 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTapping BERT for Preposition Sense Disambiguation
Nov 27, 2021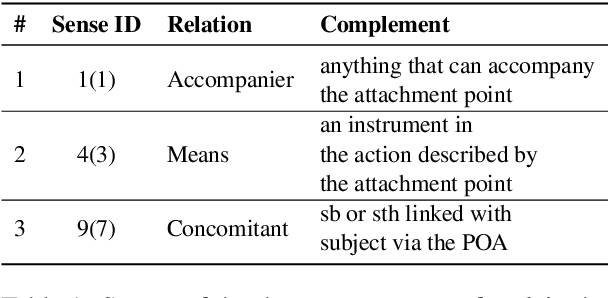
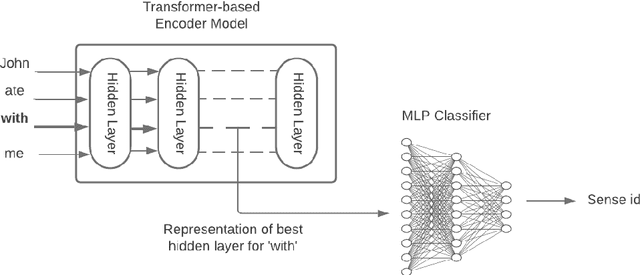

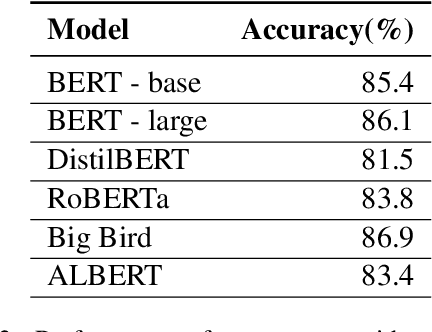
Prepositions are frequently occurring polysemous words. Disambiguation of prepositions is crucial in tasks like semantic role labelling, question answering, text entailment, and noun compound paraphrasing. In this paper, we propose a novel methodology for preposition sense disambiguation (PSD), which does not use any linguistic tools. In a supervised setting, the machine learning model is presented with sentences wherein prepositions have been annotated with senses. These senses are IDs in what is called The Preposition Project (TPP). We use the hidden layer representations from pre-trained BERT and BERT variants. The latent representations are then classified into the correct sense ID using a Multi Layer Perceptron. The dataset used for this task is from SemEval-2007 Task-6. Our methodology gives an accuracy of 86.85% which is better than the state-of-the-art.