 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations
Apr 09, 2024


The accurate evaluation of differential treatment in language models to specific groups is critical to ensuring a positive and safe user experience. An ideal evaluation should have the properties of being robust, extendable to new groups or attributes, and being able to capture biases that appear in typical usage (rather than just extreme, rare cases). Relatedly, bias evaluation should surface not only egregious biases but also ones that are subtle and commonplace, such as a likelihood for talking about appearances with regard to women. We present FairPair, an evaluation framework for assessing differential treatment that occurs during ordinary usage. FairPair operates through counterfactual pairs, but crucially, the paired continuations are grounded in the same demographic group, which ensures equivalent comparison. Additionally, unlike prior work, our method factors in the inherent variability that comes from the generation process itself by measuring the sampling variability. We present an evaluation of several commonly used generative models and a qualitative analysis that indicates a preference for discussing family and hobbies with regard to women.
Evaluation of Faithfulness Using the Longest Supported Subsequence
Aug 23, 2023As increasingly sophisticated language models emerge, their trustworthiness becomes a pivotal issue, especially in tasks such as summarization and question-answering. Ensuring their responses are contextually grounded and faithful is challenging due to the linguistic diversity and the myriad of possible answers. In this paper, we introduce a novel approach to evaluate faithfulness of machine-generated text by computing the longest noncontinuous substring of the claim that is supported by the context, which we refer to as the Longest Supported Subsequence (LSS). Using a new human-annotated dataset, we finetune a model to generate LSS. We introduce a new method of evaluation and demonstrate that these metrics correlate better with human ratings when LSS is employed, as opposed to when it is not. Our proposed metric demonstrates an 18% enhancement over the prevailing state-of-the-art metric for faithfulness on our dataset. Our metric consistently outperforms other metrics on a summarization dataset across six different models. Finally, we compare several popular Large Language Models (LLMs) for faithfulness using this metric. We release the human-annotated dataset built for predicting LSS and our fine-tuned model for evaluating faithfulness.
Self-Alignment with Instruction Backtranslation
Aug 14, 2023

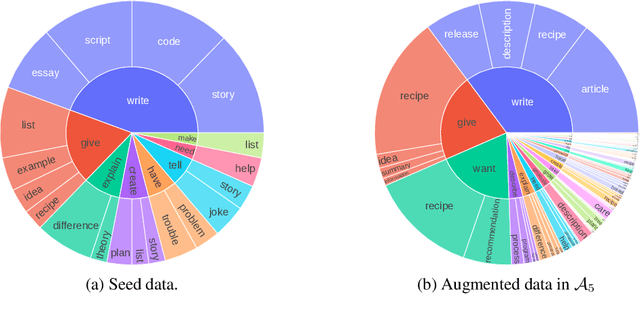
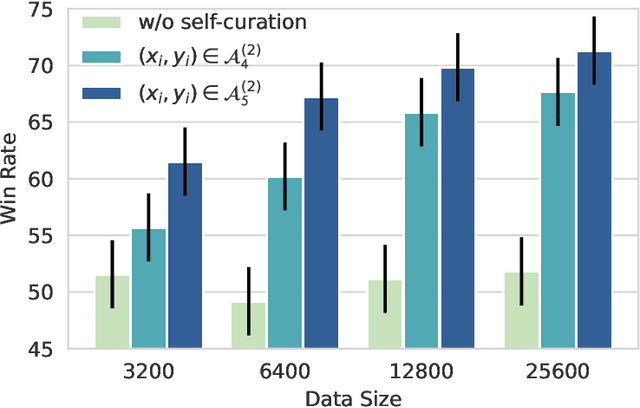
We present a scalable method to build a high quality instruction following language model by automatically labelling human-written text with corresponding instructions. Our approach, named instruction backtranslation, starts with a language model finetuned on a small amount of seed data, and a given web corpus. The seed model is used to construct training examples by generating instruction prompts for web documents (self-augmentation), and then selecting high quality examples from among these candidates (self-curation). This data is then used to finetune a stronger model. Finetuning LLaMa on two iterations of our approach yields a model that outperforms all other LLaMa-based models on the Alpaca leaderboard not relying on distillation data, demonstrating highly effective self-alignment.
Active Learning Principles for In-Context Learning with Large Language Models
May 23, 2023The remarkable advancements in large language models (LLMs) have significantly enhanced the performance in few-shot learning settings. By using only a small number of labeled examples, referred to as demonstrations, LLMs can effectively grasp the task at hand through in-context learning. However, the process of selecting appropriate demonstrations has received limited attention in prior work. This paper addresses the issue of identifying the most informative demonstrations for few-shot learning by approaching it as a pool-based Active Learning (AL) problem over a single iteration. Our objective is to investigate how AL algorithms can serve as effective demonstration selection methods for in-context learning. We compare various standard AL algorithms based on uncertainty, diversity, and similarity, and consistently observe that the latter outperforms all other methods, including random sampling. Notably, uncertainty sampling, despite its success in conventional supervised learning scenarios, performs poorly in this context. Our extensive experimentation involving a diverse range of GPT and OPT models across $24$ classification and multi-choice tasks, coupled with thorough analysis, unambiguously demonstrates that in-context example selection through AL prioritizes high-quality examples that exhibit low uncertainty and bear similarity to the test examples.
LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction
Apr 17, 2023Instruction tuning enables language models to generalize more effectively and better follow user intent. However, obtaining instruction data can be costly and challenging. Prior works employ methods such as expensive human annotation, crowd-sourced datasets with alignment issues, or generating noisy examples via LLMs. We introduce the LongForm dataset, which is created by leveraging English corpus examples with augmented instructions. We select a diverse set of human-written documents from existing corpora such as C4 and Wikipedia and generate instructions for the given documents via LLMs. This approach provides a cheaper and cleaner instruction-tuning dataset and one suitable for long text generation. We finetune T5, OPT, and LLaMA models on our dataset and show that even smaller LongForm models have good generalization capabilities for text generation. Our models outperform 10x larger language models without instruction tuning on various tasks such as story/recipe generation and long-form question answering. Moreover, LongForm models outperform prior instruction-tuned models such as FLAN-T5 and Alpaca by a large margin. Finally, our models can effectively follow and answer multilingual instructions; we demonstrate this for news generation. We publicly release our data and models: https://github.com/akoksal/LongForm.
Augmented Language Models: a Survey
Feb 15, 2023



