 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"So You Think You're Funny?": Rating the Humour Quotient in Standup Comedy
Paper and Code
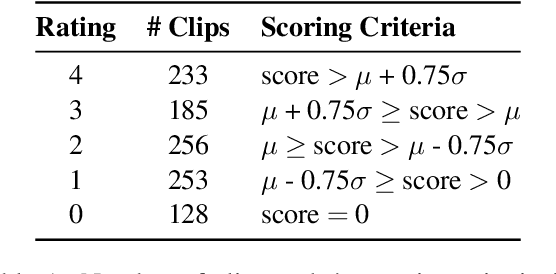
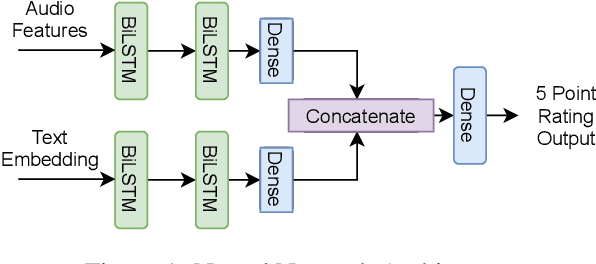


Computational Humour (CH) has attracted the interest of Natural Language Processing and Computational Linguistics communities. Creating datasets for automatic measurement of humour quotient is difficult due to multiple possible interpretations of the content. In this work, we create a multi-modal humour-annotated dataset ($\sim$40 hours) using stand-up comedy clips. We devise a novel scoring mechanism to annotate the training data with a humour quotient score using the audience's laughter. The normalized duration (laughter duration divided by the clip duration) of laughter in each clip is used to compute this humour coefficient score on a five-point scale (0-4). This method of scoring is validated by comparing with manually annotated scores, wherein a quadratic weighted kappa of 0.6 is obtained. We use this dataset to train a model that provides a "funniness" score, on a five-point scale, given the audio and its corresponding text. We compare various neural language models for the task of humour-rating and achieve an accuracy of $0.813$ in terms of Quadratic Weighted Kappa (QWK). Our "Open Mic" dataset is released for further research along with the code.