 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgree To Disagree
Sep 24, 2023How frequently do individuals thoroughly review terms and conditions before proceeding to register for a service, install software, or access a website? The majority of internet users do not engage in this practice. This trend is not surprising, given that terms and conditions typically consist of lengthy documents replete with intricate legal terminology and convoluted sentences. In this paper, we introduce a Machine Learning-powered approach designed to automatically parse and summarize critical information in a user-friendly manner. This technology focuses on distilling the pertinent details that users should contemplate before committing to an agreement.
Evaluation of Faithfulness Using the Longest Supported Subsequence
Aug 23, 2023As increasingly sophisticated language models emerge, their trustworthiness becomes a pivotal issue, especially in tasks such as summarization and question-answering. Ensuring their responses are contextually grounded and faithful is challenging due to the linguistic diversity and the myriad of possible answers. In this paper, we introduce a novel approach to evaluate faithfulness of machine-generated text by computing the longest noncontinuous substring of the claim that is supported by the context, which we refer to as the Longest Supported Subsequence (LSS). Using a new human-annotated dataset, we finetune a model to generate LSS. We introduce a new method of evaluation and demonstrate that these metrics correlate better with human ratings when LSS is employed, as opposed to when it is not. Our proposed metric demonstrates an 18% enhancement over the prevailing state-of-the-art metric for faithfulness on our dataset. Our metric consistently outperforms other metrics on a summarization dataset across six different models. Finally, we compare several popular Large Language Models (LLMs) for faithfulness using this metric. We release the human-annotated dataset built for predicting LSS and our fine-tuned model for evaluating faithfulness.
AmbiPun: Generating Humorous Puns with Ambiguous Context
May 04, 2022


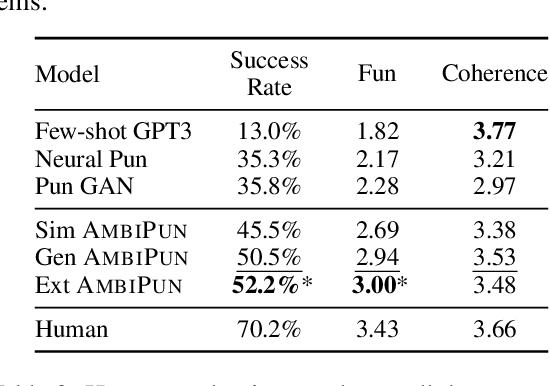
In this paper, we propose a simple yet effective way to generate pun sentences that does not require any training on existing puns. Our approach is inspired by humor theories that ambiguity comes from the context rather than the pun word itself. Given a pair of definitions of a pun word, our model first produces a list of related concepts through a reverse dictionary. We then utilize one-shot GPT3 to generate context words and then generate puns incorporating context words from both concepts. Human evaluation shows that our method successfully generates pun 52\% of the time, outperforming well-crafted baselines and the state-of-the-art models by a large margin.
Tapping BERT for Preposition Sense Disambiguation
Nov 27, 2021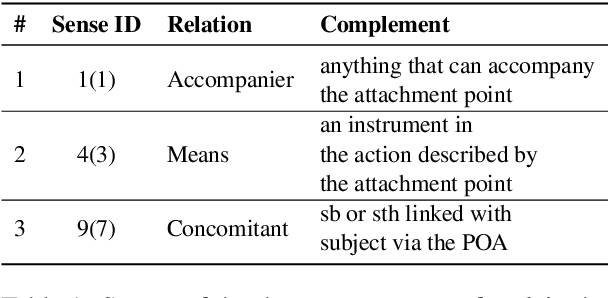
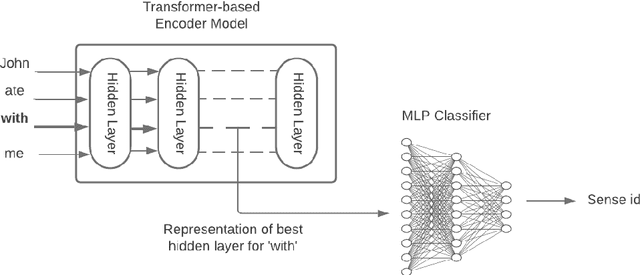

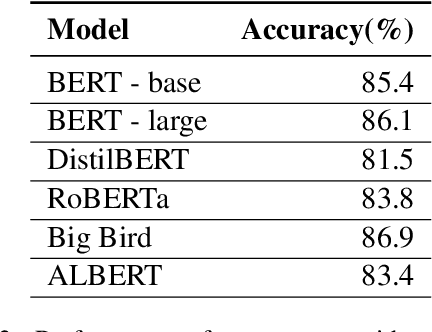
Prepositions are frequently occurring polysemous words. Disambiguation of prepositions is crucial in tasks like semantic role labelling, question answering, text entailment, and noun compound paraphrasing. In this paper, we propose a novel methodology for preposition sense disambiguation (PSD), which does not use any linguistic tools. In a supervised setting, the machine learning model is presented with sentences wherein prepositions have been annotated with senses. These senses are IDs in what is called The Preposition Project (TPP). We use the hidden layer representations from pre-trained BERT and BERT variants. The latent representations are then classified into the correct sense ID using a Multi Layer Perceptron. The dataset used for this task is from SemEval-2007 Task-6. Our methodology gives an accuracy of 86.85% which is better than the state-of-the-art.
"So You Think You're Funny?": Rating the Humour Quotient in Standup Comedy
Oct 25, 2021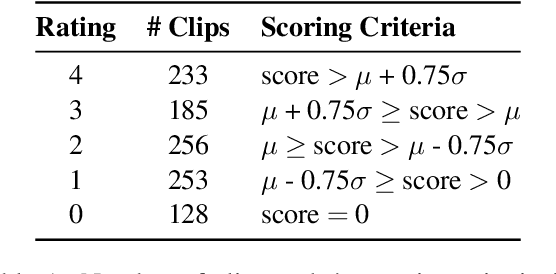
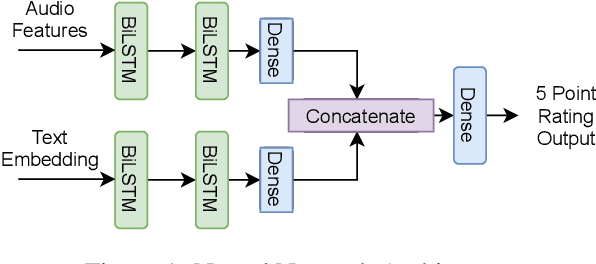


Computational Humour (CH) has attracted the interest of Natural Language Processing and Computational Linguistics communities. Creating datasets for automatic measurement of humour quotient is difficult due to multiple possible interpretations of the content. In this work, we create a multi-modal humour-annotated dataset ($\sim$40 hours) using stand-up comedy clips. We devise a novel scoring mechanism to annotate the training data with a humour quotient score using the audience's laughter. The normalized duration (laughter duration divided by the clip duration) of laughter in each clip is used to compute this humour coefficient score on a five-point scale (0-4). This method of scoring is validated by comparing with manually annotated scores, wherein a quadratic weighted kappa of 0.6 is obtained. We use this dataset to train a model that provides a "funniness" score, on a five-point scale, given the audio and its corresponding text. We compare various neural language models for the task of humour-rating and achieve an accuracy of $0.813$ in terms of Quadratic Weighted Kappa (QWK). Our "Open Mic" dataset is released for further research along with the code.