This survey reviews works in which language models (LMs) are augmented with reasoning skills and the ability to use tools. The former is defined as decomposing a potentially complex task into simpler subtasks while the latter consists in calling external modules such as a code interpreter. LMs can leverage these augmentations separately or in combination via heuristics, or learn to do so from demonstrations. While adhering to a standard missing tokens prediction objective, such augmented LMs can use various, possibly non-parametric external modules to expand their context processing ability, thus departing from the pure language modeling paradigm. We therefore refer to them as Augmented Language Models (ALMs). The missing token objective allows ALMs to learn to reason, use tools, and even act, while still performing standard natural language tasks and even outperforming most regular LMs on several benchmarks. In this work, after reviewing current advance in ALMs, we conclude that this new research direction has the potential to address common limitations of traditional LMs such as interpretability, consistency, and scalability issues.
Toolformer: Language Models Can Teach Themselves to Use Tools
Feb 09, 2023


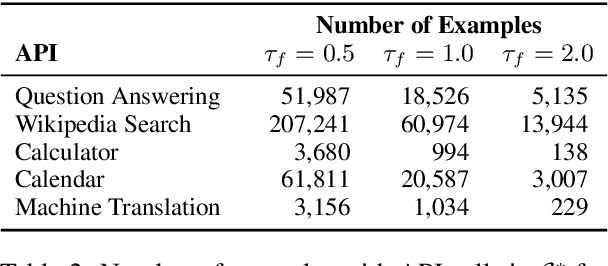
Language models (LMs) exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpler and smaller models excel. In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds. We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q\&A system, two different search engines, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modeling abilities.
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
Dec 19, 2022



