 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Preference Learning: The Case of Label Ranking
May 28, 2026Calibration, the alignment of predicted probabilities with true outcome frequencies, is essential for reliable decision-making. While extensively studied for classification and regression, calibration has not been formally addressed for probabilistic label ranking, where the goal is to predict a distribution over orderings of a label set. Naively treating rankings as classes ignores their structure and fails to capture important modalities such as pairwise and top-k predictions. We formalize calibration for label ranking and develop a hierarchy of notions covering full rankings, sub-rankings, and top-k rankings. We prove that full-rank calibration implies the others but not conversely, and sub-ranking and top-k calibration are incomparable. Empirically, we find popular label ranking models are often poorly calibrated, with substantial differences between sub-ranking and top-k metrics. Applying our framework to RLHF reward models, we find that calibration correlates strongly but not perfectly with benchmark accuracy, suggesting it captures a meaningful quality dimension beyond top-1 accuracy. These findings motivate future work on understanding the downstream effects of miscalibration and developing methods to correct it.
ResponseRank: Data-Efficient Reward Modeling through Preference Strength Learning
Dec 31, 2025Binary choices, as often used for reinforcement learning from human feedback (RLHF), convey only the direction of a preference. A person may choose apples over oranges and bananas over grapes, but which preference is stronger? Strength is crucial for decision-making under uncertainty and generalization of preference models, but hard to measure reliably. Metadata such as response times and inter-annotator agreement can serve as proxies for strength, but are often noisy and confounded. We propose ResponseRank to address the challenge of learning from noisy strength signals. Our method uses relative differences in proxy signals to rank responses to pairwise comparisons by their inferred preference strength. To control for systemic variation, we compare signals only locally within carefully constructed strata. This enables robust learning of utility differences consistent with strength-derived rankings while making minimal assumptions about the strength signal. Our contributions are threefold: (1) ResponseRank, a novel method that robustly learns preference strength by leveraging locally valid relative strength signals; (2) empirical evidence of improved sample efficiency and robustness across diverse tasks: synthetic preference learning (with simulated response times), language modeling (with annotator agreement), and RL control tasks (with simulated episode returns); and (3) the Pearson Distance Correlation (PDC), a novel metric that isolates cardinal utility learning from ordinal accuracy.
Problem Solving Through Human-AI Preference-Based Cooperation
Aug 15, 2024


While there is a widespread belief that artificial general intelligence (AGI) -- or even superhuman AI -- is imminent, complex problems in expert domains are far from being solved. We argue that such problems require human-AI cooperation and that the current state of the art in generative AI is unable to play the role of a reliable partner due to a multitude of shortcomings, including inability to keep track of a complex solution artifact (e.g., a software program), limited support for versatile human preference expression and lack of adapting to human preference in an interactive setting. To address these challenges, we propose HAI-Co2, a novel human-AI co-construction framework. We formalize HAI-Co2 and discuss the difficult open research problems that it faces. Finally, we present a case study of HAI-Co2 and demonstrate its efficacy compared to monolithic generative AI models.
OCALM: Object-Centric Assessment with Language Models
Jun 24, 2024



Properly defining a reward signal to efficiently train a reinforcement learning (RL) agent is a challenging task. Designing balanced objective functions from which a desired behavior can emerge requires expert knowledge, especially for complex environments. Learning rewards from human feedback or using large language models (LLMs) to directly provide rewards are promising alternatives, allowing non-experts to specify goals for the agent. However, black-box reward models make it difficult to debug the reward. In this work, we propose Object-Centric Assessment with Language Models (OCALM) to derive inherently interpretable reward functions for RL agents from natural language task descriptions. OCALM uses the extensive world-knowledge of LLMs while leveraging the object-centric nature common to many environments to derive reward functions focused on relational concepts, providing RL agents with the ability to derive policies from task descriptions.
Inverse Constitutional AI: Compressing Preferences into Principles
Jun 02, 2024
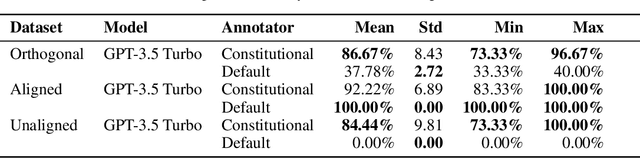
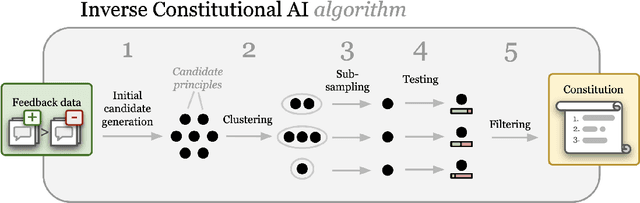
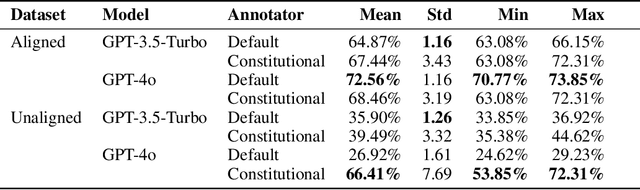
Feedback data plays an important role in fine-tuning and evaluating state-of-the-art AI models. Often pairwise text preferences are used: given two texts, human (or AI) annotators select the "better" one. Such feedback data is widely used to align models to human preferences (e.g., reinforcement learning from human feedback), or to rank models according to human preferences (e.g., Chatbot Arena). Despite its wide-spread use, prior work has demonstrated that human-annotated pairwise text preference data often exhibits unintended biases. For example, human annotators have been shown to prefer assertive over truthful texts in certain contexts. Models trained or evaluated on this data may implicitly encode these biases in a manner hard to identify. In this paper, we formulate the interpretation of existing pairwise text preference data as a compression task: the Inverse Constitutional AI (ICAI) problem. In constitutional AI, a set of principles (or constitution) is used to provide feedback and fine-tune AI models. The ICAI problem inverts this process: given a dataset of feedback, we aim to extract a constitution that best enables a large language model (LLM) to reconstruct the original annotations. We propose a corresponding initial ICAI algorithm and validate its generated constitutions quantitatively based on reconstructed annotations. Generated constitutions have many potential use-cases -- they may help identify undesirable biases, scale feedback to unseen data or assist with adapting LLMs to individual user preferences. We demonstrate our approach on a variety of datasets: (a) synthetic feedback datasets with known underlying principles; (b) the AlpacaEval dataset of cross-annotated human feedback; and (c) the crowdsourced Chatbot Arena data set. We release the code for our algorithm and experiments at https://github.com/rdnfn/icai .
A Survey of Reinforcement Learning from Human Feedback
Dec 22, 2023Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of Large Language Models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in targeting the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between machine agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.