 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphPiece : Moving away from Statistical Language Representation
Paper and Code
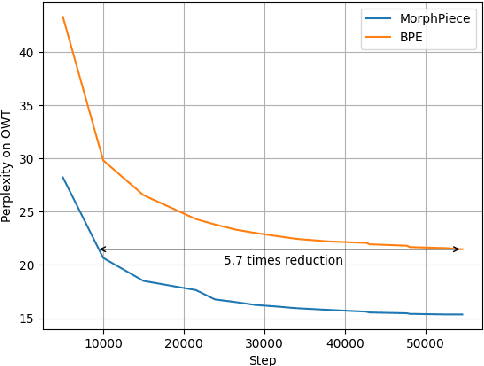
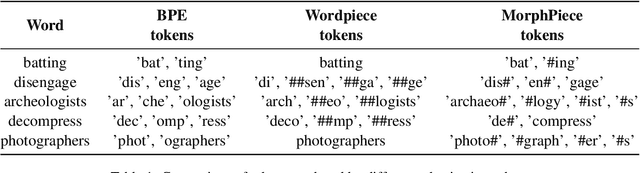
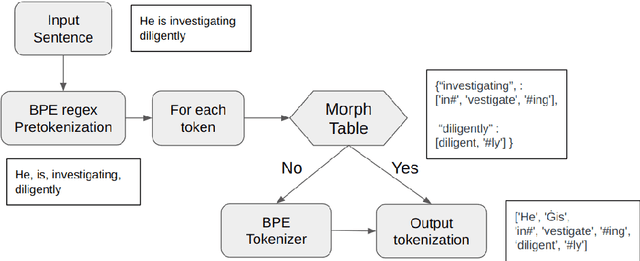
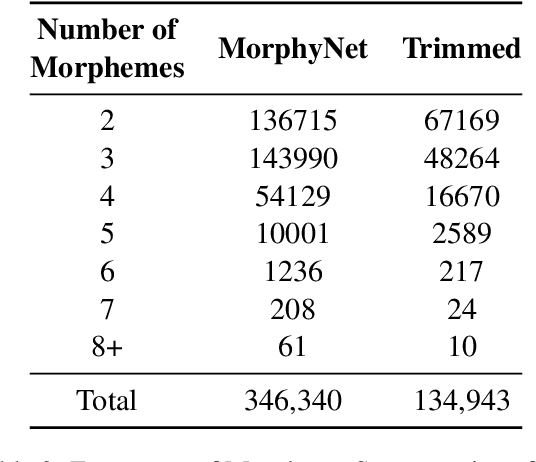
Tokenization is a critical part of modern NLP pipelines. However, contemporary tokenizers for Large Language Models are based on statistical analysis of text corpora, without much consideration to the linguistic features. We propose a linguistically motivated tokenization scheme, MorphPiece, which is based partly on morphological segmentation of the underlying text. A GPT-style causal language model trained on this tokenizer (called MorphGPT) shows superior convergence compared to the same architecture trained on a standard BPE tokenizer. Specifically we get Language Modeling performance comparable to a 6 times larger model. Additionally, we evaluate MorphGPT on a variety of NLP tasks in supervised and unsupervised settings and find superior performance across the board, compared to GPT-2 model.