 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph is a Substrate Across Data Modalities
Jan 29, 2026Graphs provide a natural representation of relational structure that arises across diverse domains. Despite this ubiquity, graph structure is typically learned in a modality- and task-isolated manner, where graph representations are constructed within individual task contexts and discarded thereafter. As a result, structural regularities across modalities and tasks are repeatedly reconstructed rather than accumulated at the level of intermediate graph representations. This motivates a representation-learning question: how should graph structure be organized so that it can persist and accumulate across heterogeneous modalities and tasks? We adopt a representation-centric perspective in which graph structure is treated as a structural substrate that persists across learning contexts. To instantiate this perspective, we propose G-Substrate, a graph substrate framework that organizes learning around shared graph structures. G-Substrate comprises two complementary mechanisms: a unified structural schema that ensures compatibility among graph representations across heterogeneous modalities and tasks, and an interleaved role-based training strategy that exposes the same graph structure to multiple functional roles during learning. Experiments across multiple domains, modalities, and tasks show that G-Substrate outperforms task-isolated and naive multi-task learning methods.
AUVIC: Adversarial Unlearning of Visual Concepts for Multi-modal Large Language Models
Nov 14, 2025Multimodal Large Language Models (MLLMs) achieve impressive performance once optimized on massive datasets. Such datasets often contain sensitive or copyrighted content, raising significant data privacy concerns. Regulatory frameworks mandating the 'right to be forgotten' drive the need for machine unlearning. This technique allows for the removal of target data without resource-consuming retraining. However, while well-studied for text, visual concept unlearning in MLLMs remains underexplored. A primary challenge is precisely removing a target visual concept without disrupting model performance on related entities. To address this, we introduce AUVIC, a novel visual concept unlearning framework for MLLMs. AUVIC applies adversarial perturbations to enable precise forgetting. This approach effectively isolates the target concept while avoiding unintended effects on similar entities. To evaluate our method, we construct VCUBench. It is the first benchmark designed to assess visual concept unlearning in group contexts. Experimental results demonstrate that AUVIC achieves state-of-the-art target forgetting rates while incurs minimal performance degradation on non-target concepts.
KORE: Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Augmentations and Constraints
Oct 22, 2025Large Multimodal Models encode extensive factual knowledge in their pre-trained weights. However, its knowledge remains static and limited, unable to keep pace with real-world developments, which hinders continuous knowledge acquisition. Effective knowledge injection thus becomes critical, involving two goals: knowledge adaptation (injecting new knowledge) and knowledge retention (preserving old knowledge). Existing methods often struggle to learn new knowledge and suffer from catastrophic forgetting. To address this, we propose KORE, a synergistic method of KnOwledge-oRientEd augmentations and constraints for injecting new knowledge into large multimodal models while preserving old knowledge. Unlike general text or image data augmentation, KORE automatically converts individual knowledge items into structured and comprehensive knowledge to ensure that the model accurately learns new knowledge, enabling accurate adaptation. Meanwhile, KORE stores previous knowledge in the covariance matrix of LMM's linear layer activations and initializes the adapter by projecting the original weights into the matrix's null space, defining a fine-tuning direction that minimizes interference with previous knowledge, enabling powerful retention. Extensive experiments on various LMMs, including LLaVA-v1.5-7B, LLaVA-v1.5-13B, and Qwen2.5-VL-7B, show that KORE achieves superior new knowledge injection performance and effectively mitigates catastrophic forgetting.
MV-Debate: Multi-view Agent Debate with Dynamic Reflection Gating for Multimodal Harmful Content Detection in Social Media
Aug 07, 2025Social media has evolved into a complex multimodal environment where text, images, and other signals interact to shape nuanced meanings, often concealing harmful intent. Identifying such intent, whether sarcasm, hate speech, or misinformation, remains challenging due to cross-modal contradictions, rapid cultural shifts, and subtle pragmatic cues. To address these challenges, we propose MV-Debate, a multi-view agent debate framework with dynamic reflection gating for unified multimodal harmful content detection. MV-Debate assembles four complementary debate agents, a surface analyst, a deep reasoner, a modality contrast, and a social contextualist, to analyze content from diverse interpretive perspectives. Through iterative debate and reflection, the agents refine responses under a reflection-gain criterion, ensuring both accuracy and efficiency. Experiments on three benchmark datasets demonstrate that MV-Debate significantly outperforms strong single-model and existing multi-agent debate baselines. This work highlights the promise of multi-agent debate in advancing reliable social intent detection in safety-critical online contexts.
