 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Personas? Role-Playing, Instruction Following, and Safety in Extended Interactions
Dec 14, 2025



Persona-assigned large language models (LLMs) are used in domains such as education, healthcare, and sociodemographic simulation. Yet, they are typically evaluated only in short, single-round settings that do not reflect real-world usage. We introduce an evaluation protocol that combines long persona dialogues (over 100 rounds) and evaluation datasets to create dialogue-conditioned benchmarks that can robustly measure long-context effects. We then investigate the effects of dialogue length on persona fidelity, instruction-following, and safety of seven state-of-the-art open- and closed-weight LLMs. We find that persona fidelity degrades over the course of dialogues, especially in goal-oriented conversations, where models must sustain both persona fidelity and instruction following. We identify a trade-off between fidelity and instruction following, with non-persona baselines initially outperforming persona-assigned models; as dialogues progress and fidelity fades, persona responses become increasingly similar to baseline responses. Our findings highlight the fragility of persona applications in extended interactions and our work provides a protocol to systematically measure such failures.
CoT-Kinetics: A Theoretical Modeling Assessing LRM Reasoning Process
May 19, 2025Recent Large Reasoning Models significantly improve the reasoning ability of Large Language Models by learning to reason, exhibiting the promising performance in solving complex tasks. LRMs solve tasks that require complex reasoning by explicitly generating reasoning trajectories together with answers. Nevertheless, judging the quality of such an output answer is not easy because only considering the correctness of the answer is not enough and the soundness of the reasoning trajectory part matters as well. Logically, if the soundness of the reasoning part is poor, even if the answer is correct, the confidence of the derived answer should be low. Existing methods did consider jointly assessing the overall output answer by taking into account the reasoning part, however, their capability is still not satisfactory as the causal relationship of the reasoning to the concluded answer cannot properly reflected. In this paper, inspired by classical mechanics, we present a novel approach towards establishing a CoT-Kinetics energy equation. Specifically, our CoT-Kinetics energy equation formulates the token state transformation process, which is regulated by LRM internal transformer layers, as like a particle kinetics dynamics governed in a mechanical field. Our CoT-Kinetics energy assigns a scalar score to evaluate specifically the soundness of the reasoning phase, telling how confident the derived answer could be given the evaluated reasoning. As such, the LRM's overall output quality can be accurately measured, rather than a coarse judgment (e.g., correct or incorrect) anymore.
Collapse of Dense Retrievers: Short, Early, and Literal Biases Outranking Factual Evidence
Mar 06, 2025Dense retrieval models are commonly used in Information Retrieval (IR) applications, such as Retrieval-Augmented Generation (RAG). Since they often serve as the first step in these systems, their robustness is critical to avoid failures. In this work, by repurposing a relation extraction dataset (e.g. Re-DocRED), we design controlled experiments to quantify the impact of heuristic biases, such as favoring shorter documents, in retrievers like Dragon+ and Contriever. Our findings reveal significant vulnerabilities: retrievers often rely on superficial patterns like over-prioritizing document beginnings, shorter documents, repeated entities, and literal matches. Additionally, they tend to overlook whether the document contains the query's answer, lacking deep semantic understanding. Notably, when multiple biases combine, models exhibit catastrophic performance degradation, selecting the answer-containing document in less than 3% of cases over a biased document without the answer. Furthermore, we show that these biases have direct consequences for downstream applications like RAG, where retrieval-preferred documents can mislead LLMs, resulting in a 34% performance drop than not providing any documents at all.
Problem Solving Through Human-AI Preference-Based Cooperation
Aug 15, 2024


While there is a widespread belief that artificial general intelligence (AGI) -- or even superhuman AI -- is imminent, complex problems in expert domains are far from being solved. We argue that such problems require human-AI cooperation and that the current state of the art in generative AI is unable to play the role of a reliable partner due to a multitude of shortcomings, including inability to keep track of a complex solution artifact (e.g., a software program), limited support for versatile human preference expression and lack of adapting to human preference in an interactive setting. To address these challenges, we propose HAI-Co2, a novel human-AI co-construction framework. We formalize HAI-Co2 and discuss the difficult open research problems that it faces. Finally, we present a case study of HAI-Co2 and demonstrate its efficacy compared to monolithic generative AI models.
Listening to Affected Communities to Define Extreme Speech: Dataset and Experiments
Mar 22, 2022
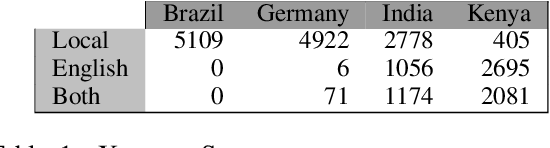