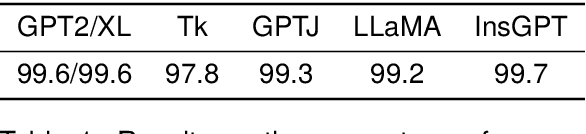
Instruction tuning enables pretrained language models to perform new tasks from inference-time natural language descriptions. These approaches rely on vast amounts of human supervision in the form of crowdsourced datasets or user interactions. In this work, we introduce Unnatural Instructions: a large dataset of creative and diverse instructions, collected with virtually no human labor. We collect 64,000 examples by prompting a language model with three seed examples of instructions and eliciting a fourth. This set is then expanded by prompting the model to rephrase each instruction, creating a total of approximately 240,000 examples of instructions, inputs, and outputs. Experiments show that despite containing a fair amount of noise, training on Unnatural Instructions rivals the effectiveness of training on open-source manually-curated datasets, surpassing the performance of models such as T0++ and Tk-Instruct across various benchmarks. These results demonstrate the potential of model-generated data as a cost-effective alternative to crowdsourcing for dataset expansion and diversification.
Task-aware Retrieval with Instructions
Nov 16, 2022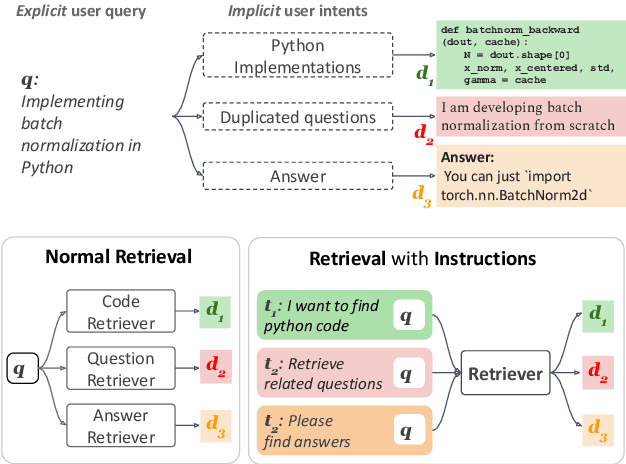

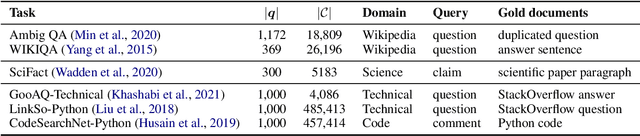
We study the problem of retrieval with instructions, where users of a retrieval system explicitly describe their intent along with their queries, making the system task-aware. We aim to develop a general-purpose task-aware retrieval systems using multi-task instruction tuning that can follow human-written instructions to find the best documents for a given query. To this end, we introduce the first large-scale collection of approximately 40 retrieval datasets with instructions, and present TART, a multi-task retrieval system trained on the diverse retrieval tasks with instructions. TART shows strong capabilities to adapt to a new task via instructions and advances the state of the art on two zero-shot retrieval benchmarks, BEIR and LOTTE, outperforming models up to three times larger. We further introduce a new evaluation setup to better reflect real-world scenarios, pooling diverse documents and tasks. In this setup, TART significantly outperforms competitive baselines, further demonstrating the effectiveness of guiding retrieval with instructions.
MEAL: Stable and Active Learning for Few-Shot Prompting
Nov 15, 2022
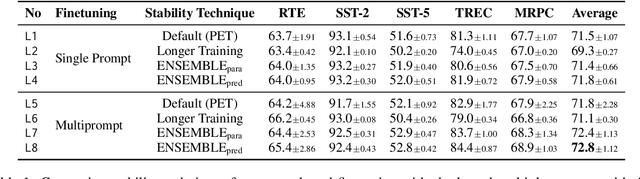


Few-shot classification in NLP has recently made great strides due to the availability of large foundation models that, through priming and prompting, are highly effective few-shot learners. However, this approach has high variance across different sets of few shots and across different finetuning runs. For example, we find that validation accuracy on RTE can vary by as much as 27 points. In this context, we make two contributions for more effective few-shot learning. First, we propose novel ensembling methods and show that they substantially reduce variance. Second, since performance depends a lot on the set of few shots selected, active learning is promising for few-shot classification. Based on our stable ensembling method, we build on existing work on active learning and introduce a new criterion: inter-prompt uncertainty sampling with diversity. We present the first active learning based approach to select training examples for prompt-based learning and show that it outperforms prior work on active learning. Finally, we show that our combined method, MEAL (Multiprompt finetuning and prediction Ensembling with Active Learning), improves overall performance of prompt-based finetuning by 2.3 absolute points on five different tasks.