ASCD: Attention-Steerable Contrastive Decoding for Reducing Hallucination in MLLM
Jun 17, 2025Multimodal Large Language Model (MLLM) often suffer from hallucinations. They over-rely on partial cues and generate incorrect responses. Recently, methods like Visual Contrastive Decoding (VCD) and Instruction Contrastive Decoding (ICD) have been proposed to mitigate hallucinations by contrasting predictions from perturbed or negatively prefixed inputs against original outputs. In this work, we uncover that methods like VCD and ICD fundamentally influence internal attention dynamics of the model. This observation suggests that their effectiveness may not stem merely from surface-level modifications to logits but from deeper shifts in attention distribution. Inspired by this insight, we propose an attention-steerable contrastive decoding framework that directly intervenes in attention mechanisms of the model to offer a more principled approach to mitigating hallucinations. Our experiments across multiple MLLM architectures and diverse decoding methods demonstrate that our approach significantly reduces hallucinations and improves the performance on benchmarks such as POPE, CHAIR, and MMHal-Bench, while simultaneously enhancing performance on standard VQA benchmarks.
Does Machine Unlearning Truly Remove Model Knowledge? A Framework for Auditing Unlearning in LLMs
May 29, 2025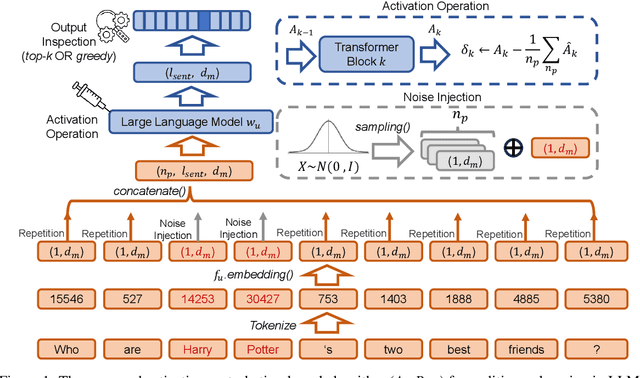
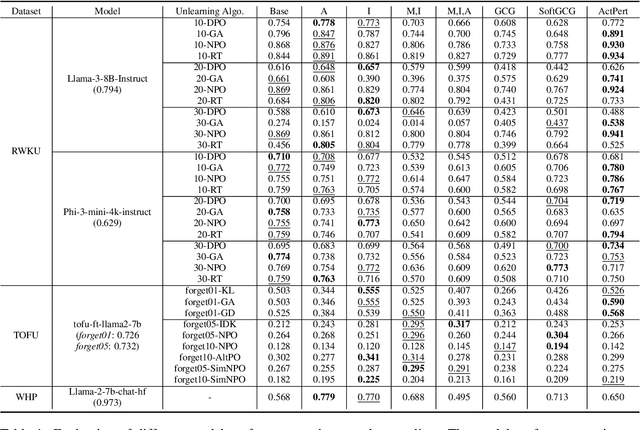
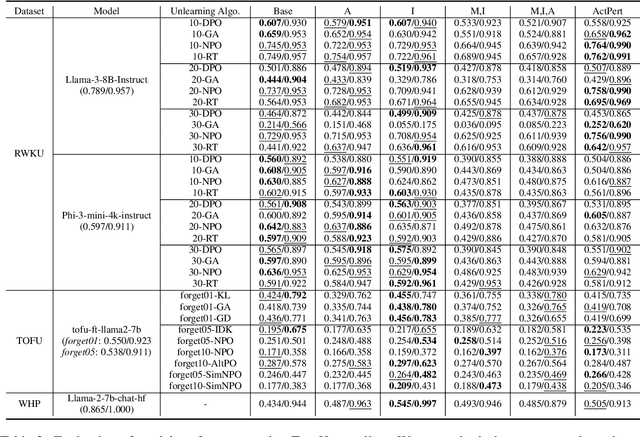
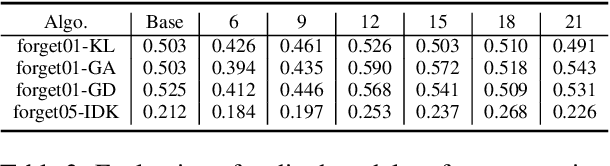
In recent years, Large Language Models (LLMs) have achieved remarkable advancements, drawing significant attention from the research community. Their capabilities are largely attributed to large-scale architectures, which require extensive training on massive datasets. However, such datasets often contain sensitive or copyrighted content sourced from the public internet, raising concerns about data privacy and ownership. Regulatory frameworks, such as the General Data Protection Regulation (GDPR), grant individuals the right to request the removal of such sensitive information. This has motivated the development of machine unlearning algorithms that aim to remove specific knowledge from models without the need for costly retraining. Despite these advancements, evaluating the efficacy of unlearning algorithms remains a challenge due to the inherent complexity and generative nature of LLMs. In this work, we introduce a comprehensive auditing framework for unlearning evaluation, comprising three benchmark datasets, six unlearning algorithms, and five prompt-based auditing methods. By using various auditing algorithms, we evaluate the effectiveness and robustness of different unlearning strategies. To explore alternatives beyond prompt-based auditing, we propose a novel technique that leverages intermediate activation perturbations, addressing the limitations of auditing methods that rely solely on model inputs and outputs.
Backdoor Cleaning without External Guidance in MLLM Fine-tuning
