 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWordScape: a Pipeline to extract multilingual, visually rich Documents with Layout Annotations from Web Crawl Data
Dec 15, 2023

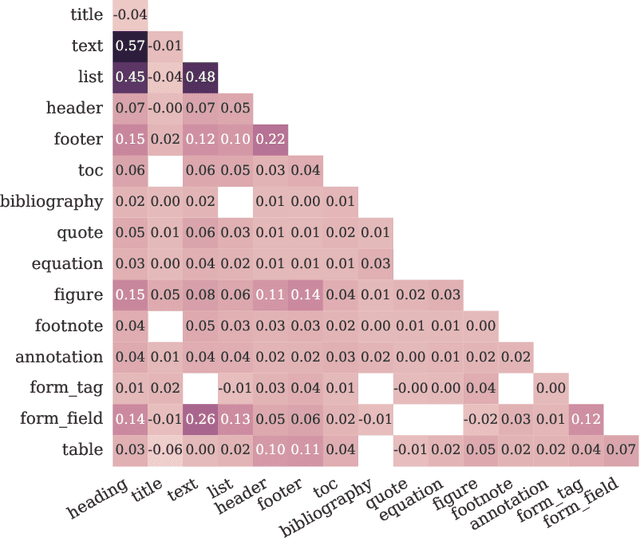
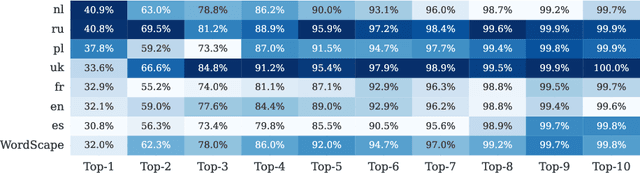
We introduce WordScape, a novel pipeline for the creation of cross-disciplinary, multilingual corpora comprising millions of pages with annotations for document layout detection. Relating visual and textual items on document pages has gained further significance with the advent of multimodal models. Various approaches proved effective for visual question answering or layout segmentation. However, the interplay of text, tables, and visuals remains challenging for a variety of document understanding tasks. In particular, many models fail to generalize well to diverse domains and new languages due to insufficient availability of training data. WordScape addresses these limitations. Our automatic annotation pipeline parses the Open XML structure of Word documents obtained from the web, jointly providing layout-annotated document images and their textual representations. In turn, WordScape offers unique properties as it (1) leverages the ubiquity of the Word file format on the internet, (2) is readily accessible through the Common Crawl web corpus, (3) is adaptive to domain-specific documents, and (4) offers culturally and linguistically diverse document pages with natural semantic structure and high-quality text. Together with the pipeline, we will additionally release 9.5M urls to word documents which can be processed using WordScape to create a dataset of over 40M pages. Finally, we investigate the quality of text and layout annotations extracted by WordScape, assess the impact on document understanding benchmarks, and demonstrate that manual labeling costs can be substantially reduced.
MorphPiece : Moving away from Statistical Language Representation
Jul 14, 2023Tokenization is a critical part of modern NLP pipelines. However, contemporary tokenizers for Large Language Models are based on statistical analysis of text corpora, without much consideration to the linguistic features. We propose a linguistically motivated tokenization scheme, MorphPiece, which is based partly on morphological segmentation of the underlying text. A GPT-style causal language model trained on this tokenizer (called MorphGPT) shows superior convergence compared to the same architecture trained on a standard BPE tokenizer. Specifically we get Language Modeling performance comparable to a 6 times larger model. Additionally, we evaluate MorphGPT on a variety of NLP tasks in supervised and unsupervised settings and find superior performance across the board, compared to GPT-2 model.
Flow-Adapter Architecture for Unsupervised Machine Translation
Apr 26, 2022

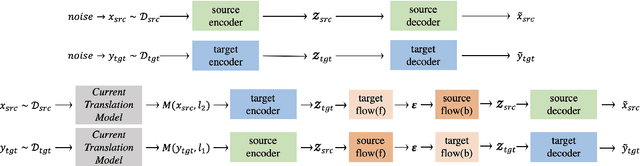

In this work, we propose a flow-adapter architecture for unsupervised NMT. It leverages normalizing flows to explicitly model the distributions of sentence-level latent representations, which are subsequently used in conjunction with the attention mechanism for the translation task. The primary novelties of our model are: (a) capturing language-specific sentence representations separately for each language using normalizing flows and (b) using a simple transformation of these latent representations for translating from one language to another. This architecture allows for unsupervised training of each language independently. While there is prior work on latent variables for supervised MT, to the best of our knowledge, this is the first work that uses latent variables and normalizing flows for unsupervised MT. We obtain competitive results on several unsupervised MT benchmarks.
Listening to Affected Communities to Define Extreme Speech: Dataset and Experiments
Mar 22, 2022
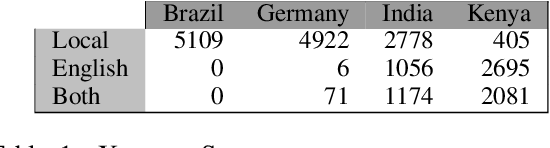

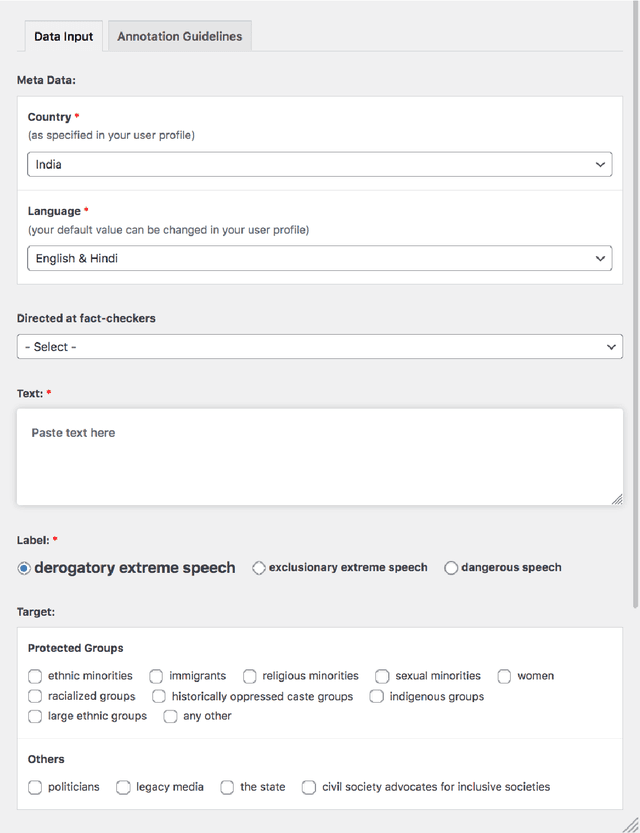
Building on current work on multilingual hate speech (e.g., Ousidhoum et al. (2019)) and hate speech reduction (e.g., Sap et al. (2020)), we present XTREMESPEECH, a new hate speech dataset containing 20,297 social media passages from Brazil, Germany, India and Kenya. The key novelty is that we directly involve the affected communities in collecting and annotating the data - as opposed to giving companies and governments control over defining and combatting hate speech. This inclusive approach results in datasets more representative of actually occurring online speech and is likely to facilitate the removal of the social media content that marginalized communities view as causing the most harm. Based on XTREMESPEECH, we establish novel tasks with accompanying baselines, provide evidence that cross-country training is generally not feasible due to cultural differences between countries and perform an interpretability analysis of BERT's predictions.