 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEAL: Stable and Active Learning for Few-Shot Prompting
Paper and Code

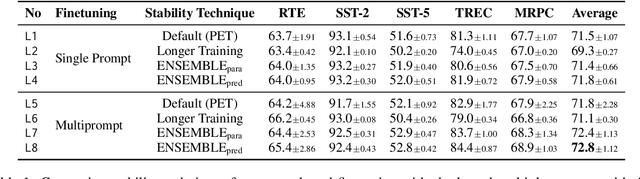


Few-shot classification in NLP has recently made great strides due to the availability of large foundation models that, through priming and prompting, are highly effective few-shot learners. However, this approach has high variance across different sets of few shots and across different finetuning runs. For example, we find that validation accuracy on RTE can vary by as much as 27 points. In this context, we make two contributions for more effective few-shot learning. First, we propose novel ensembling methods and show that they substantially reduce variance. Second, since performance depends a lot on the set of few shots selected, active learning is promising for few-shot classification. Based on our stable ensembling method, we build on existing work on active learning and introduce a new criterion: inter-prompt uncertainty sampling with diversity. We present the first active learning based approach to select training examples for prompt-based learning and show that it outperforms prior work on active learning. Finally, we show that our combined method, MEAL (Multiprompt finetuning and prediction Ensembling with Active Learning), improves overall performance of prompt-based finetuning by 2.3 absolute points on five different tasks.