May 22, 2025Multimodal Large Language Models (MLLMs) are increasingly deployed in fine-tuning-as-a-service (FTaaS) settings, where user-submitted datasets adapt general-purpose models to downstream tasks. This flexibility, however, introduces serious security risks, as malicious fine-tuning can implant backdoors into MLLMs with minimal effort. In this paper, we observe that backdoor triggers systematically disrupt cross-modal processing by causing abnormal attention concentration on non-semantic regions--a phenomenon we term attention collapse. Based on this insight, we propose Believe Your Eyes (BYE), a data filtering framework that leverages attention entropy patterns as self-supervised signals to identify and filter backdoor samples. BYE operates via a three-stage pipeline: (1) extracting attention maps using the fine-tuned model, (2) computing entropy scores and profiling sensitive layers via bimodal separation, and (3) performing unsupervised clustering to remove suspicious samples. Unlike prior defenses, BYE equires no clean supervision, auxiliary labels, or model modifications. Extensive experiments across various datasets, models, and diverse trigger types validate BYE's effectiveness: it achieves near-zero attack success rates while maintaining clean-task performance, offering a robust and generalizable solution against backdoor threats in MLLMs.
CoT-Kinetics: A Theoretical Modeling Assessing LRM Reasoning Process
May 19, 2025Recent Large Reasoning Models significantly improve the reasoning ability of Large Language Models by learning to reason, exhibiting the promising performance in solving complex tasks. LRMs solve tasks that require complex reasoning by explicitly generating reasoning trajectories together with answers. Nevertheless, judging the quality of such an output answer is not easy because only considering the correctness of the answer is not enough and the soundness of the reasoning trajectory part matters as well. Logically, if the soundness of the reasoning part is poor, even if the answer is correct, the confidence of the derived answer should be low. Existing methods did consider jointly assessing the overall output answer by taking into account the reasoning part, however, their capability is still not satisfactory as the causal relationship of the reasoning to the concluded answer cannot properly reflected. In this paper, inspired by classical mechanics, we present a novel approach towards establishing a CoT-Kinetics energy equation. Specifically, our CoT-Kinetics energy equation formulates the token state transformation process, which is regulated by LRM internal transformer layers, as like a particle kinetics dynamics governed in a mechanical field. Our CoT-Kinetics energy assigns a scalar score to evaluate specifically the soundness of the reasoning phase, telling how confident the derived answer could be given the evaluated reasoning. As such, the LRM's overall output quality can be accurately measured, rather than a coarse judgment (e.g., correct or incorrect) anymore.
PRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection
Feb 17, 2025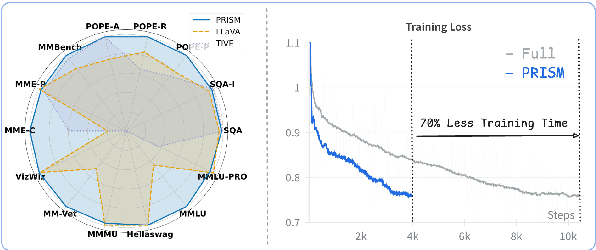
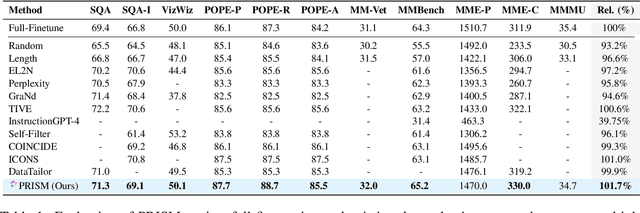
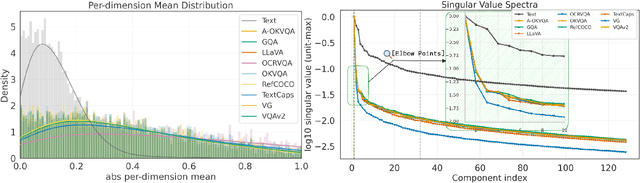
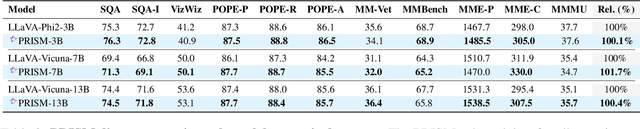
Visual instruction tuning refines pre-trained Multimodal Large Language Models (MLLMs) to enhance their real-world task performance. However, the rapid expansion of visual instruction datasets introduces significant data redundancy, leading to excessive computational costs. Existing data selection methods predominantly rely on proxy models or loss-based metrics, both of which impose substantial computational overheads due to the necessity of model inference and backpropagation. To address this challenge, we propose PRISM, a novel training-free approach for efficient multimodal data selection. Unlike existing methods, PRISM eliminates the reliance on proxy models, warm-up pretraining, and gradient-based optimization. Instead, it leverages Pearson correlation analysis to quantify the intrinsic visual encoding properties of MLLMs, computing a task-specific correlation score to identify high-value instances. This not only enbles data-efficient selection,but maintains the original performance. Empirical evaluations across multiple MLLMs demonstrate that PRISM reduces the overall time required for visual instruction tuning and data selection to just 30% of conventional methods, while surpassing fully fine-tuned models across eight multimodal and three language understanding benchmarks, achieving a 101.7% relative improvement in final performance.
Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering
Dec 16, 2024



Multimodal Large Language Models (MLLMs) have significantly advanced visual tasks by integrating visual representations into large language models (LLMs). The textual modality, inherited from LLMs, equips MLLMs with abilities like instruction following and in-context learning. In contrast, the visual modality enhances performance in downstream tasks by leveraging rich semantic content, spatial information, and grounding capabilities. These intrinsic modalities work synergistically across various visual tasks. Our research initially reveals a persistent imbalance between these modalities, with text often dominating output generation during visual instruction tuning. This imbalance occurs when using both full fine-tuning and parameter-efficient fine-tuning (PEFT) methods. We then found that re-balancing these modalities can significantly reduce the number of trainable parameters required, inspiring a direction for further optimizing visual instruction tuning. We introduce Modality Linear Representation-Steering (MoReS) to achieve the goal. MoReS effectively re-balances the intrinsic modalities throughout the model, where the key idea is to steer visual representations through linear transformations in the visual subspace across each model layer. To validate our solution, we composed LLaVA Steering, a suite of models integrated with the proposed MoReS method. Evaluation results show that the composed LLaVA Steering models require, on average, 500 times fewer trainable parameters than LoRA needs while still achieving comparable performance across three visual benchmarks and eight visual question-answering tasks. Last, we present the LLaVA Steering Factory, an in-house developed platform that enables researchers to quickly customize various MLLMs with component-based architecture for seamlessly integrating state-of-the-art models, and evaluate their intrinsic modality imbalance.