Building on current work on multilingual hate speech (e.g., Ousidhoum et al. (2019)) and hate speech reduction (e.g., Sap et al. (2020)), we present XTREMESPEECH, a new hate speech dataset containing 20,297 social media passages from Brazil, Germany, India and Kenya. The key novelty is that we directly involve the affected communities in collecting and annotating the data - as opposed to giving companies and governments control over defining and combatting hate speech. This inclusive approach results in datasets more representative of actually occurring online speech and is likely to facilitate the removal of the social media content that marginalized communities view as causing the most harm. Based on XTREMESPEECH, we establish novel tasks with accompanying baselines, provide evidence that cross-country training is generally not feasible due to cultural differences between countries and perform an interpretability analysis of BERT's predictions.
Differentiable Multi-Agent Actor-Critic for Multi-Step Radiology Report Summarization
Mar 15, 2022
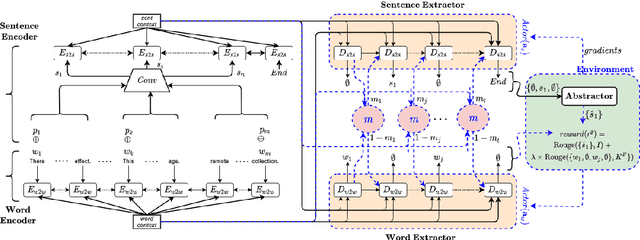


The IMPRESSIONS section of a radiology report about an imaging study is a summary of the radiologist's reasoning and conclusions, and it also aids the referring physician in confirming or excluding certain diagnoses. A cascade of tasks are required to automatically generate an abstractive summary of the typical information-rich radiology report. These tasks include acquisition of salient content from the report and generation of a concise, easily consumable IMPRESSIONS section. Prior research on radiology report summarization has focused on single-step end-to-end models -- which subsume the task of salient content acquisition. To fully explore the cascade structure and explainability of radiology report summarization, we introduce two innovations. First, we design a two-step approach: extractive summarization followed by abstractive summarization. Second, we additionally break down the extractive part into two independent tasks: extraction of salient (1) sentences and (2) keywords. Experiments on a publicly available radiology report dataset show our novel approach leads to a more precise summary compared to single-step and to two-step-with-single-extractive-process baselines with an overall improvement in F1 score Of 3-4%.
* Accepted at 60th Annual Meeting of the Association for Computational Linguistics 2022 Main Conference
Few-Shot Learning of an Interleaved Text Summarization Model by Pretraining with Synthetic Data
Mar 08, 2021
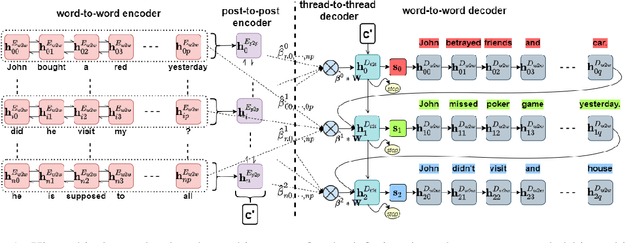

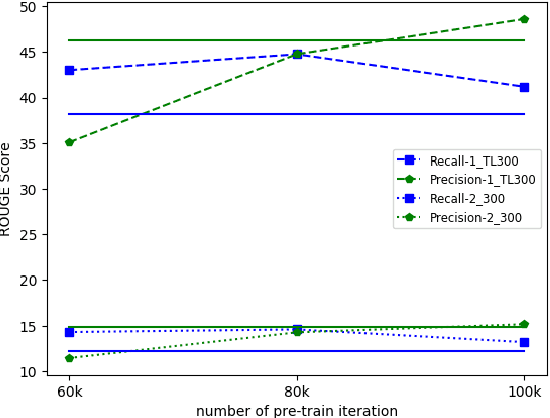
Interleaved texts, where posts belonging to different threads occur in a sequence, commonly occur in online chat posts, so that it can be time-consuming to quickly obtain an overview of the discussions. Existing systems first disentangle the posts by threads and then extract summaries from those threads. A major issue with such systems is error propagation from the disentanglement component. While end-to-end trainable summarization system could obviate explicit disentanglement, such systems require a large amount of labeled data. To address this, we propose to pretrain an end-to-end trainable hierarchical encoder-decoder system using synthetic interleaved texts. We show that by fine-tuning on a real-world meeting dataset (AMI), such a system out-performs a traditional two-step system by 22%. We also compare against transformer models and observed that pretraining with synthetic data both the encoder and decoder outperforms the BertSumExtAbs transformer model which pretrains only the encoder on a large dataset.
Nonsymbolic Text Representation
May 01, 2017
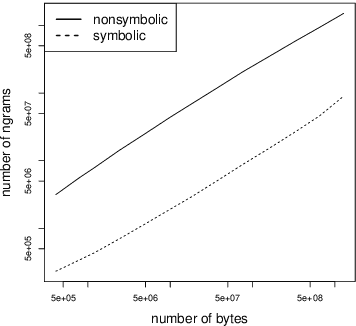

