, incorporating information from neighboring sensor stations is often beneficial. We propose a new RNN based architecture for context specific information fusion across multiple spatially distributed sensor stations. Hereby, latent representations of multiple local models, each modeling one sensor station, are jointed and weighted, according to their importance for the prediction. The particular importance is assessed depending on the current context using a separate attention function. We demonstrate the effectiveness of our model on three different real-world sensor network datasets.
Learning with Memory Embeddings
May 07, 2016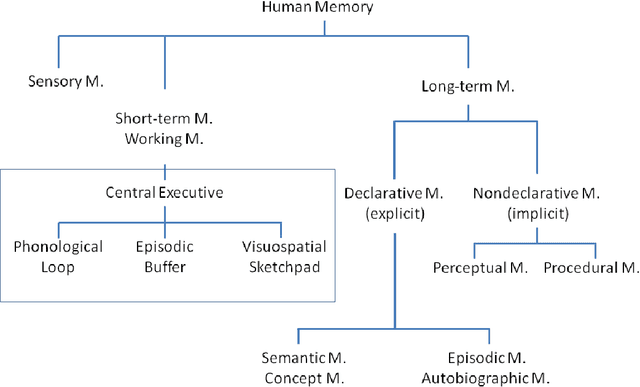

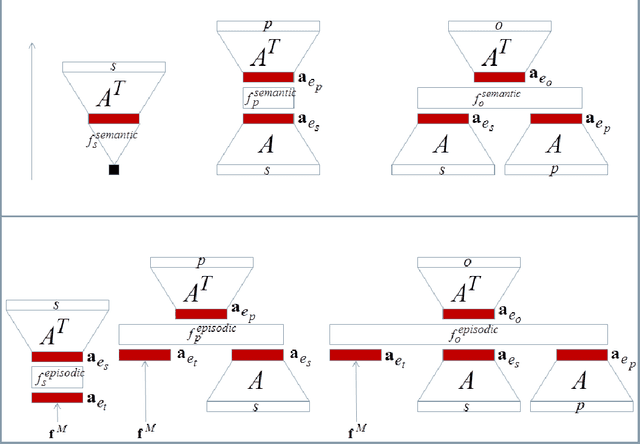
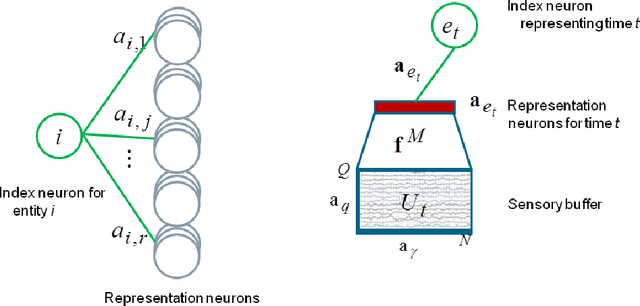
Embedding learning, a.k.a. representation learning, has been shown to be able to model large-scale semantic knowledge graphs. A key concept is a mapping of the knowledge graph to a tensor representation whose entries are predicted by models using latent representations of generalized entities. Latent variable models are well suited to deal with the high dimensionality and sparsity of typical knowledge graphs. In recent publications the embedding models were extended to also consider time evolutions, time patterns and subsymbolic representations. In this paper we map embedding models, which were developed purely as solutions to technical problems for modelling temporal knowledge graphs, to various cognitive memory functions, in particular to semantic and concept memory, episodic memory, sensory memory, short-term memory, and working memory. We discuss learning, query answering, the path from sensory input to semantic decoding, and the relationship between episodic memory and semantic memory. We introduce a number of hypotheses on human memory that can be derived from the developed mathematical models.
Predicting the Co-Evolution of Event and Knowledge Graphs
Dec 21, 2015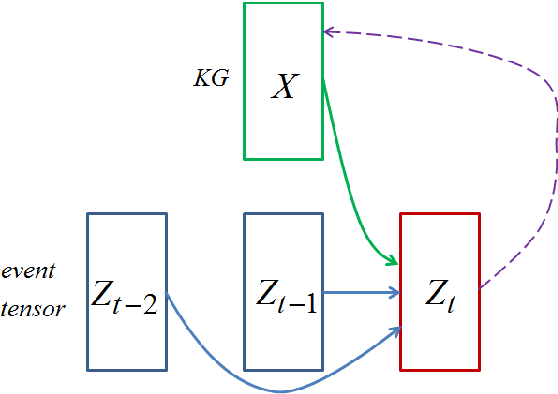



Embedding learning, a.k.a. representation learning, has been shown to be able to model large-scale semantic knowledge graphs. A key concept is a mapping of the knowledge graph to a tensor representation whose entries are predicted by models using latent representations of generalized entities. Knowledge graphs are typically treated as static: A knowledge graph grows more links when more facts become available but the ground truth values associated with links is considered time invariant. In this paper we address the issue of knowledge graphs where triple states depend on time. We assume that changes in the knowledge graph always arrive in form of events, in the sense that the events are the gateway to the knowledge graph. We train an event prediction model which uses both knowledge graph background information and information on recent events. By predicting future events, we also predict likely changes in the knowledge graph and thus obtain a model for the evolution of the knowledge graph as well. Our experiments demonstrate that our approach performs well in a clinical application, a recommendation engine and a sensor network application.
Type-Constrained Representation Learning in Knowledge Graphs
Aug 28, 2015


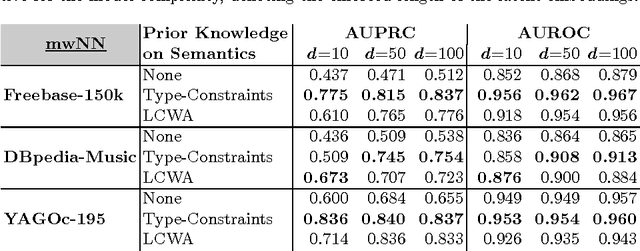
Large knowledge graphs increasingly add value to various applications that require machines to recognize and understand queries and their semantics, as in search or question answering systems. Latent variable models have increasingly gained attention for the statistical modeling of knowledge graphs, showing promising results in tasks related to knowledge graph completion and cleaning. Besides storing facts about the world, schema-based knowledge graphs are backed by rich semantic descriptions of entities and relation-types that allow machines to understand the notion of things and their semantic relationships. In this work, we study how type-constraints can generally support the statistical modeling with latent variable models. More precisely, we integrated prior knowledge in form of type-constraints in various state of the art latent variable approaches. Our experimental results show that prior knowledge on relation-types significantly improves these models up to 77% in link-prediction tasks. The achieved improvements are especially prominent when a low model complexity is enforced, a crucial requirement when these models are applied to very large datasets. Unfortunately, type-constraints are neither always available nor always complete e.g., they can become fuzzy when entities lack proper typing. We show that in these cases, it can be beneficial to apply a local closed-world assumption that approximates the semantics of relation-types based on observations made in the data.