 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTapping BERT for Preposition Sense Disambiguation
Nov 27, 2021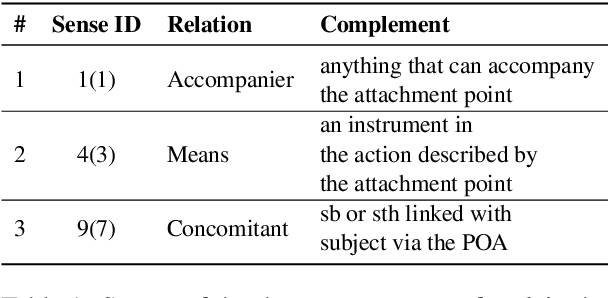
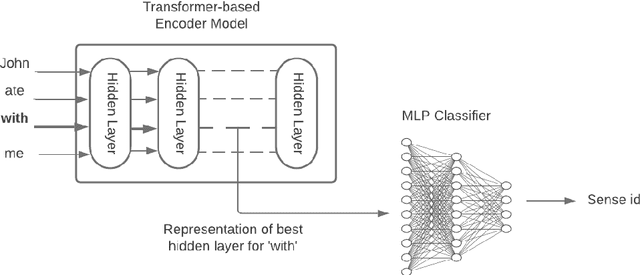

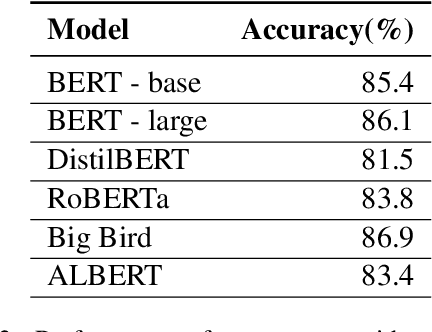
Prepositions are frequently occurring polysemous words. Disambiguation of prepositions is crucial in tasks like semantic role labelling, question answering, text entailment, and noun compound paraphrasing. In this paper, we propose a novel methodology for preposition sense disambiguation (PSD), which does not use any linguistic tools. In a supervised setting, the machine learning model is presented with sentences wherein prepositions have been annotated with senses. These senses are IDs in what is called The Preposition Project (TPP). We use the hidden layer representations from pre-trained BERT and BERT variants. The latent representations are then classified into the correct sense ID using a Multi Layer Perceptron. The dataset used for this task is from SemEval-2007 Task-6. Our methodology gives an accuracy of 86.85% which is better than the state-of-the-art.
Multimodal Depression Severity Prediction from medical bio-markers using Machine Learning Tools and Technologies
Oct 06, 2020
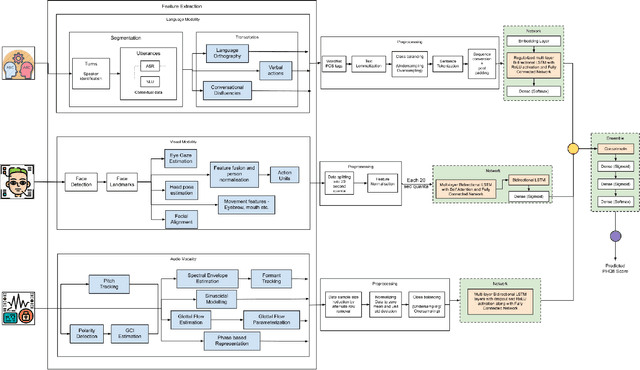

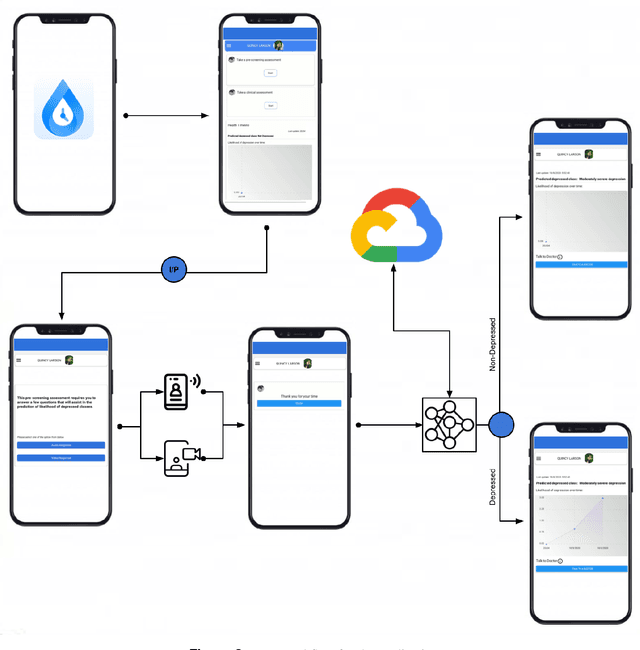
Depression has been a leading cause of mental-health illnesses across the world. While the loss of lives due to unmanaged depression is a subject of attention, so is the lack of diagnostic tests and subjectivity involved. Using behavioural cues to automate depression diagnosis and stage prediction in recent years has relatively increased. However, the absence of labelled behavioural datasets and a vast amount of possible variations prove to be a major challenge in accomplishing the task. This paper proposes a novel Custom CM Ensemble approach and focuses on a paradigm of a cross-platform smartphone application that takes multimodal inputs from a user through a series of pre-defined questions, sends it to the Cloud ML architecture and conveys back a depression quotient, representative of its severity. Our app estimates the severity of depression based on a multi-class classification model by utilizing the language, audio, and visual modalities. The given approach attempts to detect, emphasize, and classify the features of a depressed person based on the low-level descriptors for verbal and visual features, and context of the language features when prompted with a question. The model achieved a precision value of 0.88 and an accuracy of 91.56%. Further optimization reveals the intramodality and intermodality relevance through the selection of the most influential features within each modality for decision making.