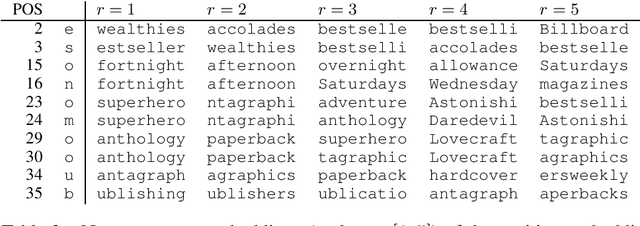
We introduce the first generic text representation model that is completely nonsymbolic, i.e., it does not require the availability of a segmentation or tokenization method that attempts to identify words or other symbolic units in text. This applies to training the parameters of the model on a training corpus as well as to applying it when computing the representation of a new text. We show that our model performs better than prior work on an information extraction and a text denoising task.
Two SVDs produce more focal deep learning representations
May 11, 2013


A key characteristic of work on deep learning and neural networks in general is that it relies on representations of the input that support generalization, robust inference, domain adaptation and other desirable functionalities. Much recent progress in the field has focused on efficient and effective methods for computing representations. In this paper, we propose an alternative method that is more efficient than prior work and produces representations that have a property we call focality -- a property we hypothesize to be important for neural network representations. The method consists of a simple application of two consecutive SVDs and is inspired by Anandkumar (2012).
Cutting Recursive Autoencoder Trees
Apr 26, 2013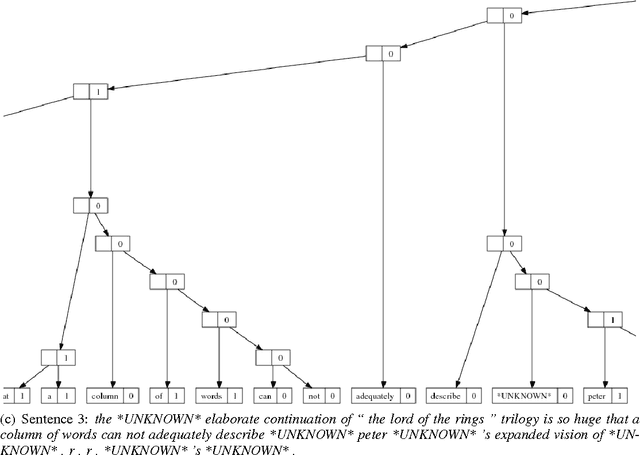
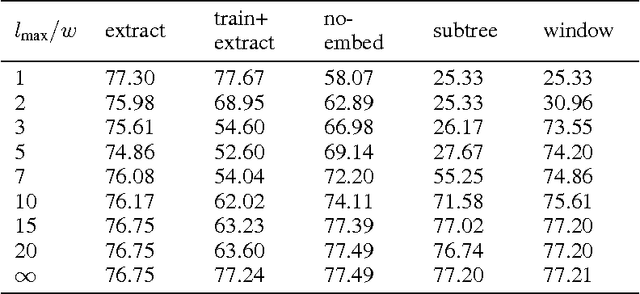
Deep Learning models enjoy considerable success in Natural Language Processing. While deep architectures produce useful representations that lead to improvements in various tasks, they are often difficult to interpret. This makes the analysis of learned structures particularly difficult. In this paper, we rely on empirical tests to see whether a particular structure makes sense. We present an analysis of the Semi-Supervised Recursive Autoencoder, a well-known model that produces structural representations of text. We show that for certain tasks, the structure of the autoencoder can be significantly reduced without loss of classification accuracy and we evaluate the produced structures using human judgment.