 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Kurosawa": A Script Writer's Assistant
Aug 06, 2023Storytelling is the lifeline of the entertainment industry -- movies, TV shows, and stand-up comedies, all need stories. A good and gripping script is the lifeline of storytelling and demands creativity and resource investment. Good scriptwriters are rare to find and often work under severe time pressure. Consequently, entertainment media are actively looking for automation. In this paper, we present an AI-based script-writing workbench called KUROSAWA which addresses the tasks of plot generation and script generation. Plot generation aims to generate a coherent and creative plot (600-800 words) given a prompt (15-40 words). Script generation, on the other hand, generates a scene (200-500 words) in a screenplay format from a brief description (15-40 words). Kurosawa needs data to train. We use a 4-act structure of storytelling to annotate the plot dataset manually. We create a dataset of 1000 manually annotated plots and their corresponding prompts/storylines and a gold-standard dataset of 1000 scenes with four main elements -- scene headings, action lines, dialogues, and character names -- tagged individually. We fine-tune GPT-3 with the above datasets to generate plots and scenes. These plots and scenes are first evaluated and then used by the scriptwriters of a large and famous media platform ErosNow. We release the annotated datasets and the models trained on these datasets as a working benchmark for automatic movie plot and script generation.
"So You Think You're Funny?": Rating the Humour Quotient in Standup Comedy
Oct 25, 2021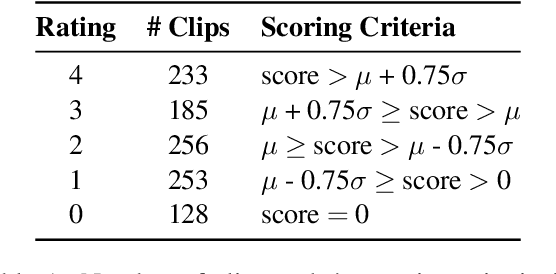
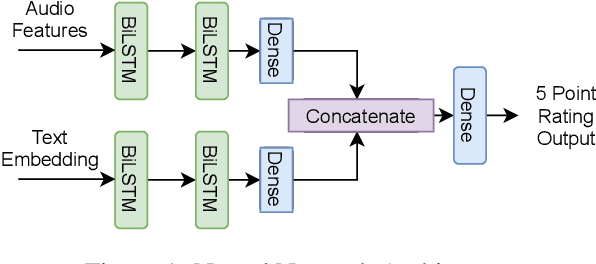


Computational Humour (CH) has attracted the interest of Natural Language Processing and Computational Linguistics communities. Creating datasets for automatic measurement of humour quotient is difficult due to multiple possible interpretations of the content. In this work, we create a multi-modal humour-annotated dataset ($\sim$40 hours) using stand-up comedy clips. We devise a novel scoring mechanism to annotate the training data with a humour quotient score using the audience's laughter. The normalized duration (laughter duration divided by the clip duration) of laughter in each clip is used to compute this humour coefficient score on a five-point scale (0-4). This method of scoring is validated by comparing with manually annotated scores, wherein a quadratic weighted kappa of 0.6 is obtained. We use this dataset to train a model that provides a "funniness" score, on a five-point scale, given the audio and its corresponding text. We compare various neural language models for the task of humour-rating and achieve an accuracy of $0.813$ in terms of Quadratic Weighted Kappa (QWK). Our "Open Mic" dataset is released for further research along with the code.