Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutting Recursive Autoencoder Trees
Paper and Code
Apr 26, 2013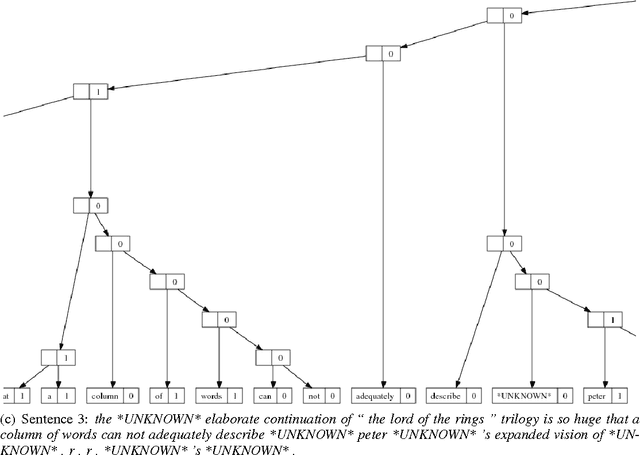
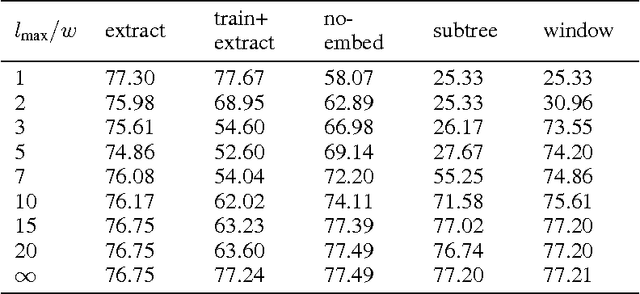
Deep Learning models enjoy considerable success in Natural Language Processing. While deep architectures produce useful representations that lead to improvements in various tasks, they are often difficult to interpret. This makes the analysis of learned structures particularly difficult. In this paper, we rely on empirical tests to see whether a particular structure makes sense. We present an analysis of the Semi-Supervised Recursive Autoencoder, a well-known model that produces structural representations of text. We show that for certain tasks, the structure of the autoencoder can be significantly reduced without loss of classification accuracy and we evaluate the produced structures using human judgment.
View paper on