 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening to Affected Communities to Define Extreme Speech: Dataset and Experiments
Mar 22, 2022
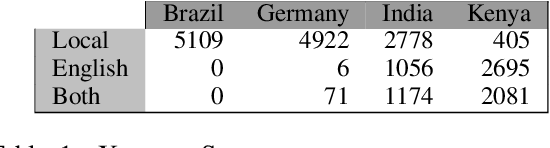

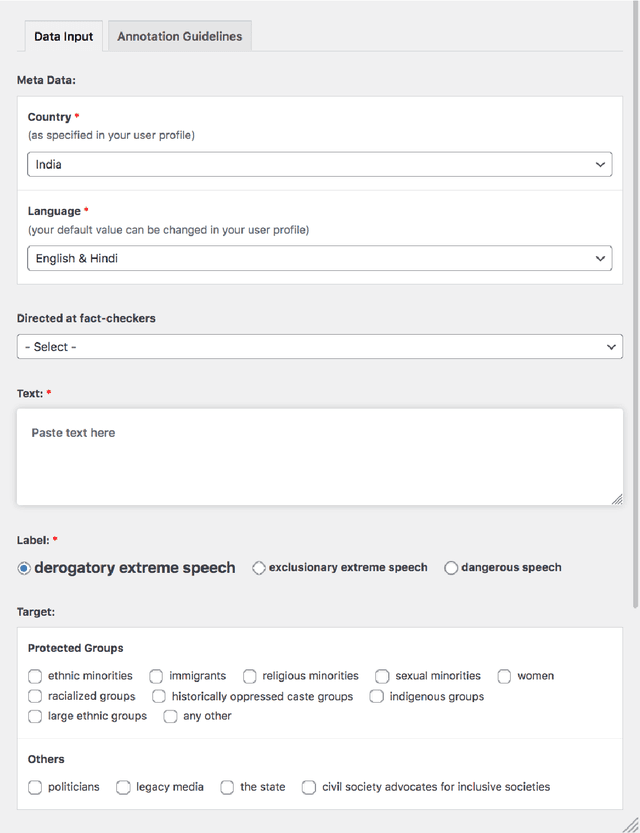
Building on current work on multilingual hate speech (e.g., Ousidhoum et al. (2019)) and hate speech reduction (e.g., Sap et al. (2020)), we present XTREMESPEECH, a new hate speech dataset containing 20,297 social media passages from Brazil, Germany, India and Kenya. The key novelty is that we directly involve the affected communities in collecting and annotating the data - as opposed to giving companies and governments control over defining and combatting hate speech. This inclusive approach results in datasets more representative of actually occurring online speech and is likely to facilitate the removal of the social media content that marginalized communities view as causing the most harm. Based on XTREMESPEECH, we establish novel tasks with accompanying baselines, provide evidence that cross-country training is generally not feasible due to cultural differences between countries and perform an interpretability analysis of BERT's predictions.
Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP
Feb 28, 2021
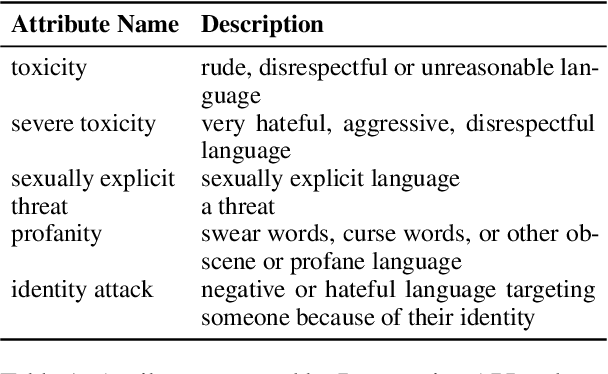


When trained on large, unfiltered crawls from the internet, language models pick up and reproduce all kinds of undesirable biases that can be found in the data: they often generate racist, sexist, violent or otherwise toxic language. As large models often require millions of training examples to achieve good performance, it is difficult to completely prevent them from being exposed to such content. In this paper, we investigate whether pretrained language models at least know when they exhibit some undesirable bias or produce toxic content. Based on our findings, we propose a decoding algorithm that reduces the probability of a model producing problematic text given only a textual description of the undesired behavior. This algorithm does not rely on manually curated word lists, nor does it require any training data or changes to the model's parameters. While our approach does by no means eliminate the issue of language models generating biased text, we believe it to be an important step in this direction.