 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHessian-Enhanced Token Attribution (HETA): Interpreting Autoregressive LLMs
Apr 14, 2026Attribution methods seek to explain language model predictions by quantifying the contribution of input tokens to generated outputs. However, most existing techniques are designed for encoder-based architectures and rely on linear approximations that fail to capture the causal and semantic complexities of autoregressive generation in decoder-only models. To address these limitations, we propose Hessian-Enhanced Token Attribution (HETA), a novel attribution framework tailored for decoder-only language models. HETA combines three complementary components: a semantic transition vector that captures token-to-token influence across layers, Hessian-based sensitivity scores that model second-order effects, and KL divergence to measure information loss when tokens are masked. This unified design produces context-aware, causally faithful, and semantically grounded attributions. Additionally, we introduce a curated benchmark dataset for systematically evaluating attribution quality in generative settings. Empirical evaluations across multiple models and datasets demonstrate that HETA consistently outperforms existing methods in attribution faithfulness and alignment with human annotations, establishing a new standard for interpretability in autoregressive language models.
Jailbreaking the Matrix: Nullspace Steering for Controlled Model Subversion
Apr 11, 2026Large language models remain vulnerable to jailbreak attacks -- inputs designed to bypass safety mechanisms and elicit harmful responses -- despite advances in alignment and instruction tuning. We propose Head-Masked Nullspace Steering (HMNS), a circuit-level intervention that (i) identifies attention heads most causally responsible for a model's default behavior, (ii) suppresses their write paths via targeted column masking, and (iii) injects a perturbation constrained to the orthogonal complement of the muted subspace. HMNS operates in a closed-loop detection-intervention cycle, re-identifying causal heads and reapplying interventions across multiple decoding attempts. Across multiple jailbreak benchmarks, strong safety defenses, and widely used language models, HMNS attains state-of-the-art attack success rates with fewer queries than prior methods. Ablations confirm that nullspace-constrained injection, residual norm scaling, and iterative re-identification are key to its effectiveness. To our knowledge, this is the first jailbreak method to leverage geometry-aware, interpretability-informed interventions, highlighting a new paradigm for controlled model steering and adversarial safety circumvention.
Hey AI Can You Grade My Essay?: Automatic Essay Grading
Oct 12, 2024Automatic essay grading (AEG) has attracted the the attention of the NLP community because of its applications to several educational applications, such as scoring essays, short answers, etc. AEG systems can save significant time and money when grading essays. In the existing works, the essays are graded where a single network is responsible for the whole process, which may be ineffective because a single network may not be able to learn all the features of a human-written essay. In this work, we have introduced a new model that outperforms the state-of-the-art models in the field of AEG. We have used the concept of collaborative and transfer learning, where one network will be responsible for checking the grammatical and structural features of the sentences of an essay while another network is responsible for scoring the overall idea present in the essay. These learnings are transferred to another network to score the essay. We also compared the performances of the different models mentioned in our work, and our proposed model has shown the highest accuracy of 85.50%.
"Kurosawa": A Script Writer's Assistant
Aug 06, 2023
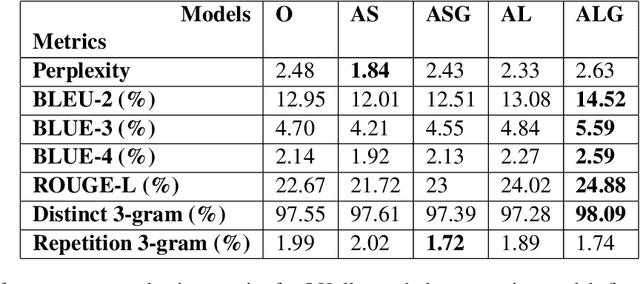
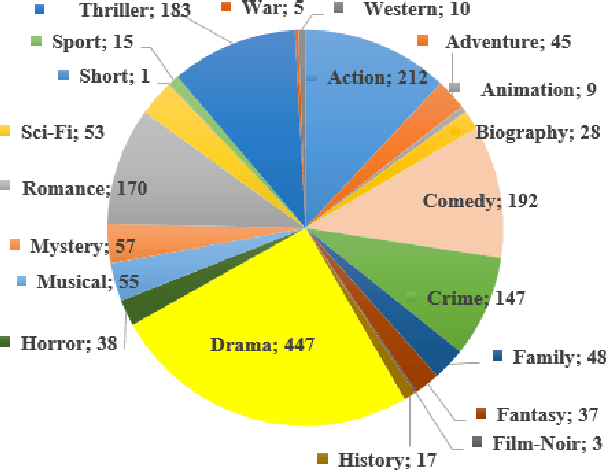

Storytelling is the lifeline of the entertainment industry -- movies, TV shows, and stand-up comedies, all need stories. A good and gripping script is the lifeline of storytelling and demands creativity and resource investment. Good scriptwriters are rare to find and often work under severe time pressure. Consequently, entertainment media are actively looking for automation. In this paper, we present an AI-based script-writing workbench called KUROSAWA which addresses the tasks of plot generation and script generation. Plot generation aims to generate a coherent and creative plot (600-800 words) given a prompt (15-40 words). Script generation, on the other hand, generates a scene (200-500 words) in a screenplay format from a brief description (15-40 words). Kurosawa needs data to train. We use a 4-act structure of storytelling to annotate the plot dataset manually. We create a dataset of 1000 manually annotated plots and their corresponding prompts/storylines and a gold-standard dataset of 1000 scenes with four main elements -- scene headings, action lines, dialogues, and character names -- tagged individually. We fine-tune GPT-3 with the above datasets to generate plots and scenes. These plots and scenes are first evaluated and then used by the scriptwriters of a large and famous media platform ErosNow. We release the annotated datasets and the models trained on these datasets as a working benchmark for automatic movie plot